自助率 ≠ 做对率:上线前到底卡哪几道闸|Agentic AI 落地方法论(十三)

《Agentic AI 落地方法论》系列第十三篇。 前 12 篇拆「系统怎么建对、组织怎么配齐」——L0-L3 定级、L2 vs L3 架构决策、Critic fail-closed、上线即放养、接住率 vs 解决率、Skills vs 知识库、双轨测试、3 级 intent 级联、五层 API 架构、Intent codebook 演进、第二个 Agent 当审稿人、组织架构图才是真正的架构图。第五篇定了「该追哪个指标」,这一篇接着拆上线和提量之前,那个指标到底卡几道闸、怎么算、怎么标、怎么自动停。English version: Self-Serve Rate ≠ Correct Rate — The Gates a Customer-Service Agent Must Clear Before Launch.
老板会上那句「自助率到底要 65 还是 90」,问错了
灰度跑了两周,准入会上老板问了一句听起来很合理的话:「这个 agent 自助率到底要做到多少才能放量——65 还是 90?」
我没法直接回答。不是数字没出,是这个问题把两件不同的事塞进了一个数字里。
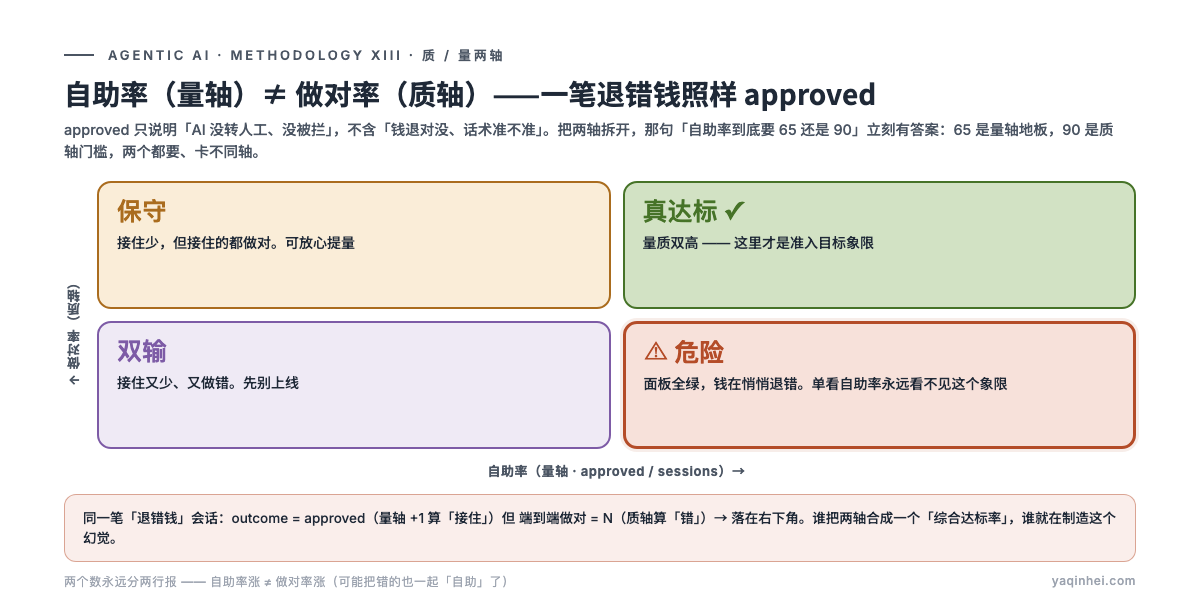
我把面板拉出来:自助率 67%。看起来达标了。但我同时翻出当周一笔会话——agent 给一个本该转人工的差价退款直接退了款,金额还退多了。这笔会话在面板上的状态是什么?approved。没转人工、没被拦截,于是它被算进了那 67% 的「自助」里。
一笔退错钱的单子,照样是「自助成功」。
那个 67% 回答的是「AI 接住了多少量」,老板心里想问的其实是「接住的这些,做对了几成」。两个完全不同的轴,被一个百分比糊在了一起。这一篇拆四件事:为什么准入不是一个数、9 道闸怎么分三层、硬红线为什么只有两条而且要自动停、做对率为什么必须人标——以及下次准入会上能拿哪 5 个问题,把虚假的绿勾当场问穿。
「65 还是 90」是伪命题——它问的是两个正交的轴
先把结论摆桌面上:自助率和做对率是两个正交的轴,一个量、一个质,必须分开报、卡不同的线。
- 自助率 = approved / sessions——AI 没转人工、没被拦截的会话占比。这是量轴,回答「接住了多少」。它来自
outcometag 的扁平化,不含「钱退对没、话术准不准」的任何判断。 - 做对率 = 接住的部分里,判断 + 执行 + 话术都对的占比。这是质轴,回答「接住的做对了几成」。它机器算不出,必须人判。
把这两个轴叠在一起,那句「65 还是 90」立刻有了答案:AI 接住 ≥65% 的量,且接住的部分做对率 ≥90%。65 是量轴的地板,90 是质轴的门槛,两个都要。
最反直觉的一点在上报纪律:自助率涨,不代表做对率涨。优化「让对话别转人工」太容易了——LLM 把一个看起来合理的兜底答案塞过去,自助率就上去了,但很可能把错的也一起「自助」了。所以这两个数永远分两行报,谁把它们合成一个「综合达标率」,谁就是在制造那个 67% 的幻觉。
检测信号: 听到任何「自助率 95%」「自动化率 90%」式的单数字汇报,回一句——「这是 approved 还是真做对了?给我两个数。」答不出第二个数,第一个数就只是「没转人工率」。
上线准入不是一个数,是 9 道闸分三层
单一指标过线就上线,是把一个多维问题压成一维——准入得是一张分层的门槛表,先分清哪些机器自己出、哪些必须烧人工标。
