Intent Classification for Chatbots: Why Pure-Rule and Pure-LLM Both Fail (a 3-Tier Cascade)

Eighth post in the Agentic AI in Practice series. The first seven covered whether a plan can ship, how to keep it from rotting after launch, and how to test it — L0-L3 grading, the 5 architecture decisions, fail-closed Critic, deploy-and-abandon, containment vs resolution, Skills vs knowledge base, dual-track testing. This one delivers the promised deep-dive on Decision 2 from post II — what the 3-tier intent fallback's thresholds should actually be. 中文版:3 级 intent 级联调参——规则 / Embedding / LLM 的成本-精度-延迟三角到底怎么定阈值.
A "let's just add LLM as a fallback" that triggered a 12x bill
A retail customer-service Agent project, three months in. Ops looked at the dashboard: 1,102 user messages, intent-classification accuracy 59.44%, unknown rate 40%.
The business side asked something that sounded perfectly reasonable: "for that 40% unknown, can we just add an LLM as a fallback?"
The vendor did. A week later the monthly bill landed — intent classification cost was 12x what it had been. Accuracy moved up by ~8 percentage points. The exec stared at the bill for half an hour without saying anything.
I have seen this exact arc three times in the past year, with three flavors of the same mistake —
- Path A: pure rules. Intent taxonomy grows from 15 to 30. Rules start eating each other. Three months later nobody wants to maintain
rules.pyand the engineering team revolts. - Path B: pure LLM. "LLMs are cheap now, just hit the API." High-concurrency scenario, 600K calls/day, six-figure monthly cost, latency makes streaming SSE unviable.
- Path C: 3-tier fallback. Rules 60% + embedding 30% + LLM 10%. Cost is 1/10 of the pure-LLM path. Accuracy is actually higher.
Path C is what every customer-service Agent I have seen ship has converged on. But what is hard about 3-tier fallback is not the architecture — it is the thresholds: what confidence to return on, what ambiguity gap triggers a clarify, what unknown rate is normal for LLM, how to cache, how to rate-limit.
This post is the tuning manual. The next time someone says "just add LLM as a fallback," you can put a table on the desk.
It also delivers a second thing: once the 3-tier fallback is humming, what is the next move? When v1 hits its ceiling — taxonomy past 40 intents, policy boundaries shifting weekly, anchor-tuning marginal returns below +2pp — the natural evolution is v2 LLM Router, where the LLM combines context + multi-turn history + the current query and routes directly to ACTION / POLICY / CLARIFY paths. Section 8 below is the full v1 → v2 comparison.
Why both extremes fail
Conclusion on the table: pure rules, pure LLM, and 3-tier fallback are three architectures. The first two die on production.
| Approach | Cost | Latency | Accuracy ceiling | Maintenance | How it dies |
|---|---|---|---|---|---|
| Pure rules | ~0 | sub-ms | 70-75% | Very high | Past 30 intents rules eat each other; engineering revolts in 6 months |
| Pure LLM | 10x | 200-500ms | 85% | Low | Six-figure monthly bills + can't carry high concurrency + unstable outputs |
| 3-tier fallback | Reasonable | Mixed | 90%+ | Medium | Ships |
Pure-rule's two death modes: (1) at ≤10 intents it flies, accuracy mediocre but acceptable; (2) at 30+ intents rules collide — "return shoes" matches product_inquiry or return_request? Same utterance hits two rules; the implicit ordering is undocumented. Six months in, total rules pass 100, and the next engineer who opens rules.py files a transfer request.
Pure-LLM's three death modes. Cost: high-concurrency, 600K calls/day at qwen-turbo's ¥0.002/1k token comes to six figures monthly. Latency: intent classification runs on every user utterance; LLM 200-500ms baseline, plus RAG retrieval + workflow execution + generation, first-token latency past 2 seconds — user sees SSE freeze. Stability: non-zero temperature returns different intents for the same utterance every time; temperature zero still hallucinates on corner cases (invents an intent label outside the taxonomy).
3-tier fallback is the only viable engineering path — solve 60% with the cheapest layer, 30% with the next-cheapest, 10% with the most expensive, escalate the rest. Any project that flips this ratio either burns cash, can't carry load, or never reaches accuracy targets.
