Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship | Agentic AI in Practice (II)
Second piece in the Agentic AI in Practice series. The first one — 28 'Agent' Projects, Only 5 Are Real — gave the L0-L3 grading framework: how to align language and see the current state. This one delivers on that piece's closing promise. Of the 5 real Agents on the list, how do you actually build a customer-service one? Why can't it be L3 autonomous? 中文版:5 个架构决策,决定你的客服 Agent 能不能上线.
A Refund the Autonomous Chain Pushed Through
A retail customer-service Agent project went into pilot. The vendor's proposal was branded "L3 multi-Agent autonomous planning" — the LLM reads the conversation, then decides on its own which system to query, which API to call, what action to take. The demo reel showed an Agent completing a refund flow entirely on its own. The business sponsor watched it, signed off on the pilot.
Week two. One real conversation: the user typed "I want a refund." The Agent's autonomous chain looked up the order, found it within the 7-day no-reason return window, and called the finance API. The refund posted. Clean.
Except the order was on the brand consignment model. The platform owns the storefront and fulfillment surface. The brand actually ships, and the platform doesn't own the inventory. A refund on a consignment order can't be issued directly. It's supposed to route through a manual flow where the platform advances the refund and later claws it back from the brand. Otherwise the books don't reconcile, and the brand keeps shipping on the original order.
Twenty-four hours later, a service blowup. The user had the refund. The brand was still chasing fulfillment. The post-mortem assumed the LLM had misread the policy. The truth is that it had no idea what tier this order belonged to.
Platform-owned versus brand consignment is a hidden field on the order table. A couple of lines in a business doc. This kind of invisible boundary doesn't get fed into an L3 autonomous planner by anyone — the planner walks the path it thinks is reasonable, all the way through, and then you pay for that "reasonable."
This isn't the LLM not being smart enough, and it isn't the vendor not trying hard enough. L3 autonomous planning, as a design pattern, just shouldn't be used for enterprise customer service.
If not L3, what then? Every customer-service Agent I've watched go live in the past year has been L2. But the term L2 itself hides a handful of architectural forks. Pick the wrong fork on one of them and the system either degrades into "a chatbot with an LLM bolted on," or inflates into a so-called L3 that never goes live.
Five forks. Five minutes each to think through. Below.
Why the Demo Reels Can't Ship
The conclusion first: an L2 customer-service Agent must use a deterministic workflow. The LLM fills in parameters at the nodes. It doesn't plan the path.
This is counter-intuitive. The L3 multi-Agent autonomous-collaboration segment in demos is always the most photogenic. One Agent summons another, picks the next step, reflects, rewrites the plan. The boss watches it and says we're doing that. But conversely — and this matters — across the customer-service Agent projects I've followed this past year, the ones that shipped reliably are all the boring deterministic workflows. The closer a design is to the L3 demo aesthetic, the more it falls over at launch. There are three reasons why.
Reversibility. The write operations a customer-service Agent performs — refunds, order edits, ticket creation, inventory adjustments, outbound SMS — are mostly irreversible, or very hard to claw back. Once the refund hits the user's card, clawing it back requires a separate reversal flow. A ticket, once created, has notified the responsible store, and undoing it still needs human follow-up. An SMS, once sent, has already set expectations in the user's head. Letting an LLM plan autonomously means letting something that hallucinates push the yes/no button. And the button has no undo. A deterministic workflow makes every possible path designed by humans and signed off by business experts, with a rule check and a Critic review at every write op. The L3 autonomous philosophy is that the LLM is smart enough to judge for itself. In enterprise customer service, the cost of betting on "smart enough" isn't user complaints. It's real money.
Accountability. After a customer-service project goes live, three groups will keep asking why it took the path it did. The customer asks: I didn't ask for a refund, why did you process one? Compliance asks: what's the approval chain for that refund? Internal post-mortems ask: where did the Agent misjudge on Tuesday's incident? A deterministic workflow has a complete execution log — what each intent node output, which edge was taken, what the Critic decided, which terminal action was run. Every step is locatable. An autonomous prompt chain can't answer. What the LLM thought inside is a black box, the path is different every time, and the post-mortem only has a conversation and an action. What happened in between, the LLM itself can't tell you. No accountability, no shipping. The vendor can hand-wave with "the model is a black box." The business sponsor can't repeat that line to the boss after an incident.