我把 9 项门槛按「怎么算」分成三层,这层划分直接决定了你下周准入会上能交什么、不能交什么:
- A 层 · 机器实时算(6 项): P95 延迟、写操作兜底率、读类兜底率、操作可追溯率、重复退款数、误执行数。这些从可观测平台(Langfuse 之类)、写操作审计表(
agent_actions)、OMS 退款台账直接出,不需要人。 - B 层 · 业务抽样标注(2 项 + 1 辅): 4 场景做对率、误拒率,外加一个辅看的政策做对率。机器只能给候选,对错必须人判。
- 两个口径陷阱: ① approved ≠ 做对(上一节已拆);② 红线在 mock 下空转(下一节拆)。这两个不是指标,是会让前面 8 项数字全部失真的坑。
为什么这层划分是准入的核心?因为它把「下周能交的」和「下周交不了的」一刀切开:A 层接通埋点当天就能出趋势,B 层得先有标注流程 + 校准集才有数。混在一起报,老板以为「9 项都有数了」,实际一半是机器糊出来的占位。
还有一条容易漏的规矩:质量指标逐场景独立看。提比例看最弱场景——4 个灰度场景全过才提,不是平均过了就提。任一场景触红线,只停那个场景的 workflow,不是整个 agent 下线。而基建不变量(兜底率、可追溯率必须 100%)是全局的,只在出违例时定位是哪个场景的锅。

硬红线只有两条,但触线即自动停
九门槛里只有两条是「触线即停、不进会讨论」的硬红线——误执行 = 0、重复退款 = 0。其余全是软的。
- 误执行:不该执行却执行了的写操作数。
- 重复退款:同一笔订单退了 ≥2 次的单数。
这两条的阈值不是「≥90%」这种范围,是冰冷的 =0。任一不为 0,触发自动 kill switch 停掉该场景 workflow(翻 thresholds.yaml 里的场景开关),不等准入会、不等下个迭代。1 笔灾难性误放 = 立即停 + 复盘。
为什么只有这两条配「硬」字?因为它们碰钱、且不可逆。做对率差 3 个点是迭代问题,下个版本修;误执行多 1 笔是资损事故,已经发生了。「硬红线」的定义就是触线即停,否则这个「硬」字是空的。
这里有一个绝大多数团队会踩的测量陷阱:重复退款必须对账 OMS 台账,不能用 agent_actions 自连接。
最危险的重复退款长这样——agent 退了一次 → 转人工 → 人工又退了一次。agent_actions 只记录 agent 自己这条腿的动作,看不见人工那条腿(handoff 之后人工的操作不回写到这张表)。你拿 agent_actions self-join 去查重复,永远抓不到这种「一台机一个人各退一次」的真重复。
正确做法:对每一笔 agent 写操作,去查 OMS 里该订单的退款台账(含人工 + agent 的全量记录)——此前是否已退过、是否超限、金额对象是否错。预防端的去重规则本来就是这么查的(读 OMS 该单的 refund_history),测量端必须跟上同一张台账,否则预防比测量还严,等于自己骗自己。

检测信号: 看见「重复退款 = 0」先问一句——「你拿什么对的账?agent 自己的审计表,还是 OMS 全量退款台账?」前者,这个 0 是假的。
mock 下的红线是空转的——别给整块红线打绿勾
红线生不生效,取决于这个场景的真实接口接没接通。mock 下跑出来的「= 0」,是假的安全感。
灰度阶段一个常态:部分场景已经切了真实接口,部分叶子节点还在等接口、临时挂 mock。这时候红线的「在线」状态是分裂的:
