I Audited 28 'AI Agent' Projects — Only 5 Were Real Agents

Agentic AI in Practice · Part 1 | A 4-level agent-autonomy test (L0–L3) for telling real Agents from fake ones
中文版在此:28 个所谓 Agent 项目,只有 5 个是真的。 The previous series (Retail Enterprise Agentic AI Handbook) covered "how to take one customer-service Agent from zero to one." This series goes one level up — "how to decide what should be built as an Agent at all, and to what degree." Align the language first; then talk about shipping.
Opening: Is This List Sitting On Your Desk Too?
Is this list sitting on your desk too —
Smart customer service, smart replenishment, smart slow-mover alerts, smart scheduling, smart store ops, smart membership, smart content… 28 candidate projects, every name prefixed with "smart" or "Agent." Your boss says "we're doing this this year," and you don't know which ones are real, which are vapor, and certainly not how to report back to him.
Budget, headcount, KPIs — all waiting on this list getting approved.
If this scene isn't unfamiliar, read on — some of these "things called AI Agents" are probably on your list:
- Smart meeting notes? Fixed pipeline: record → transcribe → LLM summarizes → push to attendees. The LLM only does work at the "summarize" step.
- Display-compliance detection? Computer vision recognizing shelf-layout rules. Doesn't need an LLM at all.
- After-sales customer service? Look up orders, look up logistics, judge policy, decide refund-or-escalate — the LLM makes decisions at multiple points.
Run the whole list of 28 through it, and only 5 genuinely need to be built as Agents; 19 don't need the LLM to make any autonomous decisions at all; 4 sit in between.
If you approve that list as-is, 70% of the budget goes into "automation with an LLM bolted on" — but everyone reports it as Agent work, sets Agent KPIs, evaluates against Agent expectations. On delivery day, everyone's confused: we spent all this money, and how is this different from the old chatbot?
This isn't the LLM's fault, and it isn't the team's fault. It's that everyone's "Agent" means something completely different.
This article gives you a 4-level ruler — after reading it, you can judge any AI project in 5 minutes: is it an Agent, or something else? Then spend 20 more minutes and sort your 28 candidates into clean buckets.
The short answer: the four levels of AI agent autonomy (L0–L3)
Before the 28-project audit, here's the ruler itself — the four levels of AI agent autonomy, one line each:
- L0 — Rule automation: a fixed if-then decision tree with preset branches and no LLM.
- L1 — LLM-enhanced: the LLM generates or understands content, but the pipeline is fixed and the LLM makes no autonomous decisions.
- L2 — Tool-calling Agent: the LLM decides which tool to call, when to call it, and how to use the result — the first level with genuine autonomous decisions.
- L3 — Multi-step orchestration Agent: multiple agents run a plan → execute → reflect loop to handle open-ended tasks.
The single test that places any system: at runtime, does the LLM dynamically choose the next action based on context? No → L0/L1. Yes, at one or more nodes → L2. Yes, with a reflection loop on top → L3.
The rest of this article is that test, applied: three worked examples, a 5-question self-check, and all 28 candidate projects graded.
1. Why the Word "Agent" Is Killing Projects
The opening said "everyone's Agent means something different" — how, specifically?
| Role | What "Agent" means in their mouth |
|---|---|
| Sales / solution vendors | Anything that sells an LLM capability — from Q&A to multimodal assistants, all "Agent" |
| Business executives | Something "smarter than the chatbot" — solves problems, runs the business autonomously |
| Engineers | Strictly: an LLM system that plans autonomously, calls tools, executes in a loop |
| Media / blogs | Any LLM + business-scenario combo can be written up as "XX Agent" |
Four groups, each saying "Agent," each thinking they're being clear. Until they sit down at the same conference table —
The boss says "we're doing Agents this year," sales pulls out an "Agent solution" quote, the engineer hears the quote and thinks "isn't this just intent classification + RAG," and on delivery the business side finds "no different from the old chatbot."
Every party is wasting money, and none of them know how.
The crash-and-burns I've seen this past year take different shapes, same root cause — no shared language to describe what they're actually doing. Three typical kinds —
Crash 1: Selling a template engine as an Agent
I saw a retail brand buy a "membership operations Agent" — it supposedly decided autonomously which members to message, when, and with what content. Six-month retro: "decide which members" is a rules engine, "when to send" is a trigger, and the LLM's actual contribution was "swapping templated SMS for more conversational personalized copy."
That's a textbook L1 system — the LLM embedded at one node of a fixed pipeline. But it was sold as an L2 Agent, paid for at Agent prices, hung with Agent KPIs ("autonomous decisions," "smart outreach"), and the effect gap got measured not against "no LLM" but against "the resolution rate an autonomous Agent ought to have."
Money spent, nobody buying it.
Crash 2: Building an L2 scenario as L1
Another kind goes the opposite direction. A team built after-sales customer service — inherently an L2 scenario where the LLM needs to make decisions at several nodes: intent judgment, order lookup, policy check, route decision. But to "guarantee controllability," the team swapped every LLM decision for rules: intent via rule matching, which API via decision tree, refund conditions via if-else, LLM only generates the final reply.
Result: resolution rate stuck at 30% (industry baseline 60-70%). Every new scenario needs a pile of rules, and the rules conflict. Six months in, the team realized: they spent Agent money and built a chatbot with LLM-generated copy.
