Self-Serve Rate ≠ Correct Rate — The Gates a Customer-Service Agent Must Clear Before Launch | Agentic AI in Practice (XIII)

Thirteenth post in the Agentic AI in Practice series. The first twelve cover building the system right and staffing the org — L0-L3 grading, the 5 architecture decisions, fail-closed Critic, deploy-and-abandon, containment vs resolution, Skills vs knowledge base, dual-track testing, 3-tier intent cascade, five-layer API architecture, corpus-driven codebook evolution, a second agent as reviewer, the org chart is the real architecture. The fifth post settled which metric to track; this one picks up how many gates that metric has to clear before you launch and before you ramp — how to compute it, how to annotate it, how to auto-stop it. 中文版:自助率 ≠ 做对率:上线前到底卡哪几道闸.
"Should self-serve rate be 65 or 90?" — the review board asked the wrong question
Two weeks into the canary, the boss asked something that sounds perfectly reasonable: "What self-serve rate does this agent need to hit before we ramp it up — 65 or 90?"
I couldn't answer it directly. Not because the number wasn't ready — because the question crams two different things into one number.
I pulled the dashboard: self-serve rate 67%. Looks like it cleared the bar. But I also pulled one session from that week — the agent refunded a price-difference claim that should have gone to a human, and it refunded too much. What's that session's status on the dashboard? approved. It didn't escalate, it wasn't blocked, so it got counted in that 67% of "self-served."
A session that refunds the wrong amount still counts as a "self-serve success."
That 67% answers "how much volume did the AI catch." What the boss actually wanted to know is "of what it caught, how much did it get right." Two completely different axes, blurred into one percentage. This post takes apart four things: why launch readiness isn't one number, how 9 gates split across 3 layers, why there are only two hard red lines and why they auto-stop, and why correct rate has to be human-annotated — plus the 5 questions you can take to the next review board to ask a fake green checkmark straight through.
"65 or 90" is a false choice — it asks about two orthogonal axes
Let me put the conclusion on the table first: self-serve rate and correct rate are two orthogonal axes — one quantity, one quality. Report them separately, gate them on different lines.
- Self-serve rate = approved / sessions — the share of sessions where the AI didn't escalate and wasn't blocked. This is the quantity axis: "how much did it catch." It comes from flattening the
outcometag, and it carries zero judgment about whether the money was right or the wording was accurate. - Correct rate = of the sessions it caught, the share where the intent, the action, and the wording were all right. This is the quality axis: "of what it caught, how much was right." The machine can't compute it — a human has to judge it.
Stack the two axes and "65 or 90" answers itself: the AI catches ≥65% of the volume, AND the part it catches has a correct rate ≥90%. 65 is the floor on the quantity axis, 90 is the bar on the quality axis. You need both.
The most counterintuitive part is the reporting discipline: self-serve rate going up does not mean correct rate went up. Optimizing for "don't escalate the conversation" is easy — the LLM slips a plausible-looking fallback answer in, self-serve goes up, but you may well have "self-served" the wrong answers too. So those two numbers always go on two separate lines. Anyone who fuses them into one "overall pass rate" is manufacturing that 67% illusion.

Detection signal: when you hear any single-number report — "self-serve rate 95%," "automation rate 90%" — reply with: "Is that approved, or actually correct? Give me both numbers." Can't produce the second number, and the first one is just a "didn't-escalate rate."