Observability. Autonomous takes a different path every run, which means the test set cannot cover all paths, which means production risk cannot be quantified. For scale: a customer-service Agent might span twenty intents, six external systems, and five kinds of write operations. Under a deterministic workflow, the full set of possible paths, branches included, numbers in the low hundreds. Every one can be tested. You can give the boss a "92% test coverage" number before launch with ground truth behind it. Under autonomous, theoretical paths are combinatorial — the LLM can branch differently at every node. Your tests can only cover conversations that have already happened. Conversations that haven't happened yet are all blind spots. Autonomous can't give you the coverage number.
Translate those three reasons into architecture, and L2 looks like this. A fixed workflow state machine, designed by humans and reviewed by business experts. At each node, the LLM decides which edge to take and fills in the necessary parameters. The next node, terminate, or escalate to human. The LLM doesn't plan the path. It just answers "which way from here?"
Concrete example: how should "refund eligibility" be handled? The wrong way is to make refund eligibility one prompt, feed the LLM the whole user conversation plus every available API description, and let it decide what to query, what to judge, and what API to call. The right way is to make refund eligibility a fixed six-step workflow: identify order tier (platform-owned, brand consignment, or transfer), pull logistics status, check the time window and item state, pick the execution path (direct refund, human approval, or create ticket), run the Critic second-pass review, then execute and write to the audit trail. At each step the LLM only answers that step's question. The next edge is decided by the current step's output plus business rules, not by LLM free-form planning. In the opening incident, the LLM skipped step one. Under a deterministic workflow, that skip is structurally impossible, because the LLM had no freedom to plan the path.
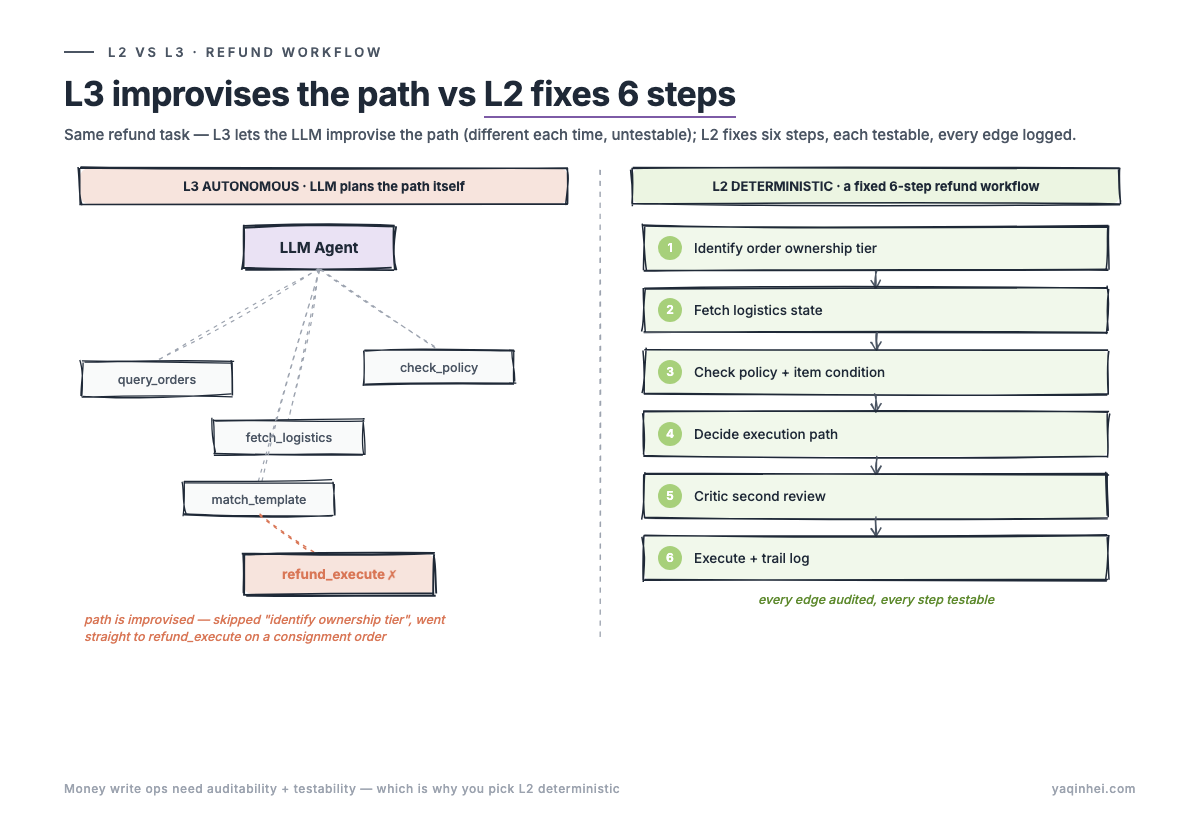
A few patterns that, in my experience, mean the architecture is autonomous in disguise. The vendor saying "our Agent plans the path autonomously" — ask them to enumerate the path list. If they can't, it's autonomous. The deliverable being "100 conversation samples" instead of "every workflow edge is covered" — same thing, since 80% of post-launch conversations will be untested. The architecture diagram showing only a vague "LLM Router + Tool Calls" box rather than a state machine — likely L3 autonomous behind a clean diagram. A real L2 architecture can draw the workflow state machine for each intent.
So inside the deterministic workflow, the core nodes — intent classification, API routing, policy judgment, write operations, evaluation — how should each be designed? Four more decisions.
Three Tiers for an Intent
