The Org Chart Is the Real Architecture Diagram — 90% of Stalled Agent Projects Aren't a Tech Problem | Agentic AI in Practice (XII)

Twelfth post in the Agentic AI in Practice series. The first eleven are all about building the system right — L0-L3 grading, the 5 architecture decisions, fail-closed Critic, deploy-and-abandon, containment vs resolution, Skills vs knowledge base, dual-track testing, 3-tier intent cascade, five-layer API architecture, corpus-driven codebook evolution, a second agent as reviewer. This one tackles the diagram outside the system — why a project can get all the tech right and still freeze, and exactly which parts of the org structure an enterprise Agent forces you to move. 中文版:组织架构图才是真正的架构图.
Annotation delivered, baseline built, scenarios shipped — then the project stalled for 3 weeks
A retail customer-service Agent project I led had a stretch of inexplicable stall last year.
The tech side was actually smooth: four scenarios with workflow + Critic shipped, 1,102 intent-annotation samples delivered, a 310-row eval baseline built, intent routing covering 36 intents. Every part was in place.
Then the project stopped for three weeks. One line on the progress board stayed grey the whole time: knowledge base review (364 high-frequency entries) — not started.
The tech team asked the business team: when do we start reviewing? The business team asked the tech team: isn't that your job? I went and pulled the RACI sheet. The owner field for "knowledge base review" held one word: TBD. Further down — "CS Ops Lead," "Knowledge Owner," "annotation reviewer" — five roles, all TBD.
Here's the bottom line up front: when an Agent landing fails, the tech problem ranks third. First is no one owns it; second is the KPI doesn't land on a person. Across the CS Agent projects I've run, the times a project froze on tech were far fewer than the times something simply had no owner and the whole pipeline stopped dead.
Those three weeks weren't tech debt. They were org debt. This post settles that account — in your Agent project, the org chart is more likely to be the freeze point than the system diagram is.
An Agent isn't a system you ship — it's an organ you feed every day
The org rhythm of a traditional software project is familiar to everyone: build → test → launch → maintain. Maintenance is passive — nobody touches it without an incident, and when one hits, you firefight. Project ends, team disbands, on to the next.
Run an Agent project on that rhythm and it dies.
The reason: an Agent's launch day isn't the finish line, it's the start of metabolism:
- Knowledge changes daily — one revision to the return policy and hundreds of docs need re-review, expiry, replacement
- Intents grow weekly — users ask phrasings the training set never saw; a codebook climbing from 36 to 48 intents is normal (the whole of post 10 is about this)
- Models iterate monthly — swap a model, edit a prompt, tune a threshold, and each time you re-run eval and re-canary
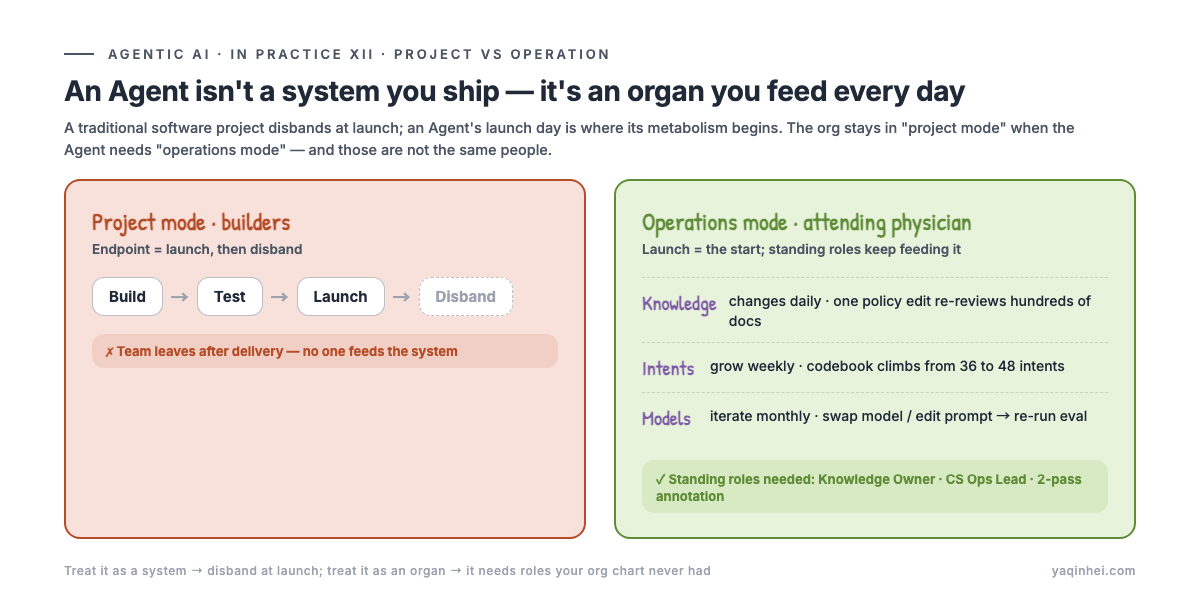
Treat the Agent as a system and you disband the team at launch; treat it as an organ and you find it needs roles that didn't exist anywhere on the kickoff org chart. Project mode governs "get it built," operations mode governs "keep it alive" — those are not the same people, let alone the same accountability.
