Corpus Drives Codebook — Why Your Intent Taxonomy Is Stuck at 60% and How It Evolves from 36 to 48 | Agentic AI in Practice (X)
Tenth post in the Agentic AI in Practice series. The first nine cover whether a plan can ship, how to keep it from rotting after launch, the north-star metric, brain / hand separation, how to test, threshold tuning, and how to layer APIs — L0-L3 grading, the 5 architecture decisions, fail-closed Critic, deploy-and-abandon, containment vs resolution, Skills vs knowledge base, dual-track testing, 3-tier intent cascade, five-layer API architecture. Post VIII tuned the classifier; this one fixes the taxonomy itself — without which a tuned classifier still tops out at 60%. 中文版:你以为定义好的意图够用了——1102 条样本里有 800 条说『不』.
"Unknown rate 40%" is almost never a classifier problem
A monthly review meeting. Ops drops a dashboard screenshot in the channel — 1,102 user messages, intent-classification accuracy 59.44%, unknown rate 40%.
The business side reacts reflexively: "Can we just add an LLM fallback for that 40%?"
The vendor proposes the same thing: lower the LLM-fallback threshold from 0.85 to 0.7, push more unknowns into LLM classification. A week later, in the follow-up — accuracy rose from 59% to 67%, but unknown rate barely budged. The business side walks through the still-unknown samples one by one: "the LLM still got these 200 wrong. Why?"
After auditing a few dozen samples the engineer admits a thing nobody wants to hear — the real problem with these 200 isn't that the classifier missed them; it's that the codebook has no slot for them in the first place:
- "When will my return request be approved?" — classifier called it
refund_status(money). It's actuallyreturn_status(goods-side review). The definition card never wrote down how to disambiguate, so 50/50 either way. - "Don't process my refund, just ship it instead" — classifier called it
order_cancel. It's actually "cancel my after-sales request" — a missing intent that the codebook never defined. Nothing the classifier could have done. - "If you won't refund me I'll call the consumer-protection bureau" — classifier called it
complaint_service. Business rule: any mention of external regulatory channels routes tohuman_transferimmediately. That rule was tribal knowledge, never written into the codebook, so the classifier had no way to know.
Every time I have seen "unknown rate high" in a customer-service Agent project, my first instinct is to check the classifier. 80% of the time the real issue is the codebook (the intent taxonomy) itself. The codebook is the intent system; the classifier is just its implementation. Miss an intent in the codebook and no classifier can find it. Leave boundaries fuzzy and no classifier can disambiguate. Use inconsistent naming and labels won't match rules and accuracy hits a hard ceiling.
This post unpacks three things.
First, how to use real user corpus to reverse-engineer the gaps in your codebook — four systematic confusion patterns, each with concrete samples.
Second, before the business side asks you to "add an intent," run it through the four-quadrant test — most "missing intents" are not intents at all. They're parameter slots, dialogue states, or multimodal signals.
Third, a 3-round diff evolution process — the actual 36 → 45 → 46 → 48 path, with who approved each round, what got added, what got rejected, and how many downstream files a single rename touched.
Next time someone in a review meeting says "unknown rate is high, let's add LLM fallback," you can put the rules from this post on the table — a high unknown rate is almost never a classifier problem. It's a systemic gap in the codebook.