Intent classification is the workflow's first node. The user says something, you have to know what they want before routing. Get this step wrong, and the other four decisions are wasted.
Pure rules are too brittle. Pure LLM is too expensive. A three-tier fallback is the only viable engineering path. This is the shared choice of every customer-service Agent I've seen that actually shipped.
The architecture is straightforward. User input first hits rules. Rules cover standard phrasing — "I want to return," "where's my package," "I want to check my order." High-frequency, stable wording. Fast, accurate, and cheap, covering 60-70% of input. What misses falls to embedding semantic recall, which catches rephrasings — "I don't want this thing anymore" is a refund intent that rules miss; embedding maps it into the same semantic neighborhood as the canonical phrasing. What still misses falls to LLM classification, which handles long-tail and compound expressions — "the shoes I bought yesterday don't fit, the store associate said I could return but now I want to swap for a different color, can I?" — long, multi-intent sentences only the LLM can untangle. If even the LLM isn't confident, the conversation escalates to a human. Don't force a guess. The cost of guessing wrong is much higher than the cost of escalating one step earlier.
The trade-offs are mechanical. Each tier up costs roughly 10x more — rules cost essentially nothing, embedding costs cents per call, LLM costs tens of cents at current frontier-model pricing. Each tier up adds 10-15% accuracy by covering the long tail the previous tier missed. Each tier up adds 200-500ms of latency, because embedding is an order of magnitude slower than rules and LLM is another order of magnitude slower than embedding. The essence of three-tier fallback is to use the cheapest tier to handle 80%, the next-cheapest to handle 15%, the most expensive to backstop 5%, and escalate the rest. Any design that inverts the ratio either blows up cost, breaks under concurrency, or fails to reach accuracy.
A note on the intent taxonomy itself. Three-tier fallback is the technical architecture. The intent taxonomy — how many intents your service has, how each is defined — isn't designed once. It's an iterative loop from production corpus to codebook. In a real project, the taxonomy might evolve from v1's 36 intents to v2's 48, every expansion driven by line data showing "this class of question keeps showing up in unknown." That's a piece of its own; not unpacking it here.
Patterns to watch for. A vendor saying "we use LLM classification directly, simple and reliable" — cost will spiral and latency won't hold under any real concurrency. A vendor saying "we use 100% rule matching, completely controllable" — once the taxonomy crosses about 30 intents, rules will conflict, maintenance cost is exponential, and the engineering team will revolt inside six months.
A deeper piece on three-tier tuning is coming — confidence thresholds, caching, second-pass recall on unknowns, rolling out new intents without disturbing existing ones.