Taking a scenario where the LLM could make autonomous decisions, using "controllability" as the excuse, and degrading it to L1 — this crash is sneakier than the first, because on the surface "the project shipped."
Crash 3: Business chasing L3 multi-Agent, engineering can't hold it
The third kind shows up most in "deck projects." At one review meeting, the business side showed me a plan: 5 sub-Agents (Sales, Inventory, Customer, Ops, CEO) talking to each other, deciding for each other, reflecting on each other, finally outputting a "strategic recommendation report."
I asked: which Agent listens to which? How are conflicts arbitrated? If one Agent's output is wrong, how does the downstream know? What's the token cost per evaluation run?
The business side couldn't answer. They'd seen "Agent collaboration" in a demo video; they hadn't seen the engineering complexity underneath.
L3 multi-Agent orchestration is meaningfully harder to ship reliably than single-Agent in 2026. The component tooling has matured (AutoGen, CrewAI, LangGraph give you the loop primitives), but state management, error propagation, cost control, and observability across multiple agents remain order-of-magnitude harder than single-Agent — which means plenty of companies are paying for it, but very few teams ship it production-grade. Not an LLM-capability problem — an engineering-governance problem.
Three crashes, one root cause
The root cause of all three isn't the LLM's fault or the team's fault. It's that everyone uses the same word "Agent" while talking about completely different things.
The Agent sales describes is L1, the Agent the business exec wants is L2, the Agent engineers can ship reliably is L1-L2, the Agent the business side imagines is L3 — four parties out of sync, and the budget crashes.
To stop this from happening, step one is building a shared language. What follows is version one — four levels, one criterion, the wording that lets four people at a table actually mean the same thing.
2. The L0-L3 Framework: A 4-Level Agent Autonomy Model (a.k.a. Maturity Model)
To fix the "four parties out of sync" problem, you don't need a fancier definition. You need a ruler you can pick up and use immediately: judges at a glance, aligns everyone, doesn't require a technical background. Think of it as an agent autonomy model — what others call levels of autonomy or an AI agent maturity model — where each level is defined by how much the LLM decides at runtime. It's also the fastest way to settle the questions people actually argue about: is this an AI agent vs a chatbot, vs a plain LLM, vs a workflow?
Four levels. But first, one key insight: the four look linear, but the biggest chasm is between L1 and L2. That's the line between "automation with an LLM bolted on" and a real Agent. Every "fake Agent" crash is a failure to see this line.
| Level | Name | Core trait | Plain-language version |
|---|---|---|---|
| L0 | Rule automation | if-then decision tree, fixed branches, no LLM | "a chatbot reading from a script" |
| L1 | LLM-enhanced | LLM does content generation / comprehension, but the pipeline is fixed; no autonomous decisions | "a template engine that got smart" |
| L2 | Tool-calling Agent | LLM decides which tool to call, when, and how to use the result — has autonomous decisions | "a digital employee who can query systems and make judgments" |
| L3 | Multi-step orchestration Agent | Multi-Agent collaboration, with a plan→execute→reflect loop, handling open-ended tasks | "a digital team that completes complex projects independently" |
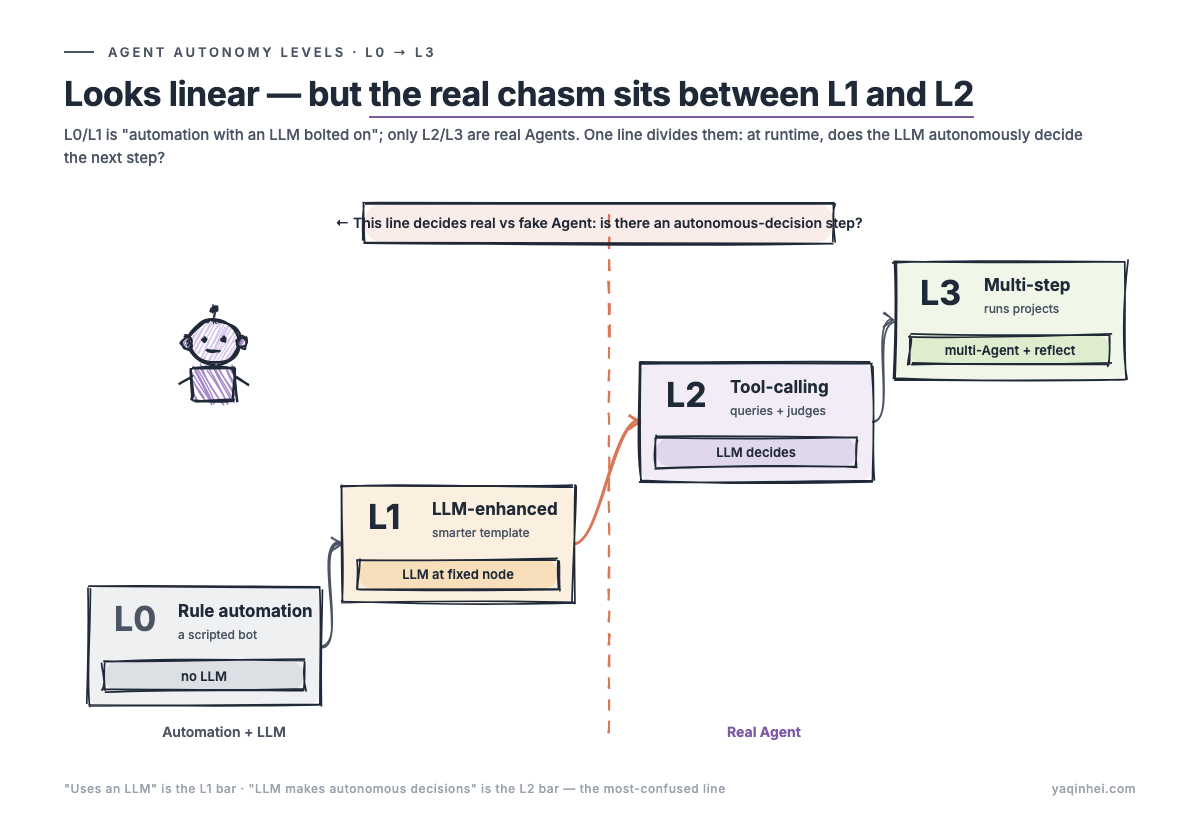
The only criterion: is there an autonomous-decision step?