- 已接真接口的场景 → 红线已生效、可测(对账的是真实退款台账)。
- 接口未接通的叶子节点 → fail-closed 转人工(这是安全降级,不是空转)。但要注意——红线「= 0」在这种场景上,是靠「全转人工所以根本没执行」兜出来的,不是靠对账验证出来的。
这两种状态的「= 0」含金量天差地别。一个是「测过了,没误放」;一个是「还没真正放过,所以也没误放」。
所以诚实的口径是:红线状态逐场景标——每个场景标清楚是「已生效 / 可测」还是「降级转人工 · 待接口」。既不给整块红线打一个笼统的绿勾,也不笼统地说「全在空转」,按每个场景接口的接通度如实报。
为什么这条这么要命?因为给老板一个笼统的「红线全绿」,等接口接通那天才发现这个场景从没真正对账过——而那一天,正是流量已经放上去、最不该暴露问题的时间点。
检测信号: 准入会上指着「红线全绿」问——「哪几个场景是真对账了,哪几个是接口没通、靠转人工兜的?给我逐场景的状态。」给不出逐场景清单的绿勾,不算数。
做对率必须人标,而且标注一致率得先超过闸门精度
做对率是质轴,机器给不出。但在烧人力开标之前,得先证明「两个人标同一通会标成一样」——否则你的闸门卡的是标注噪声,不是模型质量。
标注不是从零干。机器先预填:trace_id / session_id / scenario / outcome / 命中的规则 / 对话原文 / 步骤链 / 关联的 agent_actions 行。人只填判定列——意图判对没、动作选对没、执行结果对没、话术合规没、端到端做对没、该不该执行、拦截判得对不对。单条 1–2 分钟。
关键在标注一致性,分三层守:
- 校准集先行。 上线前业务 + QA 双标 ~30 通,算一致率(Cohen κ)。一致率必须高于闸门精度——你要守「做对率 90%、误差 ±5%」,那两个标注员的一致率就得 ≥90%。不达标说明评分卡本身有歧义,先改卡,再开标。
- 红线项强制双标。 每一笔「该不该执行」「拦截判得对不对」都两人独立标,分歧由业务终判 + 留痕。这两列直接喂硬红线,错一个标注就是错一个 kill switch 判断。
- 大盘 10% 持续双标。 一致率掉了就停下来重新校准。
还有一条报数纪律:报数误差 = 抽样置信区间 + 标注分歧,两部分都得算。你报「做对率 90%」,下一版「88%」,很可能纯属抖动而不是退步。灰度量小的时候,率和绝对数一起报——「误拒 1/40」比「2.5%」诚实得多。
谁标也有讲究:业务方主标「执行结果对」「该不该执行」「拦截判定」(他们懂政策、限额、品牌口径),QA 辅标「意图判对」「话术合规」(对着判定卡和禁用词表,相对客观),分歧业务终判。
检测信号: 听到「做对率 90%」,问——「标注一致率多少?跑校准集了吗?」答不上来,这个 90% 大概率是单人主观打的分,换个人标可能就 80%。
软指标差一点,不该一刀切回退
闸门后果分三级——硬红线自动停,基建正确性先修再上线,软指标只冻结提量、不回退。
| 类别 | 指标 | 触线后果 |
|---|---|---|
| 硬红线 | 误执行 ≠ 0 / 重复退款 ≠ 0 | 自动 kill switch 停该 workflow,不进会 |
| 基建正确性 | 可追溯率不足 100% / 写兜底不足 100% / 读兜底不足 100% | 视同红线——这是 bug,先修再谈上线 |
| 软指标 | 做对率不到 90% / 误拒率超 5% / 自助率不到 65% / P95 超标 | 不自动停:① 冻结提比例 ② bad-case 闭环 ③ 拍板会复审。维持现档不回退(除非同时触红线) |