The Critic, and Why It Must Fail Closed
Write operations are the place where things go wrong. Refunds, order edits, ticket creation, inventory deductions, outbound SMS — anything that changes business state and produces irreversible consequences. After an L2 customer-service Agent goes live, every incident traces back to this category of node. Other nodes failing means awkward output and user complaints. Write op failures mean real money and social-media blowup.
The conclusion has two parts. LLM decisions on write operations must have a Critic second-pass review. And the Critic must escalate to a human on timeout or error, not pass through. The second part is the counter-intuitive one, and the place most teams get it backwards.
Why a single LLM executing write ops doesn't work, in three classic problems. It hallucinates — confidently outputs a wrong judgment. "This qualifies for 7-day no-reason return," forgetting the item has been used. It doesn't see the full context — context windows are finite, and critical info from earlier in a long conversation gets pushed out. And it doesn't admit uncertainty — low-confidence output looks identical to high-confidence output, and you can't tell from the output alone whether "this one is shaky." A second LLM to proofread — one proposes, the other reviews — is the origin of the Critic. Essentially, AIs cross-checking each other.
The interesting question is what happens when the Critic itself runs into trouble. Three situations: timeout, error, low confidence. In all three, the Critic didn't give a clean verdict. Do you pass through or block?
The fail-open design says: the first LLM judged "approve refund," the Critic timed out or errored, and since the Critic failed anyway, you pass through the first judgment. Refund goes out. The fail-closed design says: the first LLM judged "approve refund," the Critic ran, and on timeout or error or low confidence — any one of them — you escalate to a human. Only if the Critic explicitly returns "approved" with high confidence do you execute.
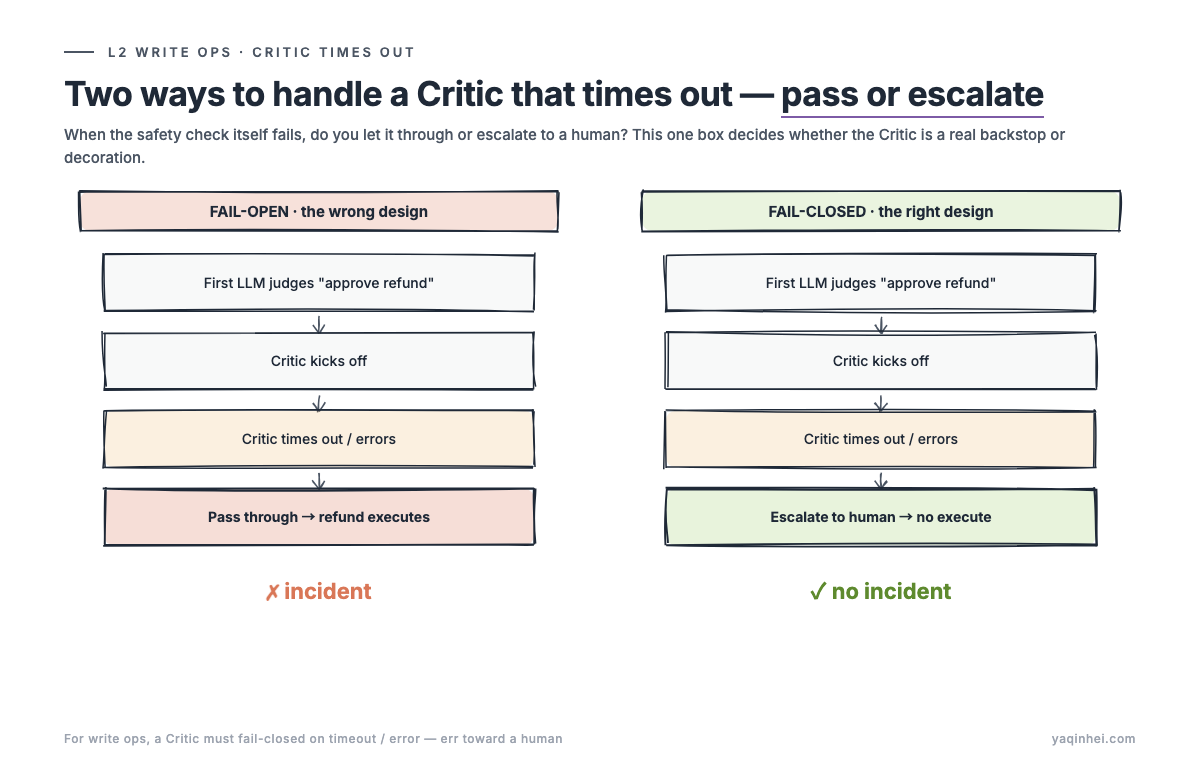
The fail-open design is always wrong, for reasons that take three layers to unpack. Timeout usually means LLM service degradation: high model load, network jitter, upstream rate-limiting. Output quality wasn't guaranteed in the first place. Exactly the moment you most need review — passed through instead. Error usually means input anomaly: dirty data, a corner case, unseen characters or structure in the conversation. Exactly the moment you most want a Critic to look — skipped instead. And pass-through turns the backstop into self-deception. The business sponsor thinks the Critic is protecting them. In reality the Critic often did nothing — but nobody knows until the incident.