To judge what level a system is at, you only need to answer one question —
At runtime, does the LLM dynamically choose the next action based on context?
- Answer "no": the pipeline is preset, the LLM is absent or only works at fixed nodes → L0 (no LLM) or L1 (has LLM but fixed pipeline)
- Answer "yes, at one node": the LLM makes a decision at one key node ("should I escalate or not") → entry-level L2
- Answer "yes, at multiple nodes": the LLM decides at multiple nodes ("what to look up first, how to use what it finds, where to go next") → typical L2
- Answer "yes, with a reflection loop between decisions": the LLM evaluates whether the last step was right and whether to redo it → L3
"Used an LLM" and "the LLM makes autonomous decisions" are two different things. The former is the threshold for L1, the latter for L2. This is the most commonly confused line.
Three worked examples
Definitions are still abstract. Three scenarios pulled apart — the difference in shape is obvious.
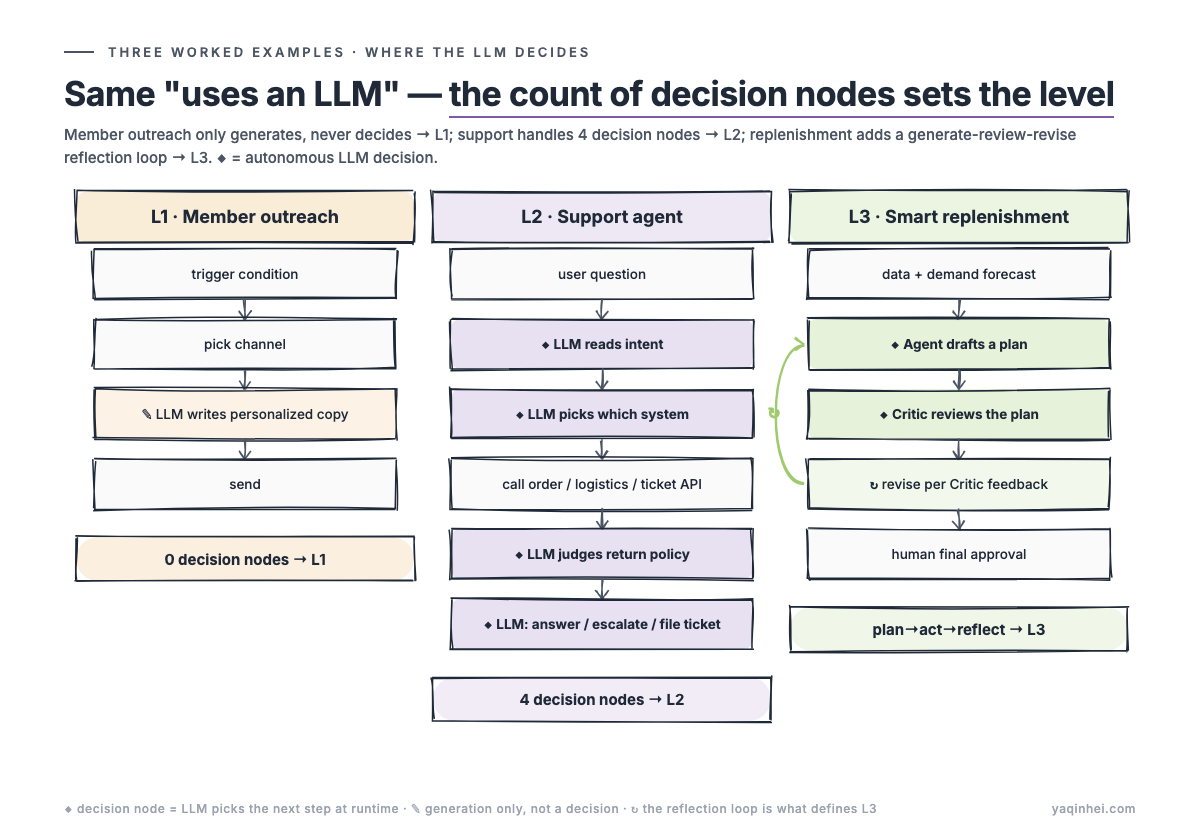
Example A: Membership outreach (L1)
Why it's L1: the LLM only works at the "generate copy" node; the whole pipeline is preset; there's no "LLM decides where to go next" step.
trigger → pick channel → [LLM generates personalized copy] → send
↑ the whole pipeline is preset; LLM only works at "generate copy"
↑ typical L1
The LLM makes the SMS more conversational, more personalized — it feels "like there's AI in it" — but it's fundamentally a template engine. Swap the LLM for a well-tuned template engine plus an intent classifier and the system architecture is structurally the same — L1, regardless of how good the generated content is. That's the boundary of L1.