4 systematic confusion patterns surfaced from 1102 samples
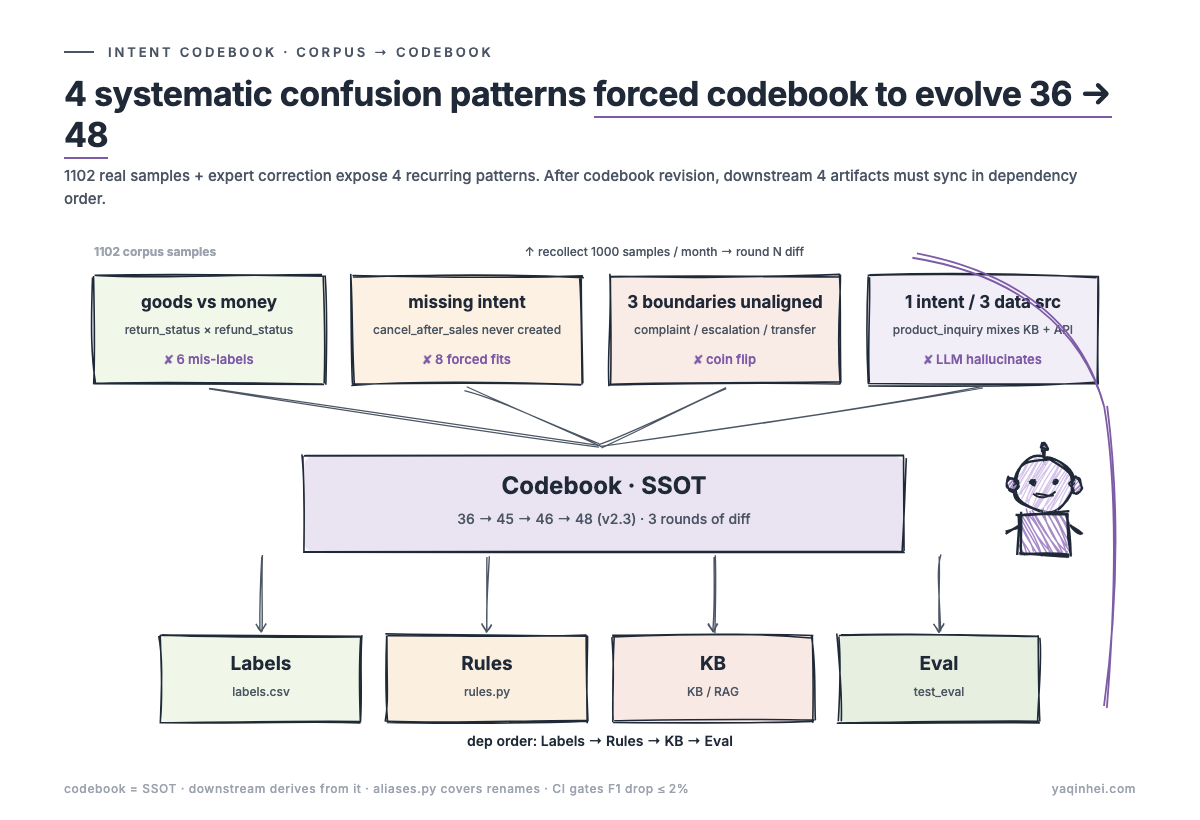
Verdict first: codebook gaps cannot be found by desk brainstorming. You must label real corpus, have business experts apply expert corrections, then count which labels keep getting corrected to the same wrong thing. After 3 months of accumulation, the 1,102-sample batch made 4 patterns blindingly obvious.
Pattern 1 — users do not distinguish "goods" from "money"; the taxonomy does
return_status (return-review progress) and refund_status (money-arrival progress) are two distinct intents — different backend APIs, different SLA calculations.
But users do not think that way. The expert-correction pass surfaced 6 cases where a "review progress" question was mislabeled as refund_status:
- "When will my return request go through?" — first read says "money," but "go through" = review approval
- "This after-sales review is taking forever" — review is goods-side
- "I returned the package, you signed for it, where's my money?" — this one is
refund_status; the focus has moved from "can it be returned" to "when does the money arrive"
Root cause isn't the classifier; it's that the codebook buried the boundary. The original definition card had one-sentence definitions for both intents — no easily-confused negative examples, no rule for "when users don't distinguish, how do you?"
Fix (codebook layer, not classifier layer):
return_status:
definition: user asking about the goods-side review progress of a return ticket
positives : "where is the review at?" "when does it approve?" "review speed"
negatives (→ refund_status): "where is my money?" "short-paid" "refund didn't arrive"
boundary rule: when both goods and money are mentioned, look at the focal point —
"i returned it, where is my money?" → focus is money → refund_status
"the return was approved, where's my money?" → focus is review → return_status
After this section was added to the v2 definition card, inter-annotator agreement went from 78% to 91% — not because labelers got smarter, but because the codebook wrote the rule down.
Pattern 2 — a missing intent, with 8 samples forced into adjacent intents
order_cancel and cancel_order_exec together collected 8 expert-corrected samples — none of them were actually about cancelling an order, all of them were "cancel my submitted return / refund request":
- "How do I take back the refund request?"
- "Forget the return, how do I cancel?"
- "I clicked by accident, didn't actually want to apply for the refund"
- "I demand you cancel the return ticket"
- "Can I cancel my return application?"
- "Let me just cancel the after-sales request first"
- "Don't process the refund, just ship it"
- "My order hasn't shipped yet, I accidentally clicked the return button, how do I cancel?"