That's why the tech can be fully correct and the project still stalls: the people who built the system delivered and left, and the roles that feed the system were never appointed.
Landing an enterprise Agent takes at least 3 new roles
Not three headcount — three roles whose responsibility lands on a specific name. In my three-week-stall project, the root cause was exactly these three roles all parked at "TBD."
Role 1: Knowledge Owner.
They own the entire knowledge base lifecycle: draft → annotate → review → live → expire. They also own one easily-overlooked thing — keeping the knowledge base's field enums (sub_topic, channel) in sync with the tech team's codebook.
What happens without this role? The most expensive case I've seen: when a batch of knowledge was loaded, 51% of entries couldn't be ingested for a missing intent field. The knowledge wasn't wrong — nobody had defined the rule "these fields are mandatory before ingestion," let alone enforced it in the UI. Of 100 reviewed entries, only 61 actually made it into the system.
Detection signal: Ask "in your knowledge base, who has the authority to mark a doc 'expired'?" — if they can't name a specific person, there's no Knowledge Owner.
Role 2: CS Ops Lead.
They own bad-case triage, escalation routing, UAT execution, canary review. Past 50% canary, at least 5 bad cases a day need someone to look at them — is it the intent that's wrong? the knowledge? the generation? Someone has to make that call.
The direct cause of my project's stall was that this role had no one in the seat. In the retro notes I wrote one line: "The CS Ops Lead must have an owner; this is one of the root causes of the current stall." The annotation samples were delivered, but with no one downstream to receive them, the whole pipeline just stopped.
Detection signal: Ask "last week's bad cases — who called the meeting, who assigned ownership?" — if the answer is "we all look at it together," nobody looks at it.
Role 3: Annotation engineer + two-pass review.
First pass does classification (intent / channel / tier); second pass is the CS supervisor's business-correctness sign-off. Two gates, because classified-right isn't business-right — a technical annotator can tell "this is a return intent," but can't judge "whether this return policy actually holds on the Douyin channel."
Without two passes, taxonomy fights break out: the same kind of question gets labeled intent A by one annotator and intent B by another, and the downstream model learns contradictory signals.
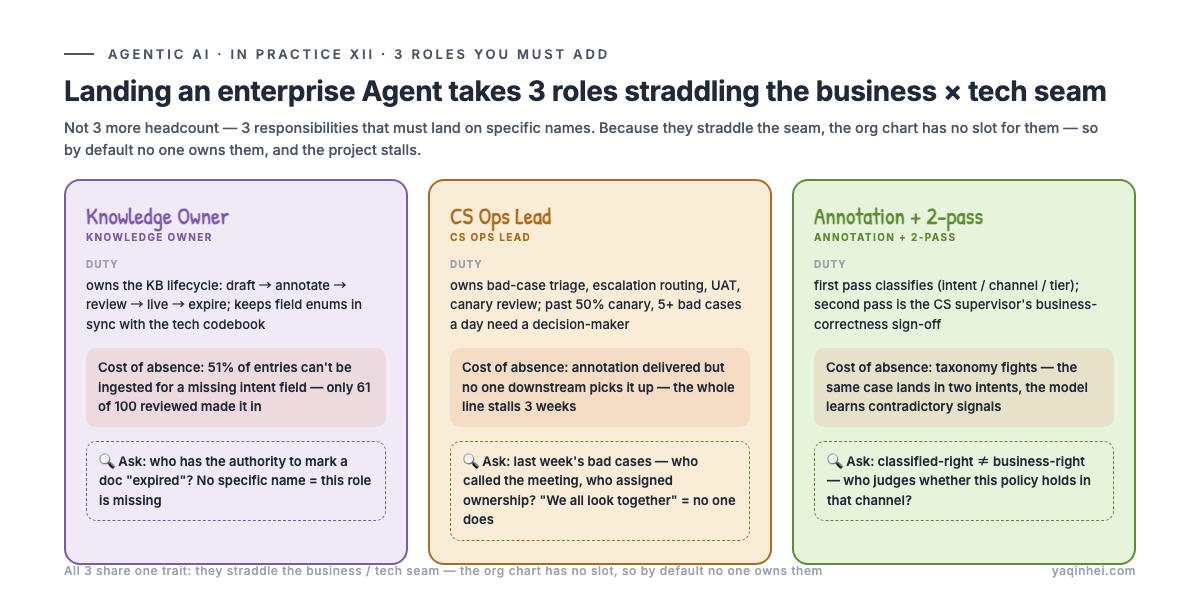
These three roles share one thing: they all straddle the seam between "business" and "tech." Precisely because they straddle the seam, the traditional org chart has no slot for them — so by default no one claims them, and the project stalls.