Example B: After-sales customer service (L2)
Why it's L2: the LLM makes autonomous decisions at 4 nodes (understand intent → decide which system to query → judge policy → decide reply/escalate/create ticket); the pipeline isn't preset; every conversation's path is different.
user question → [LLM understands intent] → [LLM decides which system to query]
→ call Order API / Logistics API / Ticket API
→ [LLM judges whether it meets the returns policy]
→ [LLM decides: answer directly / escalate to human / create ticket]
↑ LLM makes autonomous decisions at 4 nodes
↑ typical L2
This is what an Agent is. The LLM isn't "added at one step" — it's the brain stringing the whole pipeline together. Every conversation's execution path is different, but all converge on the same goal (solve the user's problem).
Example C: Smart replenishment (L3)
Why it's L3: not because it "uses multiple Agents," but because it has a plan→execute→reflect loop — an Agent generates a plan, a Critic Agent reviews it, the Agent revises per the review feedback, iterating until convergence.
(Critic Agent is a concept that recurs below, so here's a definition: a second LLM whose job is to review whether the first LLM's output is reasonable. The first Agent proposes "restock 100 T-shirts to Store A," the Critic checks whether that plan respects inventory caps, brand authorization, seasonality, and bounces it back if it doesn't. Essentially "AIs proofreading each other" — keeps a single LLM from talking itself into a mistake.)
data collection → [demand forecast model]
→ [Agent generates restock plan]
→ [Critic Agent reviews plan plausibility]
→ [Agent revises plan per Critic feedback]
→ iterate until convergence
→ human final approval
↑ multiple Agent roles + reflection loop
↑ handles open-ended tasks ("what should we restock this week" has no canonical answer)
↑ typical L3
L3's key isn't "uses more Agents." It's the reflection loop: the system evaluates whether its own output is right and redoes it if not. That's what fundamentally separates L3 from L2.
One more note: smart replenishment is one of the biggest pain points in retail AI these past couple years — nearly every leading brand is trying it — but very few stabilize it at L3. Same reason as Crash 3 above: plenty of customers willing to pay for multi-Agent collaboration, very few teams that can hold the engineering complexity.
How to use this ruler
Back to the opening scene: when the boss asks "is what we're building an Agent?", you don't argue. Hand him this table, show him the 3 worked examples, and he can judge for himself.
Going further: you can map each candidate scenario onto the table one by one. In an afternoon you get a list more useful than any deck strategy — of these 28 scenarios, which are L0, which are L1, and which actually deserve Agent money to build as L2 / L3.
If "map onto the table" still sounds vague, the 5-question checklist below turns it into 3 minutes per project.
3. The 5-Minute Self-Check: What Level Is Your Project?
Five questions split out of the previous section's method, each answerable in 30 seconds. Answer all of them and you know what level the project is — and whether the vendor is fooling you.
This section is the one you screenshot for your team group chat and forward to your boss.
Q1. How many decision nodes does the LLM have in your pipeline?
Count them: after user input comes in, at which steps does the LLM "judge which step to go to" — not generate content, not give an answer, but decide the direction of the next step.
→ 0 nodes: L0 / L1 | 1 node: entry-level L2 | multiple: typical L2 | multiple + reflection loop: L3
🚩 Red flag: the vendor says "our Agent intelligently chooses the optimal path" — ask which nodes, specifically. Can't name the nodes? Probably L1 in a wrapper.
Q2. If the LLM's output is wrong, does it cause irreversible consequences?
One mark of a real L2 / L3 Agent: its output triggers side effects — issues refunds, modifies orders, creates tickets, deducts inventory.
→ No side effects, just response content: L1 / L2 Q&A type | side effects + rule double-check: L1 / L2 | side effects + LLM decides execution itself: L2, must have a Critic backstop | can adjust subsequent actions based on outcomes: L3
🚩 Red flag: "our Agent has fully replaced humans" — for any write operation involving money, inventory, or customer commitments, "full replacement" without a human backstop / Critic check is high-risk.
Q3. At runtime, are the pipeline branches preset, or does the LLM decide on the fly?
Open the project code (or ask the engineer):
→ Flowchart is hardcoded, LLM only works inside one box: L0 / L1 | a few main branches, LLM picks which one: entry-level L2 | no static flowchart, LLM builds the path dynamically from context: typical L2 / L3
🚩 Red flag: the vendor's architecture diagram has every node drawn neatly with arrows connected — probably L1. A real Agent's architecture diagram is a tool list + context + LLM routing, with no static flowchart.
Q4. Does it need to pull data across multiple external systems + make a combined judgment?