The cost / precision / latency triangle in one table
This is the baseline for every threshold below. Print it and pin it to the wall.
| Tier | Per-call cost | Per-call latency | Accuracy lift | Coverage target | Failure mode |
|---|---|---|---|---|---|
| Level 1 Rule | ≈ $0 | sub-ms | baseline 70% | 60-70% | Rules eat each other / regex too broad |
| Level 2 Embedding | ~$0.00002 | 20-50ms | +10-15pp | 20-30% | Low threshold misfires / high threshold drops recall |
| Level 3 LLM | ~$0.0002 | 200-500ms | +5-10pp | 5-10% | Force-picking / hallucinated intent labels / timeouts |
| Unknown → human | n/a | n/a | n/a | 3-5% | Below 2% = forced guessing; above 10% = taxonomy gap |
Three numbers to remember: 60 / 30 / 10. The coverage targets for each tier of the 3-tier fallback.
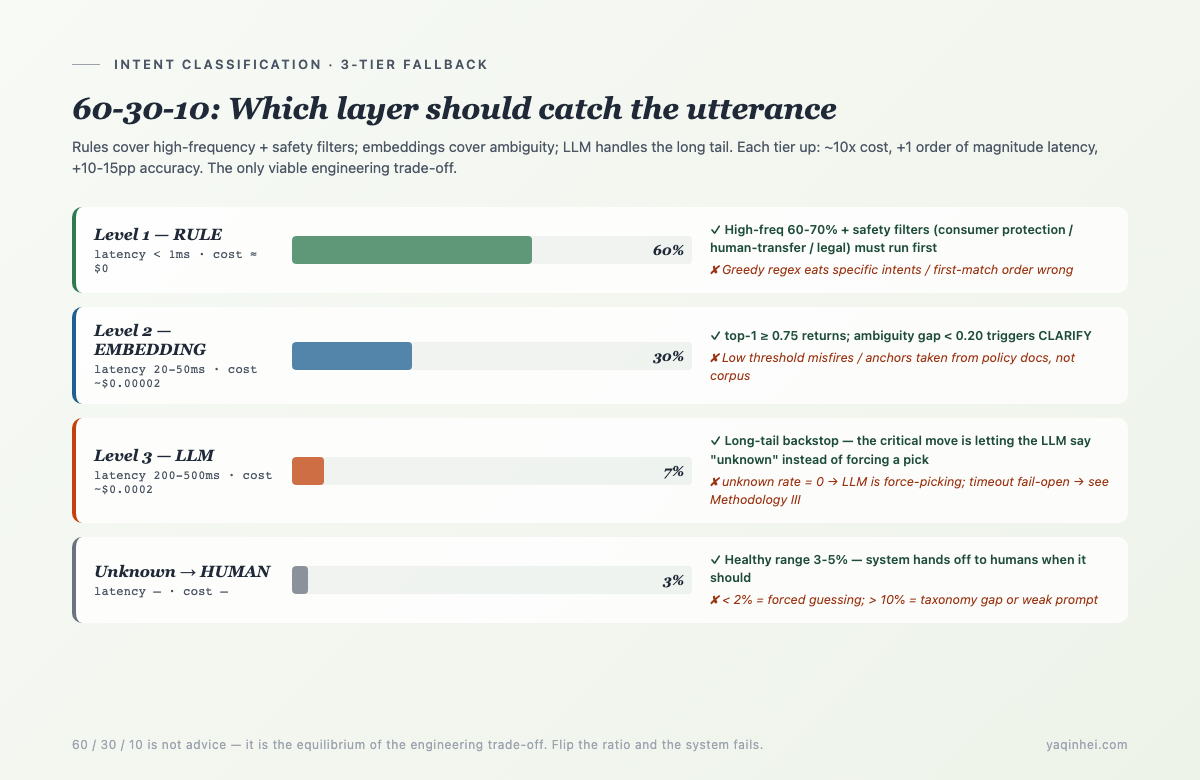
The numbers themselves are not magic. What is useful is that when your live distribution deviates from this ratio, there is always a corresponding engineering problem —
- Rule coverage below 50%: taxonomy expanded but rules didn't; pull out the highest-frequency missing intents and add patterns
- Rule coverage above 80%: a broad rule may be eating specific intents ("return shoes" caught by a generic "shoes" rule); audit
- Embedding coverage below 15%: threshold too high, or high-frequency user expressions are too far from your anchor sentences
- Embedding coverage above 40%: threshold too low, accuracy is about to collapse
- LLM coverage above 15%: embedding is underfilled; the long tail is being shoved up to LLM
- LLM coverage below 3%: LLM threshold too strict, or embedding is over-claiming and swallowing things it shouldn't
- Unknown above 10%: taxonomy gap, or user expression diversity exceeds your labeled corpus
This monitoring signal set is the steering wheel for tuning. Run two weeks of production traffic, look at the distribution, dial back to the table.