"Write operations should fail closed" is thirty years of financial-industry experience. There's no need to reinvent it for LLM systems.
The natural objection: won't the human escalation rate go up? Yes. Short term up, long term down. Early phase, a fail-closed Critic will escalate roughly 30% of write operations to humans. That 30% is exactly the valuable feedback — see which scenarios the Critic is uneasy about, feed it back into workflow design, prompt revisions, threshold tuning. Once stable, the human escalation rate drops below 5%. And the automation rate actually exceeds a fail-open design's, because fail-open designs hit incidents early, get pulled offline for rework, and never recover. Don't compromise this for "automation-rate KPI looks better" in the early phase. That's one of the most common ways I've seen customer-service Agent projects die.
Two patterns that mean something's wrong. The vendor showcasing "95% automation rate" — ask what happens if the Critic times out. If the answer is "auto pass-through," post-launch incidents are guaranteed. And any design where the first LLM executes a write op without Critic review — that's L3 autonomous, not L2. Any refund or money-touching action without a Critic cannot ship in enterprise customer service.
A deeper piece on Critic design is coming, with prompt phrasing, threshold setting, human-escalation queue management, when to use a rules-Critic versus an LLM-Critic, and how to eval the Critic itself. It's the single most counter-intuitive piece in the series.
Twenty-Five APIs Should Look Like Five Tools
A customer-service Agent isn't a standalone system. It plugs into the enterprise's existing SaaS ecosystem. Order lookup, order edit, refund, ticket creation, logistics tracking, e-commerce platform data. Every system pre-exists. Every system has its own APIs.
The scale matters. A typical enterprise customer-service Agent touches six major systems. The order system has 5-8 APIs for lookup, edit, and refund. The ticket system has 3-5 APIs. The logistics system has 4-6 APIs for tracking, anomaly detection, and re-ship. The e-commerce platforms — there are usually several, each with 4-6 APIs. The finance system has 3-4. Data and risk has another 2-3. The total is 25 or more.
Stuff them all into the prompt and hand to the LLM and you get token blowup plus a wrong-tool rate north of 30%. Write a routing rule per intent and you get a maintenance dump three months out. The only path that holds is to wrap the APIs into business capabilities — a Tool Layer. The top layer exposes a single capability called "refund." The lower layer wraps "identify tier → pull logistics → call finance," three to five APIs deep. The LLM sees only the refund tool; it doesn't see the underlying APIs.
A minimal contract: process_refund takes order_id and reason_code, returns success along with optional ticket_id and escalation_reason. Internally it routes to the platform-owned path, the brand consignment path, or the transfer path. The LLM doesn't know there are three distinct paths, and doesn't need to. It sees one tool with two input parameters. Clear, stable, testable. When the lower layer changes — new e-commerce platform, transfer process rework, finance system upgrade — the upper tool contract doesn't change. That's the real value of the Tool Layer.