这套分级背后是一条逻辑:硬红线的定义就是「触线即停不商量」,否则「硬」字是空的;而软指标差一点就一刀切回退,会直接打击迭代——团队会为了不掉档而不敢改 prompt。冻结提量 + 修 bad case,才是正循环。
顺带说一个老板会很买账的细节:两套兜底机制方向是反的。碰钱的写操作一坏(critic 超时 / 工具失败 / 订单写失败)→ fail-closed 转人工;查问题的读类一坏(分类失败 / 检索失败)→ fail-open 给安全兜底话术,绝不瞎编、不空响应、不甩报错页。
跟老板讲「碰钱的事一坏就转人工,查问题一坏就给安全兜底绝不瞎编」,比笼统一句「100% 转人工」既准确又更有说服力——后者对读类根本是假的,读类要是也「一坏就转人工」,人工台会被瞬间淹掉。

灰度量小,先把样本堆到每场景 ≥50 再首评闸
「下周给数」不等于「下周拍上线」——样本不够,闸门判定就是抛硬币。
抽样原则一句话:写操作全量、读类抽样、异常必含。
- 写操作(资损动作)= 全量 census。 4 个灰度场景全是写动作,逐笔人工复核——误执行 = 0、重复 = 0、误拒 ≤5% 这种红线,只能靠全量,抽样会漏掉那一笔。
- 读类政策流量 = 分层抽样(按意图 × outcome 随机)。
- 全部 blocked + escalated 必含——量小但信号最强,误拒、误转都藏在这。
- bad-case 过采样:带失败规则标记、high risk、情绪激动、低意图置信度的,一律纳入。
过闸的最小样本量按二项分布 95% 置信区间算:每场景 35 通 → ±10%,70 通 → ±7%,140 通 → ±5%。先到每场景 ≥50 再首评闸,报点估计必须带置信区间。按灰度的真实流量,堆够样本可能要 2–3 周。
所以准入会上最该说清的一句:「下周交的是趋势 + 红线实时状态,不是上线判定。」 别让「下周给数」被理解成「下周拍上线」。提比例也一样——第一轮 UAT 过了之后,由测试 + 业务 + 后端按框架数据拍「提到下一档」,不直接跳满。
准入会上能问穿绿勾的 5 个问题
这一篇的检测工具,浓缩成准入会上能直接念的 5 句:
- 「这个自助率是 approved 还是真做对了?给我两个数。」 —— 拆量轴和质轴。
- 「误执行、重复退款这两条红线,现在是真对账了,还是接口没通靠转人工兜?逐场景说。」 —— 拆 mock 空转。
- 「重复退款拿什么对的账,agent 自己的表还是 OMS 全量台账?」 —— 抓 self-join 盲区。
- 「做对率谁标的?标注一致率多少?跑校准集了吗?」 —— 戳标注噪声。
- 「下周给的是趋势还是上线判定?每场景样本到 50 了吗,带置信区间吗?」 —— 把「给数」和「拍上线」分开。
这 5 个问题的共性:逼汇报的人把一个糊在一起的漂亮数字,拆回它本来的多个维度。能问穿这 5 条,准入会就不会再被一个 67% 的「自助率」带着走。
下一篇拆一个更扎心的工程事故:KB 改了 61 条,线上索引却 9 天没更新,测试反馈的一堆问题全是同一个根因——你以为发布了,其实没有。
回复关键词「上线闸门」,我把这套《Agent 上线准入看板自查表》发给你:9 门槛三层划分 + 硬/软/基建后果分级 + 标注校准 checklist + 准入会 5 问,一页能贴在准入会白板上。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.