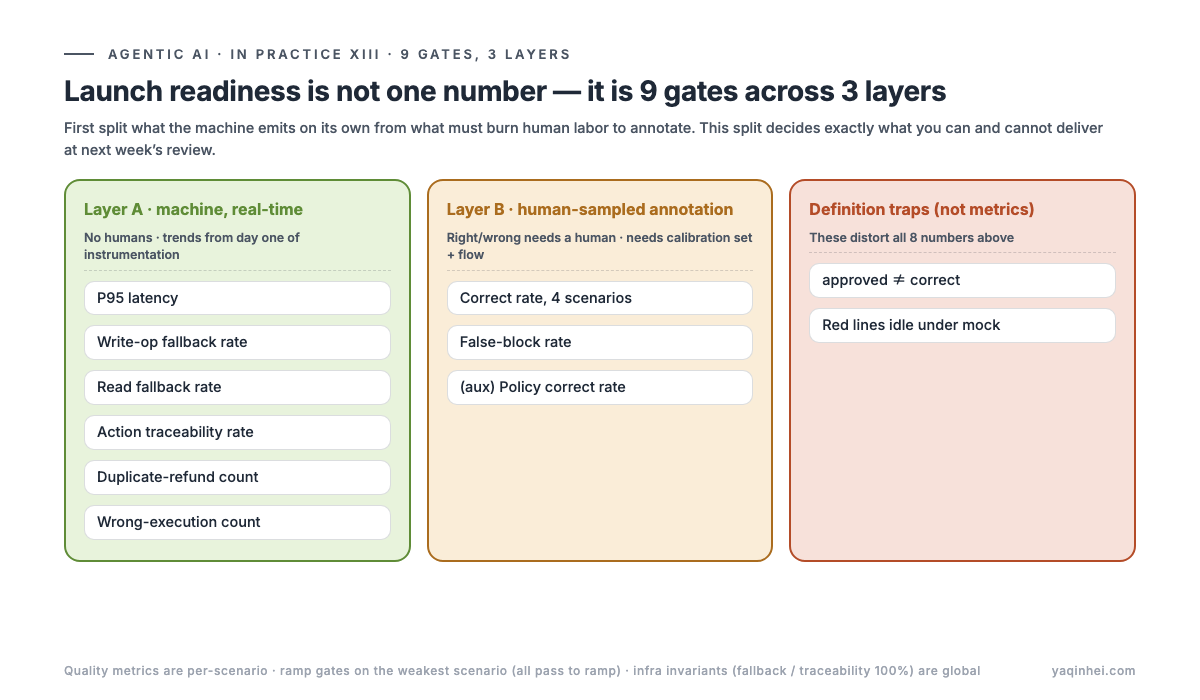
Launch readiness isn't one number — it's 9 gates across 3 layers
Passing one metric and shipping is squashing a multi-dimensional problem into one dimension — readiness has to be a layered gate table, and the first split is: which numbers the machine emits on its own, and which ones you have to burn human labor to annotate.
I split the 9 gates by "how it's computed" into three layers, and that split directly decides what you can and can't deliver at next week's review board:
- Layer A · machine, real-time (6 gates): P95 latency, write-op fallback rate, read fallback rate, action traceability rate, duplicate-refund count, wrong-execution count. These come straight out of the observability platform (Langfuse or similar), the write-op audit table (
agent_actions), and the OMS refund ledger. No humans needed. - Layer B · human-sampled annotation (2 gates + 1 aux): correct rate across the 4 scenarios, false-block rate, plus an auxiliary policy correct rate. The machine can only surface candidates; a human has to judge right from wrong.
- Two definition traps: ① approved ≠ correct (last section); ② red lines idle under mock (next section). These aren't metrics — they're the pits that make all 8 numbers above lie.
Why is this split the core of readiness? Because it cleanly separates "what's deliverable next week" from "what isn't": Layer A produces trends the day you wire up instrumentation; Layer B needs an annotation flow plus a calibration set before it produces anything. Mix them in one report and the boss thinks "all 9 have numbers" when half of them are machine-fudged placeholders.
One more easily-missed rule: quality metrics are read per-scenario. Ramping looks at the weakest scenario — all 4 canary scenarios have to pass before you ramp, not "the average passed." If any one scenario trips a red line, only that scenario's workflow stops, not the whole agent. Infra invariants (fallback rate, traceability rate must be 100%) are global; you only localize them to a scenario when something violates.
There are only two hard red lines — but tripping one auto-stops
Of the 9 gates, only two are "trip it and it stops, no meeting" hard red lines — wrong-execution = 0, duplicate refund = 0. Everything else is soft.
- Wrong-execution: the count of write operations that executed when they shouldn't have.
- Duplicate refund: the count of orders refunded ≥2 times.
These two aren't thresholds like "≥90%" — they're a cold = 0. Either one nonzero trips an automatic kill switch that stops that scenario's workflow (flip the scenario switch in thresholds.yaml), no waiting for the review board, no waiting for the next iteration. 1 catastrophic mis-fire = stop + postmortem now.
Why are only these two "hard"? Because they touch money and are irreversible. A correct rate that's 3 points low is an iteration problem, fixed next version; one extra wrong-execution is a financial-loss incident that already happened. The definition of a hard red line is "trip it and it stops" — otherwise the word "hard" is empty.