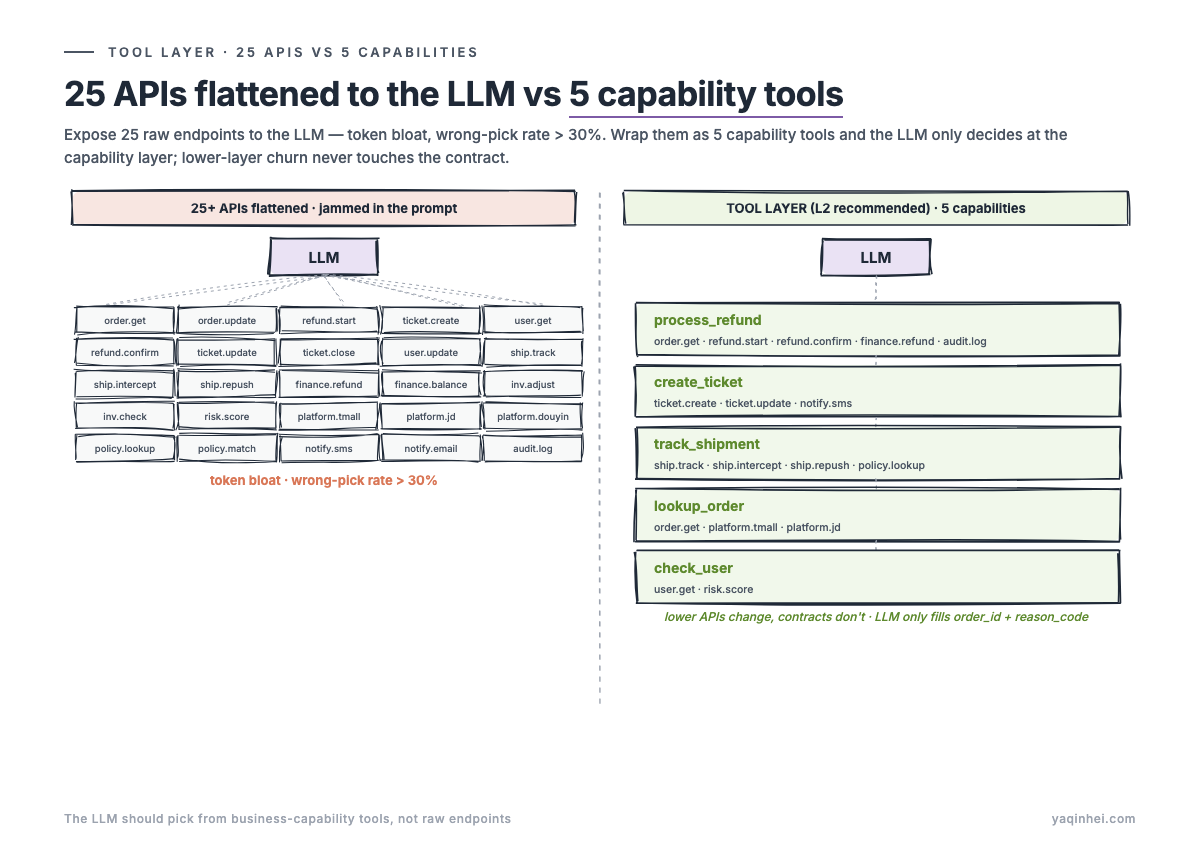
Each lower-layer path is implemented in rule-based code, not LLM, maintained by backend engineers. The LLM is only responsible for "when process_refund shows up, fill in order_id and reason_code correctly." It does that reliably.
Two patterns to watch. The vendor's architecture diagram showing all APIs to the LLM — token costs spiral, every new intent requires prompt re-tuning, and the whole system is fragile. The integration proposal saying "we wrote 50 routing rules" — three months later rules will conflict, no one will maintain it, and the next team will throw it out and rewrite.
A deeper piece on Tool Layer contracts is coming, with idempotency, error codes, timeout retry, gradual rollout, upstream-downstream contract alignment, and how 25 APIs collapse into 8-10 tools.
Why Catch Rate Is a Vanity Metric
Get the previous four decisions right, get the last one wrong, and what the boss sees is still "we spent Agent money, no different from the old chatbot."
The chatbot-era metric is catch rate: the user's question was recognized by the machine, and some answer was given or some flow was walked. Typically 80-85%. The Agent-era north star can only be resolution rate: the user's question was actually solved, no escalation, no repeat question, no follow-up within 24 hours. The launch target is 60-70%.
The gap is enormous, because "the machine gave an answer" is not the same as "the problem got solved." Two real scenes. A user asks "where's my package," and the bot replies "your package is out for delivery, please wait." Caught, not resolved, the user still escalates. A user asks "I want to return," the bot replies "please upload the order screenshot," and after the upload the bot replies "press 1 to return, 2 to exchange." Caught twice, still not resolved, the user is already yelling.