One ownership table: who owns what — if you can't write it, you haven't thought it through
The three roles answer "who feeds it," but the thing that actually causes daily fights is "who does this one thing belong to." Fill in the table below at kickoff — the cells you can't fill are exactly where the future stall lives.
| Asset / responsibility | SoT (sole authority) owner | Consumer / collaborator | The boundary that fights most |
|---|---|---|---|
| Intent codebook (intent + action enums) | Tech team | Knowledge center syncs the enums | Add a new intent — who changes first, who follows |
| KB content + versions + approval | Knowledge center | Agent holds a read-only local copy | KB changes — how long until the Agent syncs |
| Embedding (vectorization) | Knowledge center, centrally | Agent consumes directly, no re-embed | Who does the embedding — two sides, two vector spaces that don't line up |
| Retrieval API (POST /kb/search) | Knowledge center | Agent calls it | Who guarantees the SLA (P99 under 500ms, 99.9% uptime) |
| Bad-case adjudication | CS Ops Lead | Tech team + QA assist | Is it a wrong business rule or a system bug |
| Financial-loss / compliance response | Tech Lead + security | Escalates to business owner → boss | How fast must P1 respond (2 hours), who can pull it offline |
The deepest pit I fell into in this table is row three: who does the embedding. The knowledge center and the Agent each embedded their own copy, the two vector spaces didn't line up, retrieval results made no sense, and it took a long while to trace it to "the same sentence encoded by two models into two different vectors." We finally nailed one rule: the knowledge center is SoT, all doc and query embeddings happen on the knowledge-center side, and the Agent reads only — never re-embeds.
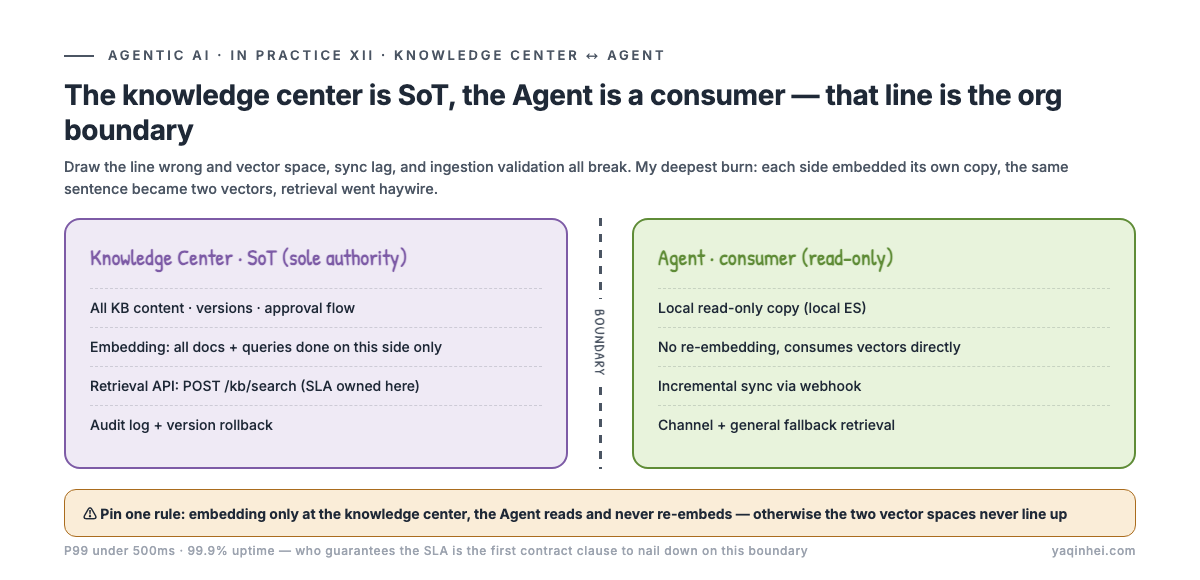
The essence of this table is translating "architecture decisions" into "people decisions." A system architecture diagram draws how data flows; the ownership table draws who's accountable for each segment of that flow. The former is never missing; the latter is missing in almost every project — and the latter is what actually freezes a project.