Here's the measurement trap almost every team steps in: duplicate refunds must be reconciled against the OMS ledger — you cannot use a self-join on agent_actions.
The worst duplicate refund looks like this: the agent refunds once → escalates → a human refunds again. agent_actions only logs the agent's own leg of the action; it can't see the human leg (the human's operation after handoff is never written back to that table). Self-join agent_actions to find duplicates and you'll never catch this "one machine and one human each refund once" real duplicate.
The right way: for each agent write operation, query that order's refund ledger in OMS (which holds both human and agent records) — has it already been refunded, is it over limit, is the amount or target wrong. The prevention-side dedup rule already does exactly this (reads that order's refund_history in OMS); the measurement side has to follow the same ledger, or prevention is stricter than measurement and you're just fooling yourself.
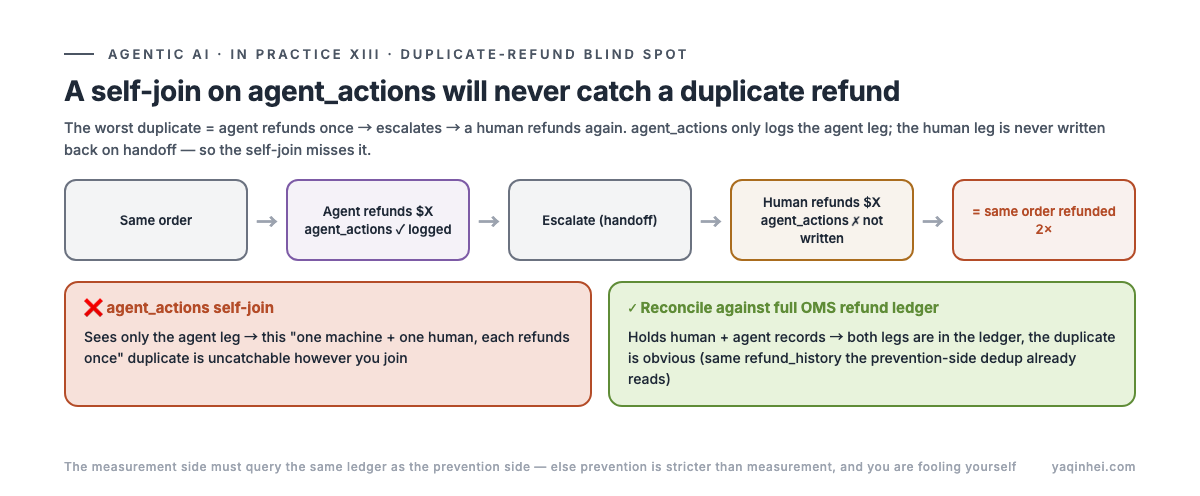
Detection signal: when you see "duplicate refunds = 0," ask first — "what did you reconcile against? The agent's own audit table, or the full OMS refund ledger?" If it's the former, that 0 is fake.
Red lines idle under mock — don't paint the whole thing green
Whether a red line is live depends on whether that scenario's real API is wired. A "= 0" computed under mock is a false sense of security.
A constant of the canary phase: some scenarios have switched to real APIs, some leaf nodes are still waiting on an API and temporarily mocked. At that point the red line's "live" status is split:
- Scenarios on real APIs → the red line is live and measurable (reconciling against a real refund ledger).
- Leaf nodes with no API wired → fail-closed to a human (this is a safe degrade, not idling). But note — the red line's "= 0" in this kind of scenario is held up by "everything fell back to a human so nothing executed," not verified by reconciliation.
The "= 0" in these two states is worlds apart in value. One is "tested, no mis-fire"; the other is "hasn't actually fired yet, so it hasn't mis-fired."
So the honest framing is: mark red-line status per scenario — for each scenario, spell out whether it's "live / measurable" or "fallback to human · pending API." Don't paint the whole red line one blanket green, and don't blanket-claim "it's all idling" either — report by each scenario's API wiring status.
Why is this so critical? Because handing the boss a blanket "red lines all green" means the day the API gets wired, you discover that scenario was never actually reconciled — and that day, with traffic already ramped up, is the worst possible time to find out.
Detection signal: at the review board, point at "red lines all green" and ask — "which scenarios are actually reconciled, and which are no-API, held up by fallback? Give me the per-scenario status." A green checkmark with no per-scenario list doesn't count.