The taxonomy had no "cancel after-sales request" intent. Experts stuffed them into order_cancel, labelers labeled them in, the classifier learned "cancel + after-sales wording → order_cancel" — and then when a real "cancel this order" arrived in production, it misclassified.
This is the textbook signal for using corpus to reverse-engineer codebook gaps: a single sample looks normal, but the same missing intent showing up 8 times in a row is a systemic signal. Fix: add cancel_after_sales as a new intent, route to the ticket system's "cancel after-sales" action. Taxonomy goes from 45 → 46 because of this one observation.
But spotting this signal requires one specific practice: the labeled sample set must include an expert_correct_intent column. Labelers labeling mapped_intent alone is not enough — you need business experts to do a second pass with "if this sample doesn't belong to its mapped label, which adjacent label is it closest to?" — then count the high-frequency 'adjacent intents' in the expert-correction column. Same wrong-adjacent label appearing N times = a codebook gap.
Pattern 3 — three intents with no aligned boundary; labelers flipping coins
complaint_service, escalation, and human_transfer look close in business-side language, and labelers were essentially guessing:
- "Your after-sales is awful, fix this now" —
complaint_service?escalation? - "I'll be emailing your Shanghai HQ executives" — does "executives" mean escalation or service complaint?
- "If you won't refund me, the consumer-protection bureau is waiting" — this must be
human_transfer, but labelers tagged it ascomplaint_service - "Connect me to after-sales" —
escalationorhuman_transfer?
The business side eventually aligned on three one-line definitions:
complaint_service: user expresses dissatisfaction with current service, no explicit ask to switch
escalation : explicit request for "manager / supervisor / lead / person in charge"
human_transfer : explicit "talk to a human" OR mention of "consumer-protection bureau / law / court / media"
Key rule: ANY mention of external regulatory channels (regulator / court / media)
→ human_transfer, IMMEDIATELY. Do NOT route via complaint_service slow path.
After this got written into codebook v2.1, inter-annotator agreement stabilized. The point isn't how many new intents got added — it's that the "key rule" got pinned down in the codebook instead of living in 30 labelers' heads individually. If it lives in their heads, the next cohort of labelers will lose it.
Pattern 4 — one intent mixing three data sources; routing cannot be optimized
product_inquiry (general product Q&A), under expert review, turned out to mix three fundamentally different query types:
① "what material is this shoe?" → static spec, KB static answer (< 10ms)
② "what's the size chart?" → static attribute, KB static answer (< 10ms)
③ "is size 42 still in stock?" → dynamic stock, real-time API call (500ms+, time-sensitive)
The three differ on:
- Data source (knowledge base vs live API)
- Latency (10ms vs 500ms)
- Cost of being wrong (wrong spec = customer annoyed; wrong stock = customer makes a wasted trip to the store)
- Time validity (specs are permanent; stock expires by the minute)
The cost of mixing them is worse than the data-source mismatch — when the RAG pipeline sees a "stock" query, if retrieval routes to KB instead of the live stock API, the LLM hallucinates "yes, in stock". This was caught in production by the business team and traced back to the codebook: product_inquiry was poorly defined from day one.
Fix: split into 3 independent intents at the 45-intent revision:
product_inquiry(kept, narrowed to static spec/attribute only)stock_availability(new, live stock API)restock_notify(new, subscription action)
The business experts proposed the split themselves — not engineering pushing it through. The evidence was that "is X in stock" and "what material" were handled by completely different agent scripts in their day-to-day workflow. Lumping them into one intent was a design error.
What the 4 patterns have in common: none of them is "classifier missed it." All of them are "the classifier is facing a broken taxonomy where labels, rules, and knowledge never aligned in the first place." By the time you're tuning classifier thresholds, you're already too late.
"Intent ≠ what the user said" — the four-quadrant test
Before the business side says "add an intent," run it through 4 lines. Of 15 "missing intent" suggestions in one review batch, only 8 should actually be added after the four-quadrant pass — 3 had no business case, 4 were not "intents" at all.
The four-quadrant test is 4 lines:
different backend action → must be a separate intent
only parameter differs → add a slot, do NOT create an intent
only phrasing differs → it's training data for the same intent
only dialogue state differs → goes in the state machine, NOT the taxonomy
Each rule maps to a class of common "pseudo-missing intents."
"This is a slot, not an intent"
Business: "Please support a 'send Alipay account' intent."