A KPI that doesn't land on a person makes "automation rate" an empty phrase
Roles aligned, ownership aligned, and there's still one last piece: who carries the KPI.
When I pulled that project's RACI sheet, the thing that stung most wasn't the "TBD" roles — it was the KPI column. All blank:
| KPI | Owner | Approver |
|---|---|---|
| Automated resolution rate above 65% | ☐ TBD | ☐ TBD |
| 25,000 staff-hours saved per year | ☐ TBD | ☐ TBD |
| Zero financial loss | ☐ TBD | ☐ TBD |
| CSAT does not drop | ☐ TBD | ☐ TBD |
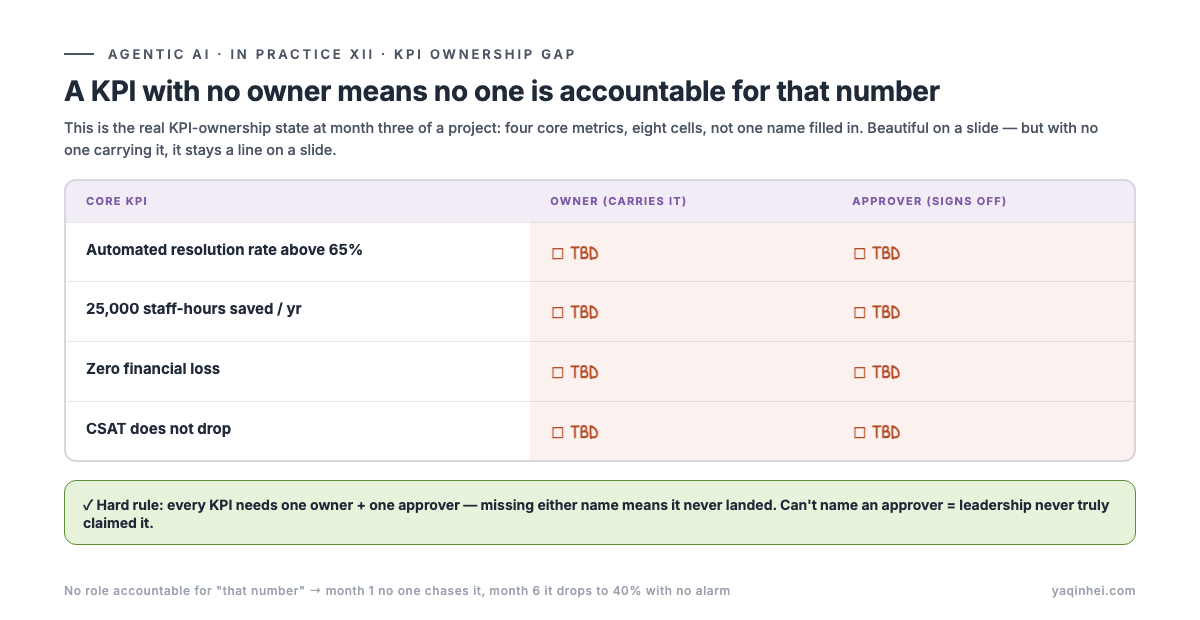
A KPI with no owner means no one is accountable for that number. "Automated resolution rate 65%" looks great on a slide, but with no one carrying it, it stays a line on a slide — month one nobody chases whether it hit, month six it drops to 40% and no alarm goes off.
This and post 4, "deploy and abandon" are two symptoms of the same disease: that post is about "no role accountable for the system still being alive in 6 months"; this one is about "no role accountable for that number." Five roles, five goals, and not one goal pinned to "long-term system health" — that's not a tech problem, it's a hole in the accountability structure.