Correct rate must be human-annotated — and inter-annotator agreement has to beat the gate's precision
Correct rate is the quality axis; the machine can't produce it. But before you burn human time annotating, you have to prove that "two people annotating the same session would label it the same" — otherwise your gate is gating annotation noise, not model quality.
Annotation isn't from scratch. The machine pre-fills: trace_id / session_id / scenario / outcome / the rule that fired / the raw conversation / the step chain / the linked agent_actions rows. The human only fills the judgment columns — was the intent right, was the action right, was the execution result right, was the wording compliant, was it end-to-end correct, should-it-have-executed, was the block decision right. 1–2 minutes per session.
The crux is inter-annotator agreement, held in three layers:
- Calibration set first. Before launch, business + QA double-annotate ~30 sessions and compute agreement (Cohen's κ). Agreement has to beat the gate's precision — if you're holding to "correct rate 90%, ±5%," the two annotators' agreement has to be ≥90%. Below that means the scorecard itself is ambiguous: fix the card before you open annotation.
- Mandatory double-annotation on red-line columns. Every "should-it-have-executed" and "was-the-block-right" is independently labeled by two people; disagreements are settled by business with a record.
- Sustained 10% double-annotation on the main pool. If agreement drops, stop and re-calibrate.
And a reporting discipline: reported error = sampling confidence interval + annotation disagreement, both counted. You report "correct rate 90%," the next version "88%" — that may be pure noise, not a regression. At low canary volume, report the rate and the absolute count together — "false-block 1/40" is far more honest than "2.5%."
Who annotates matters too: business leads on "execution result correct," "should-it-have-executed," "block decision" (they know policy, limits, brand rules); QA assists on "intent correct," "wording compliant" (against the rubric card and banned-word list, relatively objective); disagreements settled by business.
Detection signal: when you hear "correct rate 90%," ask — "what's the inter-annotator agreement? Did you run a calibration set?" Can't answer, and that 90% is probably one person's subjective score — a different annotator might land at 80%.
A soft metric falling short shouldn't trigger a blanket revert
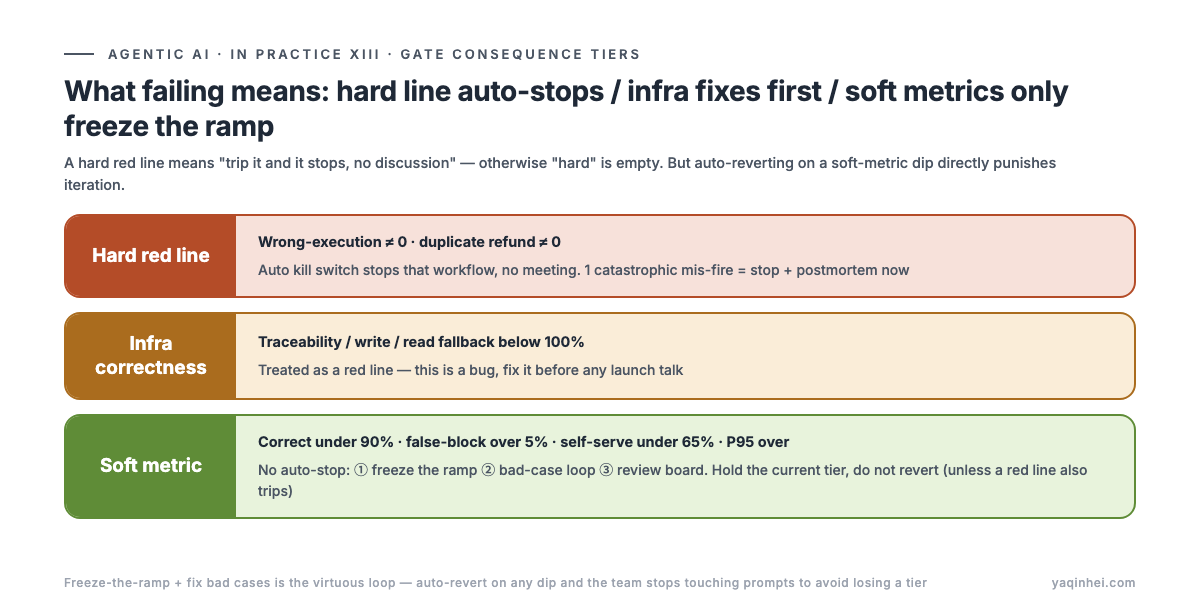
Gate consequences come in three tiers — hard red line auto-stops, infra correctness fixes first, soft metrics only freeze the ramp and don't revert.
