What a Real, Money-Moving L2 Refund Workflow Actually Looks Like | Workflow Deep Dive

WORKFLOW DEEP DIVE. An engineering deep dive. The second post in Agentic AI in Practice set the rule — money-moving write operations must be built as an L2 deterministic workflow, not handed to an L3 autonomous planner. That post argued the "why"; this one shows "what that workflow actually looks like built for real": a small-refund workflow growing from a linear 8 steps into a branching tree, and the designs that let it ship. The companion fail-closed Critic and pre-launch gates are in the series. 中文版:一个真的会动钱的 L2 退款 workflow,长什么样.
Opening: that linear 8-step line read too clean
The current small-refund workflow is a linear 8 steps. The code reads comfortably:
# app/workflows/small_refund.py — linear version
STEPS = [
KillSwitchStep(), # 1. master switch; off → straight to a human
CheckParamsStep(), # 2. are the params complete
QueryOrderStep(), # 3. fetch order facts
ValidateStep(), # 4. amount threshold / time window / dedup
CriticCheckStep(), # 5. LLM Critic semantic review
ConfirmCardStep(), # 6. confirmation card (pause / resume)
ExecuteRefundStep(), # 7. actually call the finance API
ConfirmStep(), # 8. notify the customer, persist
]
A straight line from "should we refund" to "refunded." Demo it for the business side, nobody objects — it does run one cleanest-case refund.
I opened this file meaning only to add one branch: price-difference refunds. It turned out not to be an "add one branch" job.
The business laid out the real requests: a refund isn't one thing, it's a family — shipping fee, price difference, compensation, defect, quality — five request types; users come from a private channel (own membership) and public channels (third-party marketplaces), with different rules and different settlement systems; and half the external systems weren't wired yet. That clean straight line couldn't hold any of it.
This post is that line becoming a shippable branching tree. The most counterintuitive finding, up front: a workflow that really moves money is mostly not refund code — it's not-refund code.
1. Why the linear version ships, yet can't hold real requests
The linear version runs because it assumes the narrowest world: one channel, one request type, one settlement system. Its skeleton is standard — each step is a WorkflowStep returning a StepResult telling the orchestrator where to go next:
# app/workflows/base.py
@dataclass
class StepResult:
output: dict # facts this step produced
next_step: str | None # name of the next step; None = workflow ends
message: str | None # words for the user
tool_used: str | None # which tool was called (for audit)
class WorkflowStep(ABC):
@abstractmethod
async def run(self, ctx: Context) -> StepResult: ...
Look at next_step — it's the key to this being "deterministic" rather than "autonomous." Where to go next is returned explicitly in code by each step, not decided by the LLM reading the conversation. This is exactly the boundary the L2 vs L3 post hammers on: the LLM may make a semantic judgment within a step (a Critic, say), but "how the whole path runs" must be deterministic, testable, enumerable.
The linear version's problem isn't the skeleton — it's that there's only one path. The moment real requests arrive, there's more than one.
2. Real requests tear the line into a tree
Five request types × two channels isn't a simple 5×2, because each cell's rules differ. A private price-difference goes to a dedicated price-diff system; among public price-differences, "return-and-rebuy" goes to a human while "item price drop" goes to a platform branch; compensation in the private channel is issuing a coupon (not a refund at all), and in the public channel it settles down two paths depending on amount paid…
So the linear 8 steps must split, in the middle, into a tree:
kill_switch