Level 1 — rules are not "low-tech," they are the only layer that guarantees "12315" doesn't slip through
The rules layer takes the most heat in reviews — "we're in 2026 and you still write regex?" — but rules are the only layer in the 3-tier fallback that can hard-guarantee compliance-critical intents.
Concrete example. A user says "I'm calling 12315" / "I'm going to consumer-protection" / "I'm posting this on TikTok" — these are PR-risk signals that absolutely cannot be routed through embedding or LLM. Three reasons:
- Embedding recall is unstable — "12315" lives nowhere near "consumer-protection," "regulatory authority," "market supervision" in vector space; they scatter
- LLMs occasionally "misunderstand" — I have seen an LLM interpret "calling 12315" as "spending 12,315 yuan." Real bug
- These need millisecond-level response — 200ms of LLM latency is enough time for the user to post
So the rules layer's first job is not 60% coverage of high-frequency intents — it is matching 8-16 safety filters first:
INTENT_RULES = [
# Group 1: safety filters (highest priority, always match first, within 0.5ms)
("escalate_complaint", [
r"12315", r"consumer protection", r"BBB",
r"regulatory", r"complaint.*twitter", r"complaint.*tiktok", r"FTC",
]),
("human_transfer", [
r"^human$", r"^agent$", r"real person", r"speak to a person",
]),
("legal_threat", [
r"sue", r"lawsuit", r"attorney", r"lawyer",
]),
# Group 2: high-frequency business intents (cover 60-70% of daily traffic)
("return_request", [
r"return", r"send back", r"no-questions-asked",
r"i want to return", r"how do I return",
]),
("refund_status", [
r"refund", r"refund.*when", r"refund.*progress",
]),
# ... 8-12 more high-frequency business intents
]
Three iron laws of rule design, each one paid for in production —
Iron law 1: first match wins, so order is everything. Safety filters always come first (even if 99% of conversations never hit them). High-frequency intents ordered "specific before generic": "return shoes" goes in return_request, then a generic product_inquiry rule for "shoes" — reversed, "shoes" would eat "return shoes."
Iron law 2: regex can't be too broad or too narrow. Too broad: r"return" matches "return trip" or "return ticket". Too narrow: r"i want to return this item" only matches the full sentence. The right granularity: 3-5 high-frequency phrasings + 1-2 variants — r"return", r"send back", r"i want to return", r"how do i return".
Iron law 3: anchor short utterances. r"^hi$" matches a bare greeting; r"hi" would catch "hi i want to return" and route it to greeting. The ^ and $ anchors are this layer's soul.
Done well, the rule layer covers 60-70% of daily intents and 100% of high-risk PR signals — and is the foundation of the entire 3-tier fallback architecture.
Level 2 — embedding is the ambiguity safety net; tune two thresholds, not one
Rule misses fall to embedding. The core of this layer isn't the confidence threshold — it's the ambiguity gap.
What's the ambiguity gap? Same utterance, vector similarity to top-1 intent is 0.78; similarity to top-2 is 0.72. The gap is 0.06 — you should not return top-1; you should kick off clarification.
Tune the two thresholds separately:
def embedding_classify(query):
candidates = vector_search(query, k=3) # returns top-3
top1, top2 = candidates[0], candidates[1]
# Threshold 1: absolute confidence
if top1.score < 0.70:
return None # falls through to LLM
# Threshold 2: ambiguity gap
if top1.score - top2.score < 0.20:
return IntentResult(
intent="needs_clarification",
candidates=[top1, top2],
ask_user=True,
)
return top1.intent
Threshold 1, top-1 confidence, starting value: 0.75.
- Below 0.75 is mostly noise — push to LLM
- 0.75-0.85 is the embedding layer's sweet spot
- 0.85+ is almost certainly correct, return directly
Tuning direction: if production embedding-direct-return accuracy drops below 90%, push the threshold up to 0.80. If too many utterances get pushed to LLM (LLM coverage above 15%), drop to 0.70.