Through the quadrant: the backend action is the same as the existing "refund workflow" — read the user-supplied Alipay account, write to ticket, trigger reconciliation. Only the parameter differs. Add one alipay_account slot to the refund workflow.
Correct: add a slot, don't create an intent.
"This is a dialogue state, not an intent"
Business: "Please support a 'will take photo later' intent — user says 'wait, let me find the shoes and take a photo.'"
Through the quadrant: when the user says "take photo later," the Agent doesn't need a new backend action — it just needs to suspend the conversation, wait for the next message (which should be the image), then resume the complaint_quality flow.
Correct: add an awaiting_photo state to the state machine, don't create an intent. If you put this in the taxonomy, the classifier has to learn "user message = take photo later" → return delayed_photo — but what does the Agent do with that intent? Nothing. Pure no-op.
"This is a multimodal signal, not an intent"
Business: "Please support a 'send image' intent."
Through the quadrant: sending an image is itself an attachment event the frontend can detect — message.attachments != null. Auto-route to the complaint_quality flow (most image-sending scenarios) on detection.
Correct: frontend auto-routes, don't create an intent. Asking the LLM classifier to judge "is this user message a photo send" is using a cannon on a mosquito — 5 lines of JS in the frontend handles it.
"This business doesn't exist"
Business: "Please support 'identity verification' / 'cleaning service' / 'support hours' intents."
Before the quadrant, ask: "Do you actually offer this line of business?" —
- Identity verification: the company has no cross-border / customs business → reject
- Cleaning service: the company doesn't offer this value-added service → reject
- Support hours: belongs in the FAQ KB, no intent needed
Business stakeholders won't always remember to apply this filter themselves — they see related questions in legacy customer-service logs and want to add the intent. Engineering's job is to confirm business existence before deciding whether the intent should be built.
One-line summary
An "intent" is the smallest classification unit the system needs to act on differently.
It is not "every phrase the user might say."
It is not "every topic that has ever appeared in customer-service logs."
It is not "every user utterance the business side feels should be recognized."
Run this one line over 15 "missing intent" candidates and 8 will survive as genuinely new intents.
36 → 45 → 46 → 48 — the 3-round diff path
The intent taxonomy is not designed once. It's a loop — corpus → revision → downstream sync → regression test → next corpus collection. Three rounds get you to a stable state.
Round 1 (36 → 45) — gaps surfaced by corpus collection
The first round is driven by the expert-correction statistics from the 1,102-sample batch. Business proposed 15 new intents and 3 merge/split questions. After engineering ran the four-quadrant test:
| Action | Count | Detail |
|---|---|---|
| Add | 9 | wrong_item / missing_item / return_address / shipping_address_change / price_inquiry / stock_availability / third_party_auth / edit_return_number / restock_notify |
| Rename | 2 | invoice → invoice_request; invoice_register → invoice_auto_issue |
| Reject | 3 | real_name_auth (no such business); cleaning_service (no such service); service_hours (goes in FAQ) |
| Defer | 4 | send_image (multimodal signal); take_photo_later (dialogue state); send_alipay (slot); shipping_reminder (overlaps existing intent) |
Every "reject" and "defer" gets a written explanation back to the business side — this document itself is the alignment material, not an engineering-internal memo.
This first round is the highest-information round in the codebook's evolution. Teams that have never collected real corpus designed their taxonomy from imagination — it will not match the real distribution. Only after running real corpus through one cycle do you learn which intents are missing, which boundaries are fuzzy, and which intents shouldn't exist at all.
Round 2 (45 → 46) — the P2 gap surfaced by the expert addendum
After round 1 ships, business experts review another ~180 samples across 33 intents in the v2 definition card's addendum. Counting the high-frequency adjacent-intent errors surfaces the same gap appearing 8 times — that's cancel_after_sales from the previous section.
Round 2 only adds one intent, but that one intent is extremely expensive to discover. Without the second-round expert review, the gap would not be caught until 3 months post-launch when users complain "I can't cancel my after-sales request" — by which point downstream labels / rules / KB / eval are fully built against the 45-intent taxonomy.
Lesson: corpus collection is not a one-shot. First-round collection finds "the obvious gaps"; the non-obvious gaps require multiple rounds of expert review + expert-correction frequency stats. Suggested cadence:
- Pre-launch: ≥ 1000 samples + 1 expert pass → round 1 diff
- Month 1 post-launch: another 1000 samples + 2nd expert pass → round 2 diff
- Month 3 post-launch: another 1000 + 3rd → round 3 diff
After 3 rounds the taxonomy is largely stable; subsequent changes are low-frequency local edits (1-2 intent adds/removes per quarter).