→ gate_common ← complaint / delayed shipment / account mismatch / blacklist / already refunded → human
→ query_order ← private / public, two query paths
→ route_mode_scenario ← branch by channel + request
private: fee | price_diff | compensation
public: fee | price_diff | defect | quality
→ [sub-scenario chain] collect image? → recognize? → scenario_validate → limit_check
→ critic_check ← before any write
→ confirm_card ← second confirmation
→ execute_by_system ← each leaf settles to a different system
→ confirm
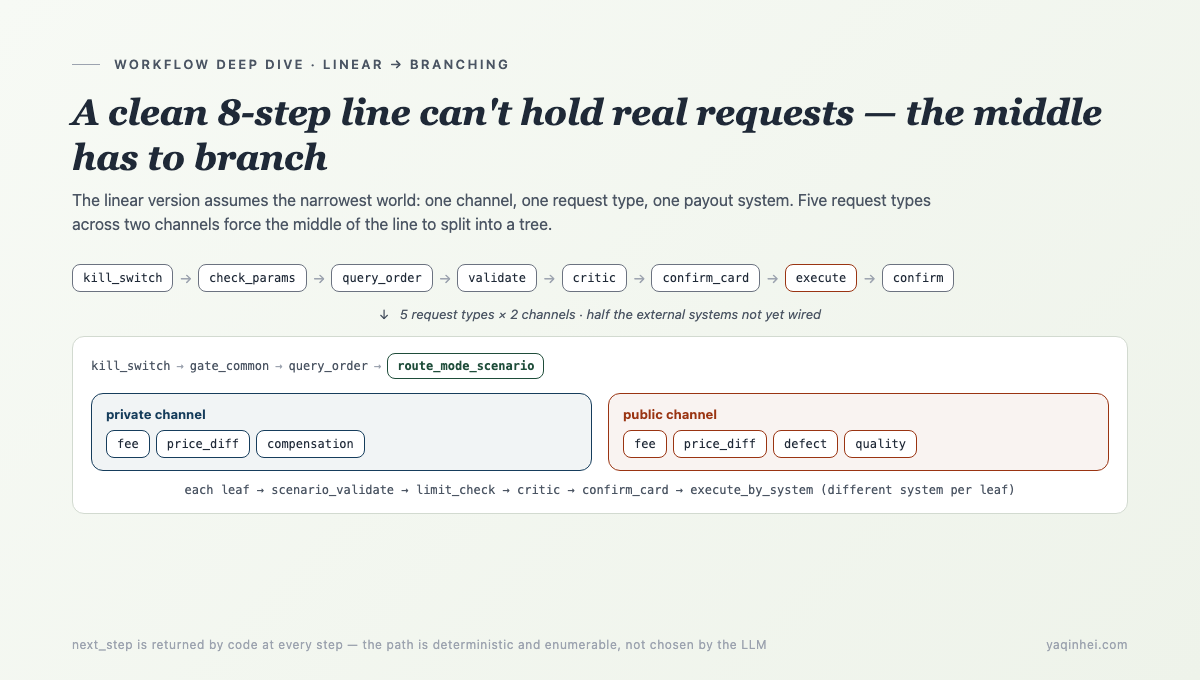
The split happens at route_mode_scenario — it reads channel and request and returns a different next_step:
class RouteModeScenarioStep(WorkflowStep):
async def run(self, ctx):
source = ctx.order["source"] # private | public
scenario = ctx.classified_scenario # fee | price_diff | compensation | defect | quality
branch = ROUTE_TABLE.get((source, scenario))
if branch is None:
return StepResult(output={}, next_step="transfer_to_human",
message=None, tool_used=None) # no matching branch = human
return StepResult(output={"branch": branch}, next_step=branch,
message=None, tool_used=None)
Note that final if branch is None — any combination with no explicit branch defaults to a human, not to "guess the closest one." That default is the keynote of the whole design.
3. Count the nodes and you see it: most steps aren't refunding, they're not-refunding
Color each node on this tree by job and one counterintuitive thing appears.

The only node that actually "moves money out" is execute_by_system. In front of it stands a long row of steps that each do one thing — decide whether to get to it:
kill_switch: is this scenario even turned ongate_common: any complaint, account match, blacklist, already-refundedroute_mode_scenario: does this combination have a legal branchscenario_validate: are this sub-scenario's specific conditions metlimit_ledger_check: has cumulative refunding hit a capcritic_check: does this write hold up semanticallyconfirm_card: did the user confirm
Seven judgments, one payout. In a money-moving workflow, payout is the minority — eight-tenths of the code answers "should we refund," two-tenths does "refund."
For an architect, the point isn't "code-volume distribution," it's: to judge whether a refund Agent is sound, don't look at whether it can refund (the easy step) — look at whether it has this row of "don't-pay" guardrails. The demo segment where the Agent refunds silkily is precisely the least valuable part.
4. gate_common: knock out half the cases before even querying the order
The cheapest guardrail is the one at the very front. gate_common runs before the order query; any hit goes to a human or to compensation, never entering the refund mainline:
class GateCommonStep(WorkflowStep):
async def run(self, ctx):
for check, reason in [
(has_active_complaint, "open complaint"),
(is_delayed_shipment, "delayed shipment → compensation, not refund"),
(account_mismatch, "ordering account ≠ requesting account"),
(in_blacklist, "blacklist hit"),
(already_refunded_once,"this order already refunded once"),
]:
if await check(ctx):
return StepResult(output={"gate": reason}, next_step="transfer_to_human",
message=None, tool_used=None)
return StepResult(output={}, next_step="query_order",
message=None, tool_used=None)
None of these five is "refund logic" — they're all signals that "this refund shouldn't be auto-handled by the Agent at all." Front-loading them skips every later step and plugs the most common incident classes: auto-refunding a user mid-complaint, refunding an impersonated account, refunding the same order a second time.
Detection signal: for a vendor's refund workflow, ask first "before you query the order, which classes of case do you knock out?" One that can't name a single front gate is designed "assume we can refund, then find reasons not to" — backwards. The safe design is "assume we shouldn't refund, release through gates one by one."