Threshold 2, ambiguity gap, starting value: 0.20.
- Gap below 0.20 → clarify with the user (multi-candidate clarification flow)
- Gap at or above 0.20 → return top-1 directly
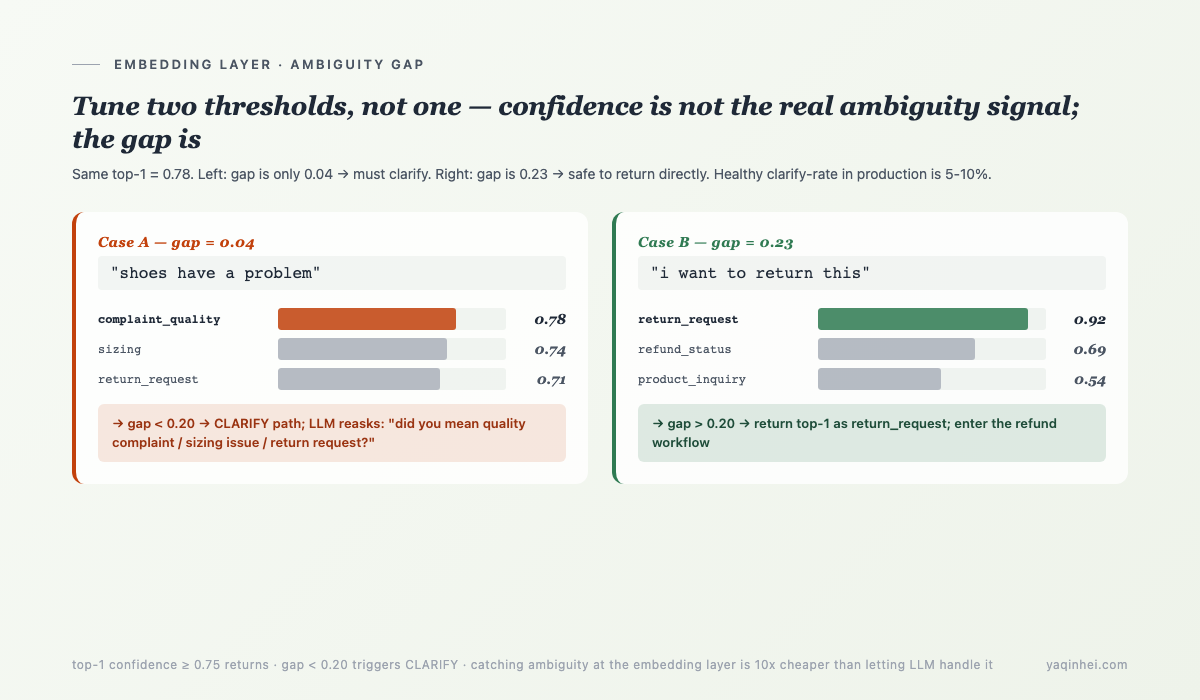
Most teams skip the gap check, and this is the embedding layer's biggest hidden bug. A real example:
User: "the shoes have a problem"
top-1: complaint_quality, score=0.78
top-2: sizing, score=0.74 ← gap is only 0.04
top-3: return_request, score=0.71
Without the gap check → force-return complaint_quality → workflow routes to complaint handling → user actually meant a sizing issue → wrong route, user yells, hands off to human.
With the gap check → trigger clarification → "did you mean a quality complaint / sizing issue / return request?" → user picks "sizing issue" → correct routing.
Clarification is not a UX loss — clarification trades "wrongly routed and then yelling" for "asked once and then completed." A healthy production clarify-rate sits at 5-10% — below 2% means you are swallowing ambiguity, above 15% means your taxonomy boundaries are broken.
One more thing about embedding: anchor-sentence quality determines vector-space quality. Prepare 5-10 "canonical phrasings" per intent (real user utterances, not SOP docs), embed and average-pool them as the intent anchor. Bad anchors and the whole layer's accuracy ceiling drops. That 1,102-sample / 59.44%-accuracy project earlier: the anchors had been pulled from policy documents, not from dialogue corpus.
