Make the Agent Get Sharper With Use, Not Dumber — Spinning Up the Data Flywheel

Post #6 of the After Launch series (finale). The first five: sampling, labeling volume, label reliability, the launch gate, silent drift. This one connects them into a self-improving loop. 中文版:让 agent 越用越准,而不是越用越笨。
The first five posts covered getting an agent shipped and guarding it against quietly getting dumber. But that's all "defense." This one is "offense" — turning every bad case into fuel for the next version, so the agent gets sharper with use.
Here's a real example. In labeling we found that when back-to-school hit, "student promo" questions spiked; but slice it finer and one class — "does my purchase come with a gift, how do I claim it" — was never answered well. Not the occasional miss, this class systematically missed the point. So we touched nothing else and fixed just this: completed the KB, wrote the script clearly. Next round, this class's accuracy climbed.
That's the data flywheel at its plainest: labeling doesn't just tell you "right or wrong," it tells you "where it most needs fixing" — then you fix it there, so the agent gets sharper, round by round, exactly where real users hit the wall.
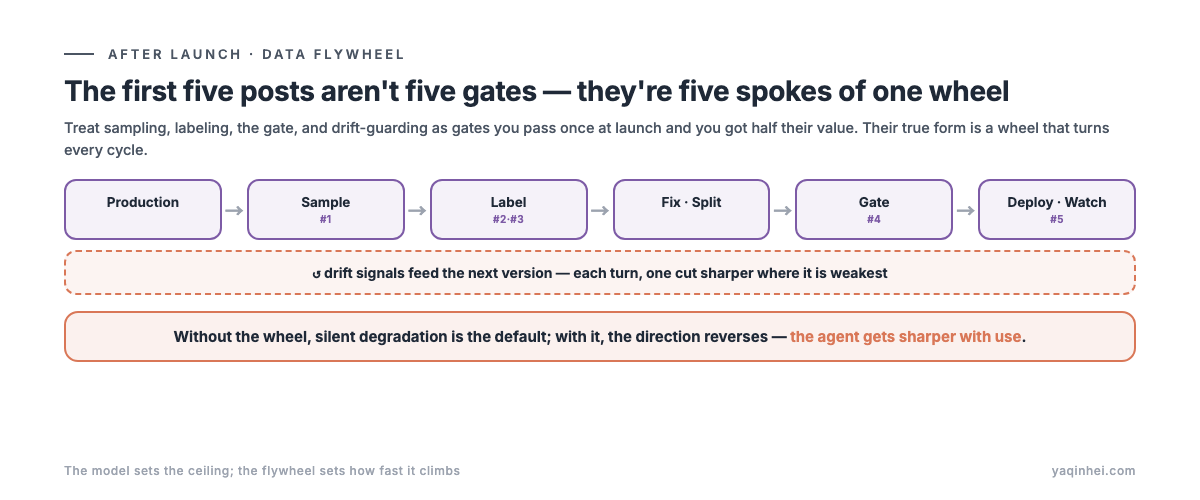
The first five posts aren't five gates — they're five spokes of one wheel
Sampling, labeling, evaluation, the gate, drift-guarding — if you treat them as five gates you walk through once at launch, you got half their value. Their true form is a wheel that turns every cycle.
Production traffic → sampling (#1 draws what to look at) → labeling (#2/#3 enough, reliable) → locate the weak spots, fix → the gate (#4 decides if it can go) → deploy → watch drift (#5 catches new problems) → feed back into the next version. Every turn, the agent gets one cut sharper where it was weakest.
Without this wheel, the silent degradation from post #5 is the default outcome (the world moves, the agent doesn't); with it, the direction reverses — the agent gets sharper with use.
The fuel is already collected — you just haven't used it as fuel
The flywheel's intakes were all built in the earlier posts — unknowns, disagreements, blocks, low accuracy, each telling you "what to fix next round."
- New phrasings recurring in the unknowns → an intent worth adding (see intent codebook evolution)
- The class where labeling disagreement concentrates → a rubric gap (see post #3)
- Intents where Critic blocks / wrong-actions concentrate → a high-risk hard case (see post #4)
- A class with systematically low accuracy (like the back-to-school gift) → a KB / script to complete
None of these need new instrumentation — the earlier posts' outputs are the intake. The trick is turning them from "a report" into "a to-do": every signal maps to a concrete "fix this next round," not another dashboard no one acts on.
Volume doesn't mean fixable: the flywheel also forces you to split intents
The flywheel doesn't just add data — it also tells you that some intents you have to split open before you can fix them.
Another real example. Our "order" questions were huge in volume, but accuracy just wouldn't climb. At first we thought we hadn't labeled enough, the KB was thin; split it open and the problem was that "order" itself was a grab-bag — mixing order cancel, order status, order refund, order return… each large in volume, and each with a completely different correct answer, API to call, flow to run. Answering with one vague "order intent" is opening four locks with one key — none turns cleanly.
Split into four intents, each with its own KB, its own thresholds, its own gate, and accuracy climbs on each front at once. Past a certain point, the flywheel's marginal return on more data drops; then the signal it gives isn't "label more," it's "this intent is too coarse — split it." The intent taxonomy isn't frozen at launch; it's grown, round by round, by the flywheel forcing it.
The most common way a flywheel dies: spinning in place
Most teams' flywheel isn't not turning — it's spinning in place: bad cases pile into a mountain, report after report goes out, yet none of it becomes the next shipped version.
The root cause of spinning in place is almost never technical — it's ownership. Who has the authority to decide "this batch of new phrasings in the unknowns is a real new intent worth adding"? Who has the authority to promote a completed KB, a revised prompt, to production? The moment those two "who"s read "TBD," the intake can be perfectly smooth and the data still just rots in the backlog. This is the same thing the org-structure post said: a stalled agent project is 90% not a tech problem, it's that no one owns the chain.

Detection move: pick any bad case found last week and ask — "where is it now? Who is responsible for turning it into a change in the next version?" If you can't name a specific person plus a specific next step, your flywheel is spinning in place.
Three things you can do this week
- Wire one leading signal into a to-do. Pick the intent with the highest unknown rate or lowest accuracy — don't just watch the report; name a person to own "fix this next round."
- Take one high-volume, stuck-accuracy intent and try to split it. Like "order," check whether it's a grab-bag; splitting it into a few separately-fixable sub-intents often beats labeling another 500 rows.
- Give the flywheel an owner and a cadence. Who declares new intents, who promotes fixes, how often it turns (say, every two weeks). A flywheel with no owner and no cadence will spin in place.
Connect the first five posts: sampling lets you see the real problems, labeling gives you a trustworthy answer key, evaluation and the gate let you ship without fooling yourself, drift-guarding catches degradation in time — and the flywheel is the axle that connects all of it into a self-improving system. The model sets the agent's ceiling; the flywheel sets how fast it climbs. An agent without a flywheel, at best, stalls at its launch-day level and then gets dragged down by drift; an agent with the flywheel turning gets sharper, round by round, right where real users hit the wall — sharper with use, not dumber.
That's the whole of After Launch: launch isn't the finish line, it's where this machine starts to turn.
If this made you decide to pick a bad case and name an owner to get the flywheel turning, send me the keyword "FLYWHEEL KIT" and I'll share the intake checklist + the signals for when to split an intent + a flywheel cadence template.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.