There's a hard standard for landing a KPI on a person: every KPI must have one owner (who carries the number) and one approver (who signs off on it) — two names, and missing either one means it didn't land. If you can't name an approver, leadership itself hasn't truly claimed that KPI.
Force the org gaps out at the kickoff: 5 questions + an escalation chain
Everything above is diagnosis; this section gives you tools you can use directly at your next kickoff. Org gaps are best exposed at kickoff, not discovered after three weeks of stall post-launch.
The kickoff 5 (any one that can't name a specific person = a gap):
- In the knowledge base, who has the authority to mark a doc expired? (→ is there a Knowledge Owner)
- The first bad case after launch — who calls the meeting, who assigns ownership? (→ is there a CS Ops Lead)
- To add a new intent, do tech or the knowledge center change first, and who follows? (→ is codebook ownership clear)
- The automated resolution rate KPI — who carries it, who signs off? (→ did the KPI land on a person)
- On a mistaken refund, who has the authority to pull the Agent offline within 2 hours? (→ is the escalation chain wired)
Question 5 connects to the escalation chain. An Agent moves money and can push wrong policies, so the escalation chain has to be drawn before launch, not improvised when the incident hits:
Execution layer (blocked > 1 day)
→ Owner / Tech Lead (blocked > 3 days or cross-team)
→ Project coordinator
→ Business owner (needs a business decision or resources)
→ Boss (needs strategy or cross-department coordination)
Financial-loss / compliance special channel:
P1 (loss risk / compliance warning) → within 2 hours, Tech Lead + security
P2 (potential issue) → 1 business day, Tech Lead
It comes with a meeting cadence — nothing elaborate, three standing meetings are enough to hold the operations rhythm: weekly business review (business owner + CS + tech align on rules), weekly bad-case review (CS + tech + QA look at last week's misses), biweekly leadership sync (the people carrying KPIs reconcile on a cadence).
These aren't bureaucratic process — they're the drive shaft you bolt onto "continuous feeding." Without these meetings, the three new roles each do their own thing and it stalls anyway.
Five self-checks — is your Agent project quietly stalling
Take the five below to your next retro and run through them. Any one a yes, and org debt is already accruing:
- Knowledge base review / maintenance can't be tied to a specific owner's name — no Knowledge Owner
- Post-launch bad cases have no fixed person to convene and assign ownership — no CS Ops Lead
- Intent / knowledge field enums are maintained twice, by tech and business, and don't line up — no ownership boundary
- The owner / approver columns for core KPIs are blank, or say "the project team" — KPI didn't land on a person
- You can't draw the escalation chain; "who can pull the Agent offline when it breaks" has no answer — no governance structure
Zero yeses out of five and you've cleared this gate. Three or more yeses and no matter how right the tech is, the project will probably freeze at some "no one's responsible" link.
In closing: draw the people diagram right before the system diagram
We're all good at drawing system architecture diagrams — how data flows, how the API layers, how the Critic backstops; the first eleven posts cut it fine. But where an Agent landing actually freezes is often not on that diagram.
The freeze point is on a different diagram: who owns the knowledge base, who carries the automation rate, who can pull it offline, who reviews bad cases. If you can't draw that diagram, no matter how beautifully the system is built, it'll stop for three weeks on some "TBD" cell.
The org chart is the real architecture diagram. Because an Agent isn't a system that ends at launch — it's an organ that needs standing roles to feed it every day, and an organ needs not a builder but an attending physician. Drawing the people diagram right at kickoff decides the project's life or death earlier than drawing the system diagram right does.
At your next kickoff, don't rush to the tech plan. Put that ownership table on the table first, and go cell by cell: this one — who owns it?
Get the toolkit
If you want to put this post's tools to work at your next kickoff, I've packaged a PDF toolkit:
Send me the keyword "ORG KIT" and I'll send the pack:
- RACI + ownership table template (one A4 page, fill it cell by cell at kickoff)
- Responsibility sheets for the 3 new roles (Knowledge Owner / CS Ops Lead / two-pass annotation, drop straight into a JD)
- Kickoff 5 questions + escalation chain template (with P1/P2 response windows, draw it down hard)
The judgment tools I scraped out of a year of projects, for you, the reader who made it this far.
(Channels in the footer — X or email both work.)
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.