Level 3 — LLM as fallback; the one critical thing is teaching it to say "unknown"
Rules don't match, embedding isn't confident — falls to LLM. The most important thing in this layer is not how pretty the prompt is — it is letting the LLM return unknown when uncertain, instead of force-picking.
90% of LLM intent-classification prompts look like this:
You are an intent classifier. Options: A, B, C, D.
User message: {message}
Return JSON: {"intent": "X"}
This prompt has a fatal default — it gives the LLM no escape hatch for "I don't know." When the LLM gets an utterance it can't classify (something like "could you maybe do that thing"), it will force-pick the closest option. The output is invisible in logs — the trace just shows {"intent": "return_request", "confidence": 0.6} — but the LLM is guessing.
A correct prompt has three pieces:
You are an intent classifier. Given a user message, output the intent.
Options:
- return_request: requesting a return or exchange
- refund_status: checking refund progress
- shipping_inquiry: checking shipping
- product_inquiry: asking about products
- complaint_quality: complaining about product quality
- unknown: cannot determine / not in this list
Rules:
1. Output only JSON: {"intent": "xxx", "confidence": 0.0-1.0}
2. When uncertain, confidence < 0.7
3. **Completely uncertain OR not in the list → {"intent": "unknown", "confidence": below 0.5}**
4. Do NOT invent new intent labels.
User message: {message}
Key design choices:
unknownis a first-class intent — the LLM is explicitly told "uncertain is a legal answer"- Strict enum — use Pydantic / function-calling / JSON schema so the LLM physically cannot return a label outside the list (parse failure → retry)
- Confidence tiering — treat any LLM output below 0.7 as unknown; don't trust force-picks
Production LLM-layer unknown rate should sit at 20-30%. Below 10% means the LLM is force-picking (your "accuracy" is fake). Above 50% means prompt design is weak or the taxonomy itself has gaps.
Two more must-do's at the LLM layer —
Temperature = 0. Intent classification is deterministic; you don't need creativity. At temperature 0.5 the same utterance returns different intents every time and your monitoring loses statistical meaning.
Timeout must fail-closed. LLM doesn't respond within 300ms → kick to clarification or human handoff. Don't default-allow. Same principle as Critic fail-closed in post III — timeouts mean the service is degraded, which is exactly when quality is unreliable. Force-picking an intent is far more dangerous than running clarification.
Starting-threshold cheatsheet — print this for your next review
The four sections above, compressed to one table. First launch / next review / internal review — match against this.
| Tier | Parameter | Starting value | Tuning direction |
|---|---|---|---|
| L1 Rule | Safety filter count | 8-16 | Missing PR/handoff → add rules; past 30 → audit |
| L1 Rule | High-freq intent rules | 8-12 intents, 3-5 patterns each | Coverage below 60% → see which high-freq intent has no rule; above 80% → audit for swallowed specifics |
| L2 Embedding | top-1 confidence | ≥ 0.75 returns | Accuracy drops → 0.80; recall drops → 0.70 |
| L2 Embedding | Ambiguity gap | < 0.20 → clarify | Clarify-rate below 2% = swallowing ambiguity; above 15% = taxonomy fuzzy |
| L2 Embedding | Anchors per intent | 5-10 real user phrasings | From dialogue corpus, not policy docs |
| L3 LLM | Confidence threshold | ≥ 0.7 accepted | Below 0.7 → treat as unknown |
| L3 LLM | Temperature | 0 | No creativity needed |
| L3 LLM | Timeout | 300ms | Timeout → fail-closed to clarification |
| L3 LLM | Unknown rate target | 20-30% | Below 10% = force-picking; above 50% = prompt or taxonomy issue |
| System | LLM coverage target | 5-10% | Above 15% = embedding underfilled |
| System | Overall unknown rate | 3-5% | Below 2% = forced guessing; above 10% = taxonomy gap |
Eleven parameters. That is the full pre-launch tuning checklist for a 3-tier fallback.
When 3-tier fallback hits its ceiling — the next move is LLM Router, not more tuning
3-tier fallback is the starting architecture. After it stabilizes, three signals tell you that you have hit v1's ceiling —
- Intent taxonomy past 40, mostly policy intents ("when do you refund" vs "how long does the refund take" vs "what's the refund process"), boundaries shifting weekly
- Embedding anchor-tuning runs through several rounds; marginal accuracy gains drop below +2pp and stop
- Multi-turn clarification demand keeps growing — incomplete utterances, needing to ask "which order do you mean," but v1 has no natural "ask-back" entry point
Any one of these alone is still tunable. All three together = v1 tuning has hit a ceiling, and the problem is in the intent model, not the thresholds.