Round 3 (46 → 48) — merge needs that surface after launch
Round 3's source isn't new intents — it's the reverse — once the taxonomy is large enough, certain intents should merge into the same sub_topic in the LLM Router (the v2 architecture from post VIII section 8):
product_inquiry → sub_topic: product
product_compare → sub_topic: product
product_recommend → sub_topic: product
brand_specific → sub_topic: product
price_inquiry → sub_topic: product
↑ 5 legacy intents → 1 sub_topic
complaint_quality → sub_topic: complaint
complaint_service → sub_topic: complaint
↑ 2 legacy intents → 1 sub_topic
Plus 3 new sub_topics for boundary cases the original codebook missed: payment / order_cancel / defect (clearance / B-grade defect products).
The core of this round isn't changing codebook labels — it's aligning the codebook with the downstream LLM Router's sub_topic system. Intent labels are for labelers and the classifier; sub_topics are for the routing layer and the ticket system. Both must exist, with explicit mapping. End state: v2.3 = 48 legacy intents + 23 sub_topics, bridged by a LEGACY_INTENT_TO_ROUTE table.
Three rounds of diff and the taxonomy is finally stable.
The renaming avalanche — one rename touches 10 files
The expensive part of taxonomy evolution isn't adding intents; it's renaming. One rename touches 10 files. Skip one of them and production silently degrades — "the classifier got it right but the answer fell back" or "the classifier missed it but the old name is still in the logs."
For the simplest rename in round 1 — invoice → invoice_request — the downstream sync list:
□ intent definition card v2 (.docx) ← business-readable source
□ intent/codebook.json ← code-readable SSOT
□ intent/aliases.py ← old-name → new-name compat layer
□ intent/rules.py ← rule-engine keywords
□ intent/semantic.py + anchors.json ← embedding anchor vectors
□ intent/classifier.py ← LLM few-shot prompt
□ knowledge-base/<intent>_v1.0.md ← corresponding KB file rename + content
□ tests/test_eval_intent.py ← evaluation expected labels
□ internal plan / strategy docs ← doc sync
□ team MEMORY / onboarding docs ← legacy 36 → 48
Ten files. Skip one:
- Miss
rules.py→ rule always hits the oldinvoice, classifier output disagrees with codebook - Miss
anchors.json→ embedding anchors are labeled with the old intent, similarity correct but label wrong - Miss the KB file rename → KB parser can't find
invoice_request_v1.0.md, retrieval fails, answers fall back - Miss
test_eval_intent→ evaluation expects old label, classifier outputs new, false negatives — looks like "accuracy dropped"
Skip any one of them and the taxonomy is silently degrading in production. So the codebook evolution flow must put this list in the PR checklist as a hard block — all 10 files updated or the PR doesn't merge.
Legacy data compatibility is a separate problem. The production database has thousands of historical labels using the old invoice; the labeler guide now says invoice_request. How do these two coexist?
Answer: aliases.py covers it.
INTENT_ALIASES = {
# old_name → new_name
"invoice": "invoice_request",
"invoice_register": "invoice_auto_issue",
"nvoice_request": "invoice_request", # labeler manual-entry typo
"shipping_wrong": "wrong_item", # old rule misnaming
}
def resolve_intent(raw_name: str) -> str:
return INTENT_ALIASES.get(raw_name, raw_name)
Downstream code reads via resolve_intent(raw_name); legacy data migrates transparently.
This file is 10 lines to write and saves a week of reconciliation per rename. Without aliases.py, every rename triggers a DB migration script to update all historical labels, downstream queries miss during migration, and on Monday morning the business side files an escalation when the daily report shows "the intent distribution has all shifted."
SSOT + downstream 4 artifacts in dependency order
The codebook is the Single Source of Truth. Downstream — labels / rules / knowledge / evaluation — must update in dependency order. Out of order = rework, where one piece changes and another doesn't, and regression tests cannot tell "is this real degradation or just incomplete sync?"