A core capability of a real L2 Agent: the LLM decides which system to call, how many times, and how to stitch the results into an answer.
→ Doesn't need external systems: L0 / L1 | queries 1 system + rule routing: L1 | queries multiple systems + LLM decides how to use them: L2 | cross-system data + cross-Agent collaboration + reflection: L3
🚩 Red flag: "our Agent integrates 50 systems" — ask how the LLM knows which one to call. If the answer is "we wrote routing rules," the LLM isn't making decisions. It's L1.
Q5. Is there a "plan → execute → reflect" loop?
L3's fundamental trait:
→ Outputs once and stops: L0 / L1 / L2 | after output, another Agent evaluates and decides whether to redo: entry-level L3 | multiple roles collaborating "generate—review—revise": typical L3
🚩 Red flag: "we used 5 Agents" — ask, how do these 5 Agents collaborate? Who listens to whom? How are conflicts arbitrated? Can't answer = it's marketing copy, not an engineering plan.
Self-check summary table
| Q1 decision nodes | Q2 side effects | Q3 pipeline dynamism | Q4 cross-system data | Q5 reflection loop | Conclusion |
|---|---|---|---|---|---|
| 0 | none | preset | none | none | L0 / L1 |
| 1 | yes | partly dynamic | single system | none | entry-level L2 |
| many | yes | dynamic | cross-system | none | typical L2 |
| many | yes | dynamic | cross-system | yes | L3 |
This table plus the 5 questions: 5 minutes to position any AI project.
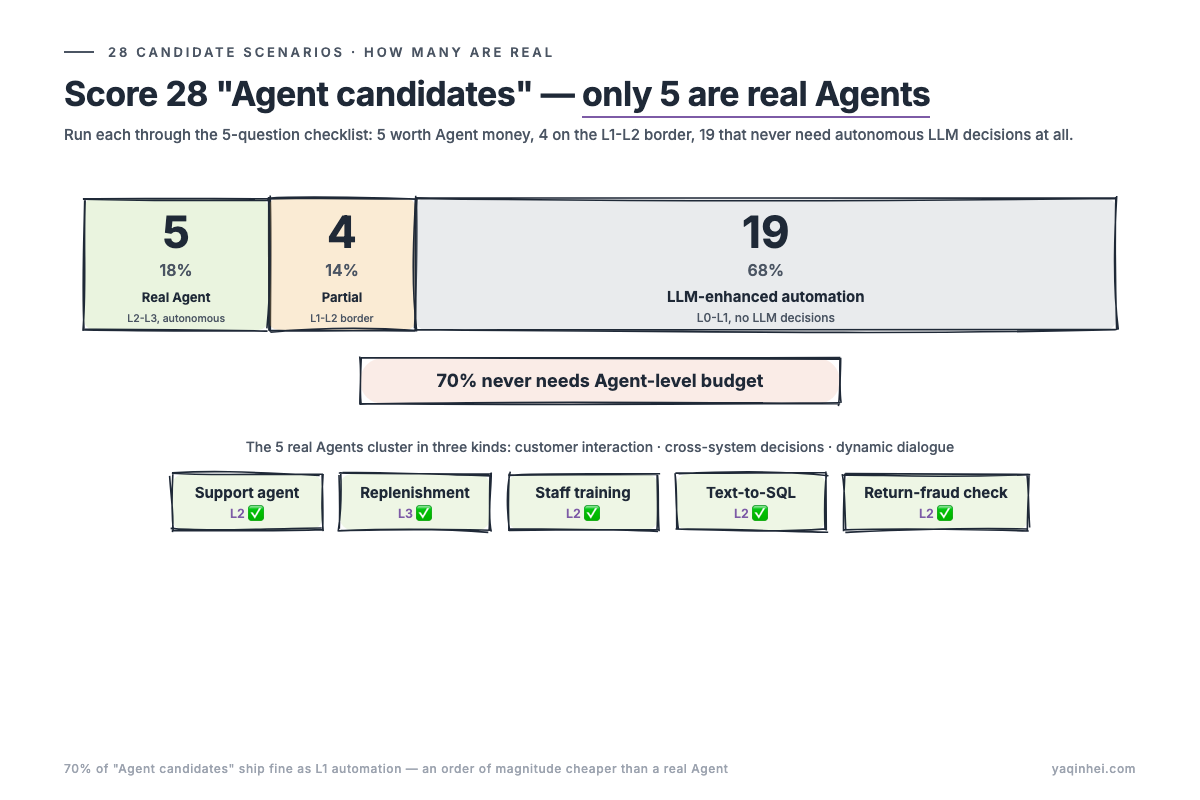
Try the ruler on something real. Below, 28 candidate scenarios run through it. Spoiler: real Agents (L2-L3) number just 5, LLM-enhanced automation (L0-L1) numbers 19, 4 sit in between. Which is to say: 70% of "Agent candidates" don't need Agent money at all. Hold that number in your head — the next section shows which ones.
4. Putting the Ruler Against 28 Candidate Scenarios
Time to put the ruler against concrete scenarios.
Below are 28 of the most common AI candidate scenarios in retail / consumer, split by business layer. I ran each one through the previous section's 5 questions — the result may upend your sense of what an "AI project" is.