I worked one project through this exact arc. v1 was textbook 3-tier fallback: 48 mutually exclusive intents (31 policy + 17 action + safety filter). 1,102-sample accuracy 59.44%. Anchor tuning across four rounds moved from 56.5% to 58.66% to 59.44%, then would not move. The underlying problem: "when do you refund" and "how long does the refund take" are the same question in user language. Forcing them into two mutually exclusive intents is engineering convenience, not user perspective.
v2 reframes to LLM Router — the LLM routes the message into 6 main paths:
ACTION → one of 17 workflow intents (refund / change-order / lookup / ...)
POLICY → goes straight to RAG (no intent-label KB filter)
SYS → system intents (anyone there / human-transfer copy / reset)
CLARIFY → LLM asks back (incomplete utterance)
UNKNOWN → fallback (none of the above)
ESCALATE → human handoff (PR risk / compliance / legal)
Inside ACTION the LLM picks one of 17 workflows. POLICY does not classify at all — it hands the message directly to RAG, erasing 31 hand-drawn policy-intent boundaries in one move. This is the key step: policy questions have fuzzy boundaries in user language anyway, and forcing classification introduces more error than convenience.
3-tier fallback is not retired — layer responsibilities are re-distributed:
| Layer | What it did in v1 | What it does in v2 |
|---|---|---|
| Rule | ~150 rules covering both policy and action | Shrinks to ~16 rules, only fast-path safety filters for high-frequency / high-impact actions |
| Embedding | top-1 ≥0.75 returns an intent | Exits policy classification; optional intra-workflow disambiguation under ACTION |
| LLM | 5-10% fallback coverage | Primary — all non-fast-path goes through LLM Router |
The two architectures side-by-side:

| v1 HybridClassifier (3-tier fallback) | v2 LLM Router | |
|---|---|---|
| Intent model | 48 mutually exclusive intents | 6 main paths + 17 workflows under ACTION |
| Policy handling | 31 policy intents + KB sub_topic filter | POLICY path → RAG directly, no intent label |
| Ambiguity | Force-pick top-1 → wrong route | CLARIFY path → LLM asks back |
| Rule layer | ~150 rules | ~16 safety filters |
| LLM role | Fallback (5-10% coverage) | Primary (all non-fast-path) |
| Multi-turn clarification | Not natively supported | Natively supported |
| p95 latency | 200-300ms | +200ms vs v1 (one more LLM call on the critical path) |
| Per-turn LLM cost | ~$0.0001 | ~$0.0005 (5x) |
| Right stage | Intents ≤ 30, corpus still moving | Intents 40+, corpus stable, multi-turn clarification needed |
v2's cost: one more LLM call per turn (qwen-turbo-class lightweight model adds ~200ms). First-token latency climbs from ~600ms to ~800ms — still inside the 1-second user-perception threshold. Per-turn LLM cost lands at ~$0.0007 — at 1,000 turns/day, that's about $2/day, negligible.
v2's wins:
- Policy intent boundaries vanish — 31 artificial cuts deleted, let RAG do its job
- Ambiguous cases get LLM clarification — no more force-picks, UX feels "more like talking to a person"
- Rule maintenance surface drops from ~150 to ~16 rules — engineering load collapses
- Multi-turn context + user history + current query are combined — instead of single-utterance hard classification
The critical engineering discipline: v2 cannot be switched in directly. The new router must run shadow alongside the old classifier — the shadow router writes to its own independent Langfuse trace (joined to the main trace by session_id), without affecting product output.
Why an independent trace and not metadata on the main trace? Because in handler.py's finally block, after trace.end(), the OTel exporter rejects writes. Slow shadow LLM calls (200-2000ms) using fire-and-forget tasks fall on the floor — and the bias is structural: shadow data on slow calls disappears, fast-call shadow data lands. That bias is statistically fatal — it will make you conclude "v2 is about the same as v1" when in reality you only kept the easy cases. An independent trace manages its own end() and flush(), decoupling timing.