5. Every leaf with an unwired external system defaults to a human
The ugliest and most important part of real delivery: external systems aren't ready all at once. The private refund API is live; the public order-query adapter isn't built yet; the image-recognition service is in evaluation; the price-diff system and ticket system are waiting on the other side's schedule.
The linear version assumes every dependency is present. The branching tree must assume most aren't. So every leaf needing a not-yet-wired external system degrades uniformly — transfer_to_human:
class ExecuteBySystemStep(WorkflowStep):
async def run(self, ctx):
target = SYSTEM_ROUTE[ctx.branch] # which system this leaf settles to
if not target.is_ready(): # external system not wired
return StepResult(output={"degraded": target.name},
next_step="transfer_to_human",
message=None, tool_used=None) # fail-closed
result = await target.execute(ctx)
return StepResult(output=result, next_step="confirm", ...)

This lets delivery be phased, and every phase is safe:
- P0 (shippable now): private minimal loop — master switch + common gates + private order query + limit check + critic + confirmation + private refund execution. Sub-scenarios with no image recognition, no price-diff system, no ticket system all go to a human first.
- P1: image recognition (shipping-fee proof, tracking number) wired, public order adapter wired.
- P2: as the price-diff system, ticket system, platform backends become ready, flip each corresponding leaf from "human" to "auto-execute" one at a time.
The key idea: "go to a human" isn't this feature being unfinished — it's the feature's safe default state. Flipping a leaf from human to auto-execute is a launch needing its own canary and verification, not "it should have been automatic anyway." Same principle as the fail-closed Critic post: when unsure, fall toward "a human covers it," never toward "the machine releases."
6. Limits don't live in the prompt — they live in a ledger table
Anything "cumulative" must never be left to the LLM to remember — it must be a deterministic database query. This is the one I refuse to compromise on.
Why? Because "how much has this user refunded this month" is a cross-session, cross-time fact that simply isn't in the model's context. Asking the model to "estimate how many times the user has refunded" is a disaster. It has to come from a table that keeps the books:
-- refund_ledger: one row per successful refund
CREATE TABLE refund_ledger (
id BIGSERIAL PRIMARY KEY,
account TEXT NOT NULL, -- in-channel id (private member / public-platform account)
channel TEXT NOT NULL, -- never unified across channels
scenario TEXT NOT NULL, -- fee | price_diff | compensation | ...
amount NUMERIC NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
The check step queries it — aggregating by (account, scenario), and any cap hit goes to a human:
class LimitLedgerCheckStep(WorkflowStep):
async def run(self, ctx):
used = await ledger.usage(account=ctx.account, channel=ctx.channel,
scenario=ctx.scenario)
# example caps (real numbers per business): per-txn min(paid×10%, CAP), day, month, 90-day window
if (ctx.amount > min(ctx.paid * 0.10, CAP_PER_TXN)
or used.today + ctx.amount > CAP_DAY
or used.month + ctx.amount > CAP_MONTH):
return StepResult(output={"limit": "exceeded"},
next_step="transfer_to_human", ...)
return StepResult(output={}, next_step="critic_check", ...)

Two decisions here are easy to get wrong:
First, the cumulative key is (account, scenario), strictly scoped within the current channel, with no cross-channel unification. Private member ids and the various public-platform account ids don't connect — you technically can't query across them. So daily/monthly limits are counted per scenario; a single account's total daily exposure = per-scenario cap × restricted-scenario count. That's not a compromise, it's the honest design forced by "cross-channel accounts can't be reliably linked." Admitting you can't unify is safer than pretending you can.
Second, this ledger runs on a real relational database, not a lightweight KV. It's write-heavy, needs concurrency, needs audit — it's the same ledger, from the other side, as the "duplicate refunds must reconcile against the ledger" point in the launch-gate post: prevention writes it, measurement queries it.
7. Before every write — a Critic, then a confirmation card
By here, every prior gate has released and limits aren't hit. But before actually calling the finance API, two more stand in the way: a machine's semantic gate, and a human's confirmation.
class CriticCheckStep(WorkflowStep):
async def run(self, ctx):
verdict = await llm_critic.review(ctx) # does this refund hold up semantically
if verdict is None or verdict.timed_out: # ← fail-closed
return StepResult(output={"critic": "unavailable"},
next_step="transfer_to_human", ...)
if not verdict.approved:
return StepResult(output={"critic": verdict.reason},
next_step="transfer_to_human", ...)
return StepResult(output={}, next_step="confirm_card", ...)
Note verdict is None or verdict.timed_out — a Critic timeout, error, or empty return is all treated as "fail," go to a human, not "the gateway hiccuped so release." That's the core of the fail-closed Critic post: a Critic that releases on timeout is no Critic, because attackers and corner cases show up precisely when it's weakest.