The names here are generic retail-industry terms. If you're not in retail, read "store associate" as "salesperson" and "replenishment" as "inventory turnover" — the logic generalizes.
Customer journey layer (5 candidates)
The customer-facing layer — ground zero for AI abuse.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 1 | After-sales customer service | L2 ✅ | Multi-turn dialogue + cross-system queries + LLM decides answer/escalate/create-ticket — 4 decision nodes |
| 2 | Online sales co-pilot | L1-L2 ⚠️ | RAG retrieval of product knowledge + outfit recommendations, mostly assisting the associate not replacing them |
| 3 | In-store sales co-pilot | L1 ❌ | Scan-to-look-up product knowledge cards — fundamentally RAG queries |
| 4 | Membership operations | L1 ❌ | Rule triggers + templated SMS, LLM only generates copy |
| 5 | Personalized recommendations | L0-L1 ❌ | Recommendation algorithm at the core + LLM explaining the rationale |
Of the 5 in this layer, only 1 is a real Agent (after-sales customer service). The other 4 are all "existing systems with an LLM bolted on" — most companies call membership operations a "membership Agent" too, but it doesn't need the LLM to make any decisions.
Supply chain layer (5 candidates)
The layer that pains business executives most, and one of the few candidate grounds for a real L3 Agent.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 6 | Smart replenishment & transfer | L3 ✅ | Demand forecast + Agent generates plan + Critic reviews + reflection iteration |
| 7 | Slow-mover alerts | L1 ❌ | Rules / models detect aging-inventory anomalies + LLM generates alert briefs, fixed pipeline |
| 8 | Logistics exception tracking | L0-L1 ❌ | Integrate logistics API + rules judge delays + notify, event-driven automation |
| 9 | New-product allocation | L1-L2 ⚠️ | Store-profile matching + forecast model + generate allocation plan, mostly algorithm-driven |
| 10 | Supplier collaboration | L1 ❌ | Data aggregation + LLM generates brand sales reports |
Of the 5 in this layer, also only 1 is a real Agent (smart replenishment). The rest — "smart slow-mover alerts," "smart logistics" — names that bluff; fundamentally rules + LLM copy.
Store operations layer (5 candidates)
The layer most easily bluffed by "automation" — 3 of the 5 don't need an LLM at all.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 11 | Scheduling optimization | L1 ❌ | Historical traffic forecast + generate scheduling suggestions, optimization algorithm leads |
| 12 | Store KPI coaching | L1 ❌ | Data aggregation + LLM generates ops-analysis interpretation |
| 13 | Display-compliance detection | L0 ❌ | Computer vision recognizing shelf-layout rules — a CV task |
| 14 | Inventory counting | L0 ❌ | RFID data + anomaly detection algorithm — IoT |
| 15 | Equipment maintenance | L0 ❌ | Sensor data + predictive-maintenance model |
No real Agent in this layer. If a vendor sells you a "store ops Agent," check which scenario first — probably a CV or IoT system with an LLM-copy shell.
Talent development layer (4 candidates)
The one "not-core-business but has a real Agent" layer.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 16 | Employee training | L2 ✅ | LLM plays the customer role, multi-turn dialogue simulation training, dynamic question generation |
| 17 | Recruitment screening | L1 ❌ | Resume parsing + rule matching + LLM scoring |
| 18 | Performance feedback | L1 ❌ | Data aggregation + LLM generates personalized performance reports |
| 19 | Employee care | L0-L1 ❌ | Text analysis of employee sentiment trends — NLP analysis |
Employee training is an interesting L2 — the LLM plays the customer talking to the employee, dynamically adjusting difficulty and scenario per the employee's responses. This "role-play + dynamic question generation" is one of the few non-core-business scenarios suited to L2.
Marketing & growth layer (5 candidates)
The home turf of LLM content generation, and L1's comfort zone.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 20 | Campaign planning | L1 ❌ | Historical ROI analysis + LLM generates plan drafts, humans make the decisions |
| 21 | Content generation | L1 ❌ | LLM batch-generates product copy / social posts |
| 22 | Competitor monitoring | L0-L1 ❌ | Crawler collection + rule alerts + LLM generates briefs |
| 23 | Data analysis (Text-to-SQL) | L2 ⚠️ | LLM decides what SQL to generate, calls the database tool, interprets results |
| 24 | Brand compliance | L1 ❌ | Rules + LLM checks whether marketing material is compliant |
Note a counterintuitive point: content generation, though end-to-end LLM, is not an Agent — there's no autonomous-decision step; it's just the LLM as a copy machine.
Finance & risk layer (4 candidates)
Write-operation-dense, and the layer where Critic backstops matter most.
| # | Scenario | Level | One-line reason |
|---|---|---|---|
| 25 | Return-fraud detection | L2 ✅ | Multi-dimensional anomaly detection + correlation analysis + LLM judges whether to flag / intercept |
| 26 | Price optimization | L0-L1 ❌ | Optimization algorithm searching for the best price within the brand-authorized range |
| 27 | Financial forecasting | L1 ❌ | Time-series forecast model + LLM generates interpretation |
| 28 | Compliance review | L1-L2 ⚠️ | LLM reads contracts + checks a rule base, linear pipeline |
One real Agent in this layer's 4 (return-fraud detection). This is an L2 that must have a Critic backstop — flagging and intercepting are both write operations, and getting them wrong offends customers.