Run shadow for a week. Ramp to canary based on three UX signals:
- S1: fraction of conversations where v1 force-picked top-1 but v2 took CLARIFY (how many of v1's wrong-route cases v2 saved)
- S2: fraction where v1 routed to the wrong workflow (high downstream handoff rate) but v2 routed correctly
- S3a: an out-of-family LLM judge (Kimi / DouBao / etc.) preference rate on v1 vs v2 outputs, with 30-sample calibration ≥ 70% agreement
If your team is still on v1, make the 3-tier fallback tuning solid first. Below 30 intents, v1 is plenty. Jumping to v2 prematurely burns money. Past 40 intents + anchor-tuning gains dropping below +2pp + strong multi-turn clarification demand, all three together — then it's time for v2.
Cache is the load-bearing piece for high concurrency — not an optimization
If your customer-service Agent handles >5,000 conversations/day, cache is not an optimization, it is a launch prerequisite.
Intent classification is inherently cache-friendly — many openings and short questions are highly repeated. "Hi" / "anyone there" / "I want to return this" / "where is my order" — a single Agent may see these hundreds of times a day. Hitting the LLM every time is burning cash.
import hashlib
from redis import Redis
def cache_key(message):
# Simple normalize: lower + strip + remove punctuation
normalized = message.lower().strip().replace("?", "").replace("!", "")
return f"intent:{hashlib.md5(normalized.encode()).hexdigest()}"
def classify_with_cache(message):
key = cache_key(message)
cached = redis.get(key)
if cached:
return IntentResult.from_json(cached)
result = three_tier_classify(message) # 3-tier fallback
if result.intent != "unknown": # only cache confident results
redis.setex(key, ttl=86400, value=result.to_json())
return result
When cache hit-rate gets to 30-50%, total cost drops by half, p95 latency drops by 2/3. Three things to watch:
- Only cache confident results — never cache
unknown/clarify, otherwise the user gets re-asked every time - TTL can't be too long — taxonomy evolves (v1 36 → v2 48 intents); cache shouldn't pollute across versions. 1-day TTL + explicit flush on taxonomy change is stable
- Never cache write-operation context — cache is safe for "what intent" but not for "which tool with what parameters"
A real number: a project at 10K conversations/day went from $1,100 LLM monthly to ~$500 after caching — 45% hit-rate.
Five red flags — what should kill an architecture in review
The next time a vendor pitches their intent-classification design, five red flags —
Flag 1: "We just use an LLM for classification, simple and reliable." Ask about high-concurrency monthly cost + whether they have safety filters + whether they have shadow validation. All three answered = they may actually be doing v2 LLM Router (acceptable). Just "we call the LLM" = likely a six-figure-bill incident inside 1 month + PR fast-path leakage. LLM Router differs from "naked LLM classification" exactly on these three points.
Flag 2: "We use 100% rules, fully controllable." Ask how many intents and how many rules. Intents > 30 with rules > 80 = already in maintenance hell, the next team will rewrite it.
Flag 3: "Our embedding threshold is 0.5, we return directly." 0.5 is basically noise level in vector space — most similarities are above 0.5, so this is effectively no threshold at all. Accuracy is worse than pure rules.
Flag 4: "Our LLM unknown rate is 0." Equivalent to "the LLM is force-picking." Ask "what does the LLM do with messages it doesn't recognize?" — answer "it returns the closest match" → this is the problem.
Flag 5: "We don't cache." At >5K conversations/day, mandatory. Without it, cost scales by 1/hit-rate.
One of these in a vendor pitch → major rework. Two or three → the architecture won't survive long. Four or more → reject the pitch and send them back.
11 things to do this week
- Diagram your current intent-classification flow — is it 3-tier fallback? Which tier is missing?
- Run a baseline — coverage by tier on 1,000 real conversations, compared to 60 / 30 / 10
- Add 8-16 safety filters (12315 / human / consumer-protection / legal-threat / public-exposure goes through rules)
- Add an ambiguity-gap clarify branch on the embedding layer (top-1 minus top-2 < 0.2 → ask back)
- Add an
unknownoutlet + strict enum (Pydantic / function-calling schema) to the LLM prompt - Set LLM temperature to 0; timeout 300ms; timeout → clarify, don't force-pick
- Cache classification results for high-frequency utterances — same utterance returns instantly
- Log every classification's source (rule / embedding / llm / cache); review the distribution daily
- Add accuracy monitoring per intent (out-of-family LLM-as-judge with calibration set)
- Have fallback ready: LLM timeout / error / low-confidence → human handoff or clarify, never guess
- v1 → v2 evaluation: count current intents / anchor-tuning marginal gain / policy-boundary edit frequency / multi-turn clarification demand — all four past threshold → start shadow-deploy evaluation, otherwise keep tightening v1
Six questions for vendor reviews — when they claim "90% intent accuracy"
Question 1: "What are the three tier coverage percentages?" Acceptable: 60/30/10 range. "Only LLM" / "Only rules" → red flag. "We don't tier" → giant red flag.