Critic passed, there's still confirm_card — a card asking the user to confirm; the workflow pauses here and only resumes when they tap confirm. Machine judgment + human confirmation, both belts on, neither omittable when money's on the line.
8. Sub-scenario switches default OFF, ramped one at a time
This many sub-scenarios can't go live together. So each hangs off an independent switch, all defaulting to off:
# thresholds.yaml
small_refund:
enabled: false # master
refund_fee: false # shipping fee
price_diff: false # price difference
compensation: false # private compensation
defect: false # public defect
quality: false # public quality

Default-OFF means: merging the code ≠ the scenario is live. For a sub-scenario to take effect, someone has to explicitly flip that switch to true — and the precondition for flipping is that the scenario cleared the pre-launch gates: correct rate, the wrong-execution red line, limit-boundary tests all passing. Switches + gates together achieve "all the workflow's code is present, but only the verified scenarios are admitted."
This is also the mechanism under safe P0/P1/P2 phasing: P0 flips only the private switches, the public ones stay OFF and their leaves all go to a human — production runs a workflow that's capability-complete but admits only a small verified slice.
9. How to verify: every gate, every limit boundary, every degrade path needs an assertion
The tests for this design aren't "test whether it can refund" — refunding is the easiest thing to test. The hard part is testing that the eight-tenths of "not-refund" logic is all right:
- One unit test per gate: mid-complaint, account mismatch, blacklist, already-refunded — each must assert "go to a human, and the finance API was never touched."
- One unit test per limit boundary: paid×10%, per-txn, per-day, per-month, 90-day window — boundary values (exactly equal / over by a cent) all tested.
- One assertion per "external not ready → human" degrade path: this is the lifeline of fail-closed; every leaf needs a "dependency down, confirm it goes to a human, not errors or releases."
- A private P0 end-to-end happy path: with a within-7-days mock order, run "what can be refunded actually is."
Note the shape of this test matrix: the vast majority of cases verify "when it shouldn't refund, it didn't." Consistent with the dual-track testing post's "the write-op track is reviewed case by case, exceptions always included" — a money-moving workflow's test set should also be mostly "not-refund."
10. What you can do with this skeleton this week
Compressed into a directly usable detection tool — next time you review a refund (or any money-moving) Agent proposal:
- Ask "how many judgments are there before payout?" Can't count 5+ front guardrails = a dangerous "assume we can, then find reasons not to" design.
- Ask "is the next step decided by code or by the LLM?" Path chosen autonomously by the LLM = L3 autonomous, a red line in money-moving scenarios.
- Ask "where do cumulative limits live?" "The model remembers" or "it's in the prompt" = fail; it must be a queryable, auditable ledger table.
- Ask "what's the default behavior when an external system isn't ready?" "Release / return success first" = fail-open, financial loss sooner or later; the safe answer is fail-closed to a human.
- Ask "what happens when the Critic times out?" "Release" = no Critic at all.
- Ask "does launching a new sub-scenario mean code changes or a switch flip?" "Change code and redeploy" = no canary mechanism; the safe answer is switches default-OFF, flipped one scenario at a time.
What these six share: they all ask about the "don't-do" side of the design, and not one asks "can it refund." Because whether it can refund is the easy part; whether it dares ship lives entirely in that eight-tenths of "not-refund" guardrails.
Going deeper
This has mature engineering names worth digging into:
- State machine: explicitly enumerated
next_stepis, in essence, a deterministic state machine. Designing the workflow as one makes the path enumerable, testable, drawable — the engineering definition of "deterministic." - Saga pattern: a write across multiple external systems (refund + settle + notify) must either all succeed or be compensatably rolled back. A money-moving multi-step op will eventually face partial-failure compensation.
- Idempotency key: the ultimate weapon against duplicate refunds — each refund request carries an idempotency key, and the finance API executes a given key only once. Ledger dedup is the application-layer defense; the idempotency key is the interface-layer defense; you want both.
- Two-phase confirm:
confirm_card's pause/resume is a lightweight two-phase commit — prepare, await confirmation, then execute.
None of these is deep theory — they're the standard kit for keeping a money-moving multi-step op out of trouble. An L2 refund workflow ships not on some clever LLM, but on this whole set of deterministic, enumerable, default-to-safe guardrails.
The next post flips from defense to offense: how to red-team a money-moving Agent — seven classes of attack corpus, A through G, targeting exactly what causes financial loss and information leakage.
Send me the keyword "WORKFLOW KIT" and I'll send the L2 refund workflow skeleton self-check sheet: the branching-tree template + a 7-guardrail checklist + the 6 vendor questions + a fail-closed degrade-path list, one page to pin to your proposal review.
(Channels in the footer — X or email both work.)
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.