The 28 scenarios, summarized
Regrouping the 28 by level:
| Type | Count | Share | Representative scenarios |
|---|---|---|---|
| ✅ Real Agent (L2-L3, autonomous decisions) | 5 | 18% | After-sales CS, smart replenishment, employee training, Text-to-SQL, return-fraud |
| ⚠️ Partial Agent (L1-L2 boundary) | 4 | 14% | Online sales co-pilot, new-product allocation, compliance review, data analysis |
| ❌ LLM-enhanced automation (L0-L1) | 19 | 68% | Everything else |
The most important conclusions:
- Only 5 genuinely need "Agent money to build an Agent." The other 19 don't need the LLM to make autonomous decisions at all — build them as L1 automation; the budget magnitude is an order of magnitude below Agent.
- The 5 real Agents cluster in three kinds of scenario: direct customer interaction (after-sales CS), cross-system decisions (replenishment / fraud / Text-to-SQL), dynamic dialogue (employee training). Other scenarios called "Agent" are mostly marketing copy.
- Scenarios that need no LLM at all (L0) still number 3 (display compliance / counting / maintenance) — don't force-fit an LLM onto CV and IoT.
A suggestion: put your project names on a diet
Rename the 28 scenarios by their true level, and the complexity and budget of the whole portfolio gets clear:
| True level | Recommended naming | Example |
|---|---|---|
| L2 / L3 | "XX Agent" | After-sales CS Agent, smart replenishment Agent |
| L1 | "AI XX Assistant" or "Smart XX System" | AI copywriting assistant, smart scheduling system |
| L0 | "XX Automation" | Display-compliance automation, inventory-counting automation |
Next time someone proposes "we'll do 28 Agent projects," have them rename the list by this scheme first. Once the names change, the budget converges on its own — Agent and "assistant" aren't the same order of magnitude.
Three kinds of reader will use this ruler differently — decision-makers in vendor reviews, pre-sales explaining product, engineers pushing back on scope. The next section is the playbook for each.
5. An Action Guide for Three Kinds of Reader
You have the ruler and the verdict. Three readers, three typical situations — here's how each one uses the framework to win the fight in front of them.
For decision-makers: 3 due-diligence questions for evaluating vendors / internal kickoffs
After any "Agent solution" pitch, ask these 3 — can't answer any one, the plan needs a rewrite.
Q1: Measured by the L0-L3 framework, what level is this? Have the proposer (sales / internal team) give a clear answer against the 4-level table on the spot. Answers like "we transcend the grading" or "we combine multiple levels" — red flag, they're dodging the grade.
Q2: Are we paying L-what money? L0 / L1 and L2 / L3 are an order of magnitude apart in budget. L1 priced at L2, you're getting robbed; a real L2 budgeted at L1, the team cuts corners and builds L1.
Q3: Post-delivery, what level do we evaluate the impact at? L0 / L1 looks at "automation rate," "copy click rate"; L2 looks at "task resolution rate," "cross-system accuracy"; L3 looks at "plan acceptance rate," "reflection convergence speed." Mismatched metric and level = everyone bickers — the vendor says it hit target, the business side says it feels off. When you push the same misalignment into an RL-trained agent, it surfaces as reward hacking — the agent learns to game whichever metric you optimized for, not the goal you actually wanted.
Ask these 3 and you can see through a deck project in 30 minutes.
For pre-sales / solution PMs: a script template for explaining your product's difference to customers
Two questions customers ask most, and the L0-L3 framework answers them better than any marketing copy:
"What's the difference between you and XX?"
"Their solution is L1 — the LLM embedded in a fixed pipeline doing content generation. We're L2 — the LLM makes autonomous decisions at multiple nodes. The difference isn't parameter size or model version. It's the LLM's role in the system. I can pull it apart for you live: in their architecture diagram the LLM sits in one box; in ours the LLM strings the whole pipeline together."
"We already have a chatbot — why build an Agent?"
"Your current chatbot is L0 — runs on a rule tree. Its 'catch rate' may be high (80%+), but its 'resolution rate' is unknown — because it escalates the questions it can't answer and never actually resolves them. An Agent is L2 — the LLM decides which system to query, judges policy, decides answer-or-escalate. The difference isn't which is smarter — it's the leap from 'catching' to 'resolving'."
Remember one core sentence pattern — "we're L X, what you / they currently have is L Y, the gap isn't tech quality — it's the LLM's role in the system." The customer draws their own conclusion; you don't have to keep selling.
For engineering teams: how to push back on "this scenario doesn't need to be an Agent"
When the business exec says "build everything as Agents," engineering's hardest problem isn't the tech — it's convincing the boss that "this scenario is fine as L1."
Saying "boss, this doesn't need an Agent" directly → the boss suspects you're being technically conservative / shirking. Replace it with three steps:
1. First, re-describe the scenario in language the boss knows
"Boss, 'smart membership outreach' is L1 by the L0-L3 framework — the LLM works at one node, 'generate copy,' everything else runs on rules."
2. Spell out the cost and risk of building it as L2
"Building it as L2 means letting the LLM decide 'when to send, to whom, via which channel' — the dev effort is 3-5x L1, every failure case needs a retro. How much better than L1 will the result be? We have no evidence."