Question 2: "What's the embedding threshold, and how do you handle ambiguity gap?" Can't answer / below 0.7 / no gap handling → accuracy isn't where they claim. Acceptable: top-1 ≥ 0.75 returns + gap < 0.20 clarifies.
Question 3: "What's the LLM unknown rate?" Answer "0" → LLM is force-picking. Answer "20-30%" → normal. This is the most cutting question — most vendor decks don't even track it.
Question 4: "What's the intent cache hit-rate?" "We don't cache" → cost will blow up. Acceptable: 30-50% hit-rate + 1-day TTL.
Question 5: "How is the 90% accuracy computed — sample size / judge / does it include unknown?" This question comes from containment vs resolution in post V and dual-track testing in post VII — a 90% you can't explain is no 90%. Acceptable: weekly sample of 200-500 + out-of-family LLM judge + calibration set + unknown recall computed separately.
Question 6 (advanced): "v1 or v2 architecture, and how is shadow deployed?" Ask which: HybridClassifier or LLM Router; whether shadow is written to main-trace metadata or independent trace; how long shadow ran; what UX signals decide canary. "We don't do shadow, we cut over directly" = high risk. "Shadow writes to main-trace metadata" → statistically biased, the conclusion is unreliable. Acceptable: independent trace + ≥ 1 week shadow + ≥ 2 UX signals + out-of-family judge calibration.
Closing — intent classification is the foundation; the building falls if the foundation breaks
Over the past year I have watched too many customer-service Agent projects buy the most expensive model, write the longest prompt, stack RAG with three layers of reranking — and lose all of it because the first step, intent classification, was wrong.
Wrong intent → wrong workflow routing → Critic auditing the wrong action on the wrong path → write operations hitting the wrong tool → dashboards green but production users keep getting routed wrong.
The engineering value of intent classification is not in the algorithm; it is in the trade-off — 60% of traffic on the cheapest layer, 30% bounded by embedding for ambiguity, 10% on LLM for the long tail. Three numbers, eleven tuning parameters, three dead-ends to avoid.
If your team's plan is any of "just use LLM" / "100% rules" / "embedding 0.5 returns directly" / "LLM unknown 0%" / "we don't cache" — print this and send it back for a rewrite.
Get the toolkit
If you want to take this straight into your next architecture review or threshold-tuning session, I've packaged a PDF kit:
Send me the keyword "INTENT TRIANGLE" and I'll send the pack:
- 3-tier fallback tuning sheet (11 parameters + starting values + tuning direction)
- 5 red flags + 6 review questions (vendor-pitch evaluation, includes v1/v2 architecture)
- Safety filter 8-16 starter pack (filled in for English customer-service domain)
- Embedding ambiguity-gap clarification flow template (with reask copy)
- LLM intent-classification prompt template (unknown / strict enum / fail-closed timeout)
- v1 HybridClassifier → v2 LLM Router upgrade evaluation checklist (4 upgrade signals + shadow deployment checklist + UX signal definitions)
(Channels in the footer — X or email both work.)
Coming next in this series
The next deep-dives —
- Connecting LLMs into enterprise SaaS: 25 APIs → 5 tools, contract and idempotency (deep-dive on Decision 4 from post II)
- Chinese intent taxonomy evolution: from utterance corpus to codebook, the actual v1 36 → v2 48 evolution, plus shadow-deployment field notes on v2 LLM Router
- Enterprise LLM Agent failure compendium: async ES blocking the event loop / Critic timeout fallback misuse / proxy intercepting localhost / intent rename across 7+ files / KB-ES desynchronization
If your team is shipping an L2 customer-service Agent or any other write-operation Agent that needs intent classification, those three are coming next.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.