| Tier | Metric | Consequence |
|---|---|---|
| Hard red line | wrong-execution ≠ 0 / duplicate refund ≠ 0 | auto kill switch stops that workflow, no meeting |
| Infra correctness | traceability / write fallback / read fallback below 100% | treated as a red line — this is a bug, fix it before any launch talk |
| Soft metric | correct rate under 90% / false-block over 5% / self-serve under 65% / P95 over | no auto-stop: ① freeze the ramp ② bad-case loop ③ review board. Hold the current tier, don't revert (unless a red line also trips) |
The logic behind the tiers: a hard red line is by definition "trip it and it stops, no discussion" — otherwise "hard" is empty; while a blanket revert on a soft metric falling short directly punishes iteration — the team stops touching prompts just to avoid losing a tier. Freeze-the-ramp + fix bad cases is the virtuous loop.
And a detail the boss will buy: the two fallback mechanisms run in opposite directions. A money-touching write op fails (critic timeout / tool failure / order-write failure) → fail-closed to a human; a read-type query fails (classification failure / retrieval failure) → fail-open with a safe fallback message, never fabricate, never an empty response, never an error page.
Telling the boss "money things fail to a human; lookup things fail to a safe fallback and never make things up" is both more accurate and more convincing than a blanket "100% to a human" — the latter is just false for read traffic, and if reads also "failed to a human" the human desk would drown instantly.
Low canary volume — get N to ≥50 per scenario before the first gate review
"Numbers next week" doesn't equal "launch next week" — without enough samples, the gate verdict is a coin flip.
The sampling principle in one line: full census on write ops, sample read traffic, always include exceptions.
- Write ops (financial actions) = full census. All 4 canary scenarios are write actions, reviewed session-by-session — red lines like wrong-execution = 0, duplicate = 0, false-block ≤5% can only ride on a full census; sampling would miss the one session.
- Read-type policy traffic = stratified sampling (random by intent × outcome).
- All blocked + escalated must be included — small volume, strongest signal; false-blocks and mis-escalations all hide here.
- Bad-case oversampling: anything tagged with a failed rule, high risk, high emotion, or low intent confidence goes in.
Minimum sample to clear a gate, by binomial 95% CI: 35 sessions per scenario → ±10%, 70 → ±7%, 140 → ±5%. Get each scenario to ≥50 before the first gate review, and every point estimate must come with a confidence interval. At real canary volume, accumulating enough samples may take 2–3 weeks.
So the one thing to make crystal clear at the review board: "What we deliver next week is a trend + real-time red-line status, not a launch verdict." Don't let "numbers next week" get heard as "launch next week." Same for ramping — after the first UAT round passes, testing + business + backend decide "ramp to the next tier" by the framework's data, not a jump straight to full.
5 questions that ask a green checkmark straight through
This post's detection tools, distilled to 5 lines you can read off at the review board:
- "Is that self-serve rate approved, or actually correct? Give me both numbers." — split the quantity and quality axes.
- "The wrong-execution and duplicate-refund red lines — are they actually reconciled now, or no-API and held up by fallback? Per scenario." — expose mock idling.
- "What did you reconcile duplicate refunds against — the agent's own table or the full OMS ledger?" — catch the self-join blind spot.
- "Who annotated the correct rate? What's the inter-annotator agreement? Did you run a calibration set?" — probe annotation noise.
- "Is next week a trend or a launch verdict? Is each scenario at N≥50, with confidence intervals?" — separate "numbers" from "launch."
What these 5 share: they force the reporter to unbundle one pretty fused number back into the multiple dimensions it actually has. Ask these 5 through and the review board won't get steered by a 67% "self-serve rate" again.
The next post takes apart a more painful engineering incident: 61 KB entries were edited, but the live index didn't update for 9 days, and a whole batch of test feedback all traced to one root cause — you thought you shipped, but you hadn't.
Send me the keyword "GATE KIT" and I'll send the Agent Launch-Readiness Gate self-check sheet: the 9-gate / 3-layer split + hard / soft / infra consequence tiers + annotation-calibration checklist + the 5 review-board questions, one page you can pin to the review-board whiteboard.
(Channels in the footer — X or email both work.)
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.