3. Offer a compromise the boss can accept
"Suggest we do L1 first, live and showing results in 3 months. If the result hits a ceiling, then upgrade to L2 — by then we'll have data to judge whether the upgrade's worth it, instead of going on gut."
The core: don't make the boss feel "you're rejecting his direction" — make him feel "you gave him a steadier path." The framework's value here is translating fuzzy engineering judgment into business language. The boss understands "3x dev effort" and "evidence of impact," but not "tool-calling framework."
6. Closing: Picking the Right Level Beats Chasing a Higher One
Back to where we opened.
The boss banged the table on "we're doing Agents this year," the team came back with 28 candidates. If you've read this far, you know: only 5 genuinely need to be built as Agents.
But that's not bad news.
The bad news belongs only to those who sell L1 as L2, build L0 as L2, treat the L3 in the deck as something that can actually ship. For teams that genuinely want to solve business problems with AI, the framework sends 70% of the investment back to the right place. L1 automation has L1 value — it just shouldn't get Agent budget, Agent KPIs, or the name "Agent".
An Agent isn't the endpoint. It's a tool. Picking the right level beats chasing a higher one.
One action: run your projects through it first
If you've read this far, do one thing first: go back to Section 3 and run the AI project you're currently building (or evaluating) through the 5 questions. What level is it?
Twenty minutes, and you get a list more useful than any deck strategy. Use it as the basis for your next meeting — it beats any "AI transformation roadmap."
Get the toolkit for this article
If you want to put these tools straight to work on your own project — without re-reading this article every meeting — I've put together a PDF toolkit for readers who got this far:
📥 Send me the keyword "L0-L3 KIT" and I'll send the toolkit:
- The 28-scenario grading table (a one-page A3 print version — see your whole portfolio in 30 seconds)
- The 5-question self-check, card version (6 square cards — drop one in the team chat and everyone gets it)
- The L0-L3 framework, high-res (drop it straight into a deck — comes with the plain-language column)
These are judgment tools distilled from two years of customer-service Agent projects.
What's next in this series
This is the first piece of the Agentic AI in Practice methodology series. The L0-L3 framework solves the "align the language, see the current state" problem — but how do you actually build the 5 real Agents? That's where most teams get stuck.
The next piece: how do you actually build an L2 Agent for customer service?
Core questions include:
- Why an L2 customer-service Agent can't use L3 autonomous planning — what are the deterministic-safety requirements for financial operations?
- How do you tune the cost-vs-quality triangle of a three-level intent fallback (rules → embedding → LLM)?
- The fail-closed LLM Critic design for write operations (refunds / order changes / ticket creation) — why must timeout / error escalate to a human rather than approve?
- Contract design for 25 API integrations (orders / tickets / logistics / e-commerce, 6 systems)
- How to build the evaluation system from 80% "catch rate" to 65% "resolution rate" — what do the metrics for a business exec look like?
If your team is building a customer-service Agent, the next piece goes deeper, finer, and is more useful in engineering terms.
Subsequent pieces — now live:
- Piece two: Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship
- Piece three: Why a 70% Critic Beats a 95% Critic — A Fail-Closed Design Deep Dive
- Piece four: Deploy and Abandon — The Costliest Misconception in AI Agent Projects
If this was useful, pass it to whoever on your team needs it — especially the colleague who's been tortured by "28 Agent candidate projects."
FAQ
How do I tell if my AI project is a real agent or just automation with an LLM? Ask one question: at runtime, does the LLM dynamically choose the next action based on context? If the pipeline is preset and the LLM only generates content at fixed steps, it's L1 — "automation with an LLM bolted on." If the LLM decides which tool to call, when, and how to use the result, it's a real Agent (L2 or higher).
How do I grade how autonomous an AI agent is? Count the decision nodes where the LLM chooses the direction of the next step — not where it generates content, but where it decides what happens next. Zero nodes is L0/L1; one or more is L2; multiple nodes plus a plan→execute→reflect loop is L3. The 5-question self-check in this article turns that count into a 3-minute grading.
What are the levels of AI agent autonomy? Four. L0 — rule automation, no LLM. L1 — LLM-enhanced: the LLM generates content but the pipeline is fixed and makes no autonomous decisions. L2 — tool-calling Agent: the LLM decides which tool to call and how to use the result. L3 — multi-step orchestration Agent: multiple agents in a plan→execute→reflect loop on open-ended tasks. The chasm between L1 and L2 is the line between fake and real Agents.
Is there a framework to classify or score AI agents by capability level? Yes — the L0-L3 framework here scores any AI project on a single axis: how much the LLM decides at runtime. It lines up with other autonomy scales (Bessemer's L0–L6, Knight Columbia's five user-roles from Operator to Observer) but collapses them to the one distinction that actually decides budget: does the LLM make autonomous decisions, and is there a reflection loop?
How do I assess the maturity of an enterprise AI agent project? Run it through the 5-question self-check: how many LLM decision nodes, whether outputs cause irreversible side effects, whether the pipeline is preset or built dynamically, whether it pulls across multiple systems, and whether it has a plan→execute→reflect loop. The answers place the project at L0–L3 and tell you whether it deserves Agent budget — in a 28-project audit, only 5 did.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.