Dependency order (each step depends on the previous):
① Labels → label-schema + labeler-guide update
└─ Already-labeled samples: auto-migrate via aliases
└─ New intents : add ≥30 samples / intent
② Rules → intent/rules.py
└─ first-match-wins: action intents MUST go before policy intents
└─ "execute signals" ("for me/process/execute") prevent mis-matches
③ KB → knowledge-base/<intent>_v1.0.md
└─ New intents need their own KB file or answers fall back
└─ File names use underscores, NOT hyphens (KB parser depends on it)
④ Eval → tests/test_eval_intent.py + eval grid
└─ ≥ 5 evaluation samples per new intent
└─ ≥ 10 evaluation samples per legacy intent
Why this order:
- Labels before rules: the rule engine extracts high-frequency keywords from labeled samples; no labels = no keywords
- Rules before KB: KB retrieval is intent-gated; if rules don't hit, KB doesn't get retrieved
- KB before eval: evaluation tests end-to-end (intent + retrieval + generation); without KB you can only measure intent accuracy, and the testing ROI tanks
Going out of order: change rules without supplementing labels and rule coverage stagnates; change eval expectations without updating KB and regression false negatives flood the dashboard, burning team energy on "real problem or sync gap?"
Regression gating (encode into CI, hard block):
| Metric | Threshold |
|---|---|
| Legacy intent F1 avg drop | ≤ 2% |
| New intent recall | ≥ 60% |
unknown rate | does not rise |
| Unit tests | all green (except known expected failures) |
Fail any of these → roll back the codebook revision and re-review. This gate must be hard. The historical mistake: "let's ship even though legacy intent F1 dropped 5%, we'll catch up later." A month later user-satisfaction reviews surface that high-frequency historical questions answer worse than before, and by the time you get back to it there's three weeks of dirty data piled up.
3 things to do this week + 5 questions to ask vendors
3 things to do this week:
- Collect ≥ 1000 real samples from the last month and run an expert-correction pass (each sample: original label + "if not this label, the closest adjacent label"). Count high-frequency 'adjacent-intent' errors in the expert-correction column — same adjacent error appearing ≥ 5 times = a codebook-gap signal.
- Run all "missing intent" requests from the business side through the four-quadrant test — different backend action → intent; only parameter differs → slot; only phrasing differs → training data; only state differs → state machine. Three lines filter out half the pseudo-missing-intent requests.
- Stand up an
aliases.py(if it doesn't exist) — list every rename / typo / old rule's intent name from the last 6 months. The next rename won't require trawling the database for historical labels.
5 questions to ask the vendor / supplier in a review meeting:
- "How has your intent taxonomy evolved?" — being able to produce 3 rounds of diff documentation (what was added when, what was rejected, why) is the sign of a real corpus → codebook process. Producing only a "final intent list" usually means it was designed from imagination.
- "What's the post-launch unknown rate?" — month 1 post-launch with unknown rate still ≥ 20% demands a root cause. If the answer is "add some LLM fallback," the team is not looking in the codebook.
- "Where is your codebook? Word doc or JSON? What's the sync mechanism?" — if the codebook lives only in a Word file with downstream code hard-coding intent labels, the next rename will silently desync. You need to see
codebook.json+ analiases.pycompatibility layer to call it mature. - "Does your labeled-sample schema have an
expert_correct_intentcolumn?" — without that column, you cannot reverse-engineer codebook gaps from corpus, and the taxonomy will only get messier over time. - "What's the legacy-intent F1-drop regression gate? Hard-blocked in CI?" — answers of ≥ 5%, or "no hard block, we'll review and decide," are failing answers. ≤ 2% + CI hard block is the floor.
Next review meeting, write these 5 questions on a single page and lead with them. A vendor who can't answer 3 of them has a basically nonexistent codebook-evolution process — the rest of their engineering can be perfectly polished and 3 months in production the unknown rate will still be 40%.
Tenth post in Agentic AI in Practice — unpacking codebook evolution rather than classifier threshold tuning. Post VIII covered the classifier-side 3-tier cascade thresholds; this one covers the codebook. Use them together: the classifier determines whether you can hit the ceiling the codebook designed; the codebook determines what that ceiling is. Get both right and intent-classification accuracy stabilizes from 60% to 90%+.
Send me the keyword "INTENT-CARD" and I'll send the pack: (1) intent definition card v2 template (with easily-confused negatives + boundary-rule fields), (2) four-quadrant test checklist (for the 30-minute review meeting), (3)
codebook.jsonschema +aliases.pycompatibility-layer minimum viable version, (4) 3-round diff review-meeting template.
(Channels in the footer — X or email both work.)
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.