An 80% catch rate can have a 30% resolution rate. That gap is the line between chatbot and Agent. Every Agent project that uses catch rate as the KPI ends with a confused boss: "looks the same as before."
The metric stack should be one north star and a small set of sub-metrics. North star is resolution rate. Sub-metrics expose where the system is failing: intent classification accuracy (the output of decision two), policy judgment accuracy (decision one), write-op accuracy (decision three), escalation rate (the Critic trigger rate), and repeat-question rate (the user re-asking because they didn't get an answer). Sub-metrics are for the engineering team to locate problems — resolution rate dropped 5%, look at which sub-metric dropped, map back to which of the five decisions is hurting. The north star is for the business sponsor to read effects — one number. When it doesn't move, the question isn't the sub-metrics, it's "is the workflow not designed right."
Two patterns. A vendor reporting "95% catch rate" — ask for the resolution rate. No answer means no north star. The project will produce a confused boss post-launch. And a KPI designed as "automation rate" or "bot share" targets saving labor, not solving problems. The two often diverge. To save labor, the flow is designed to make it hard for users to escalate. The user is less satisfied, but the KPI looks great.
A deeper piece on the full migration from catch rate to resolution rate walks through the four denominator tricks that manufacture "98% CSAT," the three-signal-AND definition of true resolution, and the five questions to ask at the next vendor review.
Five Decisions, One Cheat Sheet
The whole thing fits on one page. Use it next time you review a vendor proposal, run an internal pitch, or report to the boss. Listen, and check off.
| # | Decision | Shortcut path | Recommended (L2) | Can't-ship path |
|---|---|---|---|---|
| 1 | Workflow | All rules / decision tree | Deterministic + LLM fills params | LLM plans path autonomously |
| 2 | Intent classification | Pure rules | 3-tier fallback | Pure LLM |
| 3 | Write-op backstop | Direct execution | Fail-closed Critic | LLM executes autonomously |
| 4 | API integration | Routing rules everywhere | Tool Layer wrapper | All APIs flattened to LLM |
| 5 | Evaluation metric | Catch rate | Resolution rate + sub-metrics | Automation rate / bot share |
This past year, I've seen the pattern hold. Get 1-2 right and the gap in overall effect is large; the boss sees no clear improvement. Get 4-5 right and the system ships, with resolution rate hitting 60%+. Get all 5 wrong and either L2 degrades into L1 — "a chatbot with an LLM copywriter bolted on" — or it gets inflated as L3 and never goes live. The gap in Agent delivery isn't in model selection. It's in these five decisions.
Print this. Save it to your phone. Next time you review a vendor proposal or run an internal pitch, listen to the architecture pitch with one hand and check the boxes with the other. Five minutes, and you can give a clear judgment: can this ship, where does the resolution ceiling land, does it need rework? Ten thousand times faster than "watch the full deck and digest for two weeks."
The Toolkit
If you want to use the cheat sheet directly in your next review — without digging up this article every time — I packaged a PDF kit for readers who got this far. Send me the keyword "L2 KIT" and I'll send the pack: the 5-Decision Cheat Sheet as five square cards, a 15-item red-flag self-check list, and a one-page A3 decision tree for L2 vs L3 selection. Two years of customer-service Agent work, distilled into judgment tools.
(Channels in the footer — X or email both work.)
What's Next in This Series
Each of the five decisions deserves its own piece.
Already published deep dives:
- Piece three: Why a 70% Critic Beats a 95% Critic — A Fail-Closed Design Deep Dive (decision 3 deep dive)
- Piece four: Deploy and Abandon — The Costliest Misconception in AI Agent Projects (the six post-launch operational environments)
The cadence ahead: AI system testing (dual-track architecture, seven quality dimensions); three-tier intent cascade tuning (decision two); wiring an LLM into enterprise SaaS (decision four); catch rate versus resolution rate migration (decision five). If your team is building a customer-service Agent, every one will land.
If this piece was useful, pass it to the people on your team who need it — especially the ones currently reviewing customer-service Agent vendor proposals.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.