Why a 70% Critic Beats a 95% Critic — A Fail-Closed Design Deep Dive | Agentic AI in Practice (III)

Third piece in the Agentic AI in Practice methodology series. The second piece — Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship — laid out the five forks of L2 design. Decision three — the Critic must be fail-closed — is the single most counter-intuitive piece in the series. This one delivers on that promise: how to write the Critic prompt, how to set thresholds, how to manage the human queue, when to use a rules-Critic, and how to evaluate the Critic itself. 中文版:自动化率 70% 的 Critic 比 95% 的更值钱.
A Refund That Shipped With an Extra Zero
A retail customer-service Agent. Day 14 of pilot. The vendor's deck had promised a 95% automation rate. The business sponsor signed off and let it run.
Day 14, 8pm. A $980 refund landed on a long-time customer's card. The flow had looked clean — order lookup (success) → policy match (success) → Critic second-pass review (started) → Critic timeout (LLM service degraded) → pass through → finance API call (success).
One problem. The order total was $980 — a set of accessories. Only a single $98 small item needed refunding for a quality defect. The correct refund was $98, not $980. The LLM had filled the refund_amount parameter with the order total — an extra zero. The Critic was supposed to catch this on second pass. The Critic timed out. The design said "on timeout, pass through." The money went out.
In the post-mortem, the tech lead said: "The Critic still passed through when it failed — it's not that the Critic didn't work." The CEO didn't buy it: "The Critic is supposed to be the backstop. If it times out, shouldn't it escalate to a human? Why pass through?" The tech lead's answer: "Because escalating to a human would knock the automation rate from 95% to 70%."
There's an unspoken bet in that exchange. The team is betting that "the Critic mostly doesn't time out." The CEO is betting that "when the Critic fails, the safe move is the right move." Which one is right?
The answer is fail-closed: Critic fails, escalate to human, do not pass through. It has a real cost — early-phase escalation rate jumps from 5% to 30%, and you need to do that math before walking into the CEO's office. This piece does the math. The three failure modes, how to write the prompt, how to set thresholds, rules versus LLM Critic, how to manage the human queue, how to eval the Critic itself. By the end you can walk back into the CEO's office with a proposal that gets signed.
The Three Critic Failure Modes — Every Fail-Open Path Ends Badly
A Critic on a write operation can fail in three ways: timeout, error, and low confidence. All three look like "edge cases," but each one fires exactly when the system most needs to stop. Fail-open treats them as "approved." That's the bet this piece is here to dismantle. One at a time.
Timeout. LLM timeouts usually mean the model is under peak load — 8pm e-commerce promo, vendor squeezed by multiple enterprise customers, network jitter. At that exact moment, the underlying LLM's own judgment quality is already degrading (high load = rate-limiting + degraded service + tail-latency), and the Critic's second-pass review is harder to do right. Fail-open says "timeout counts as approved." The moment the system is least reliable is the moment the check gets skipped. The $980 refund above was exactly this — at 8pm the platform's LLM service was degraded, the first LLM mis-judged a digit on the edge, the Critic was supposed to catch it, and because of the same wave of degradation it timed out.
Error. A Critic that errors out (HTTP 5xx / JSON parse failure / prompt-injection detected) usually means the input is outside known patterns: dirty data, unfamiliar characters in context, the user dropped a weird token into the conversation, an external API changed its response shape. That's exactly when you most want a Critic to take a look. "Errors are rare" — but the request that errored is often the request with the most anomaly and risk.
Low confidence. The most insidious one. The Critic returns "approved," but at confidence 0.55 — the LLM is saying "I'm not sure." Fail-open treats this as approval because protocol-wise it is approval. But low confidence is itself a signal: the LLM knows it can't pin this one down. Treating a 0.55 "approved" the same way as a 0.95 "approved" is turning the Critic's honesty into the system's blind spot.
The fail-open versus fail-closed split across the three failure modes — the diagram from piece two captures it cleanly; reused here:
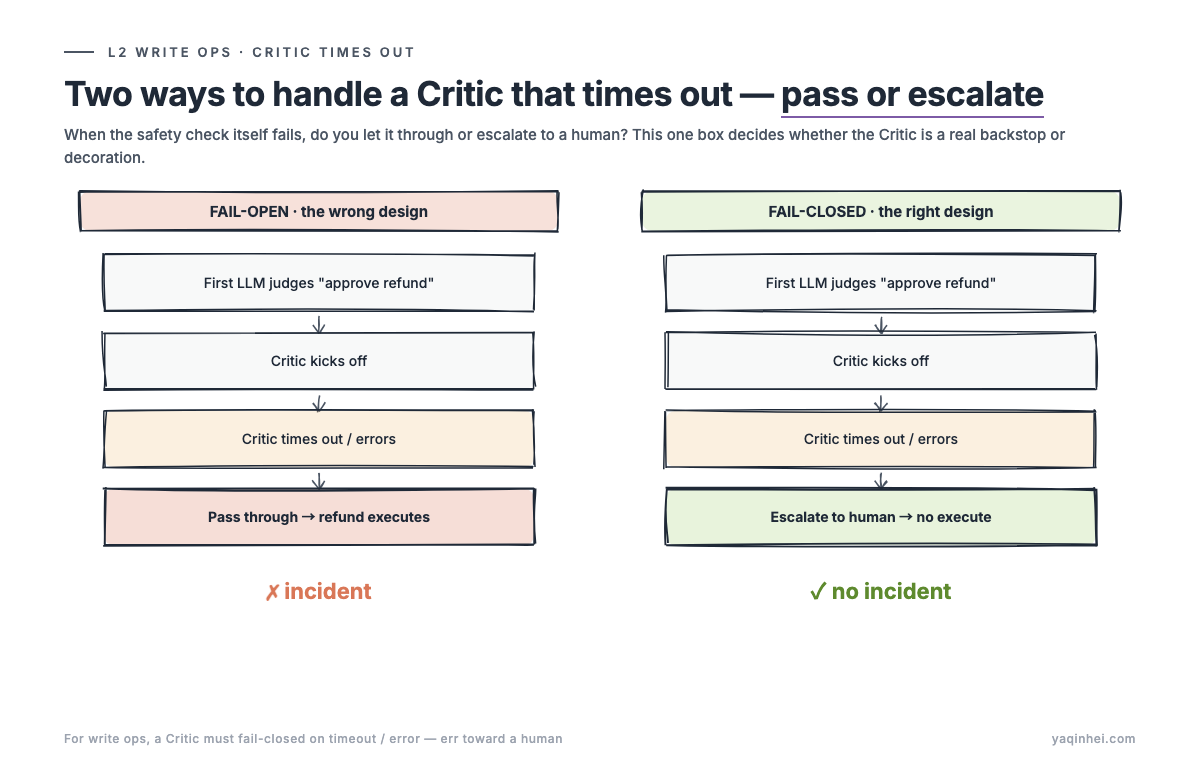
Rolled into an action table:
| Failure mode | Fail-open response | Fail-closed response | Why |
|---|---|---|---|
| Timeout | Pass through | Escalate to human | Timeout usually means service degradation; the action gets passed through exactly when quality is worst |
| Error | Pass through | Escalate to human | Errors usually come from anomalous input — exactly the input that most needs review |
| Low confidence (below 0.7) | Treat as approved | Escalate to human | The LLM is itself saying "I'm not sure"; treating honesty as a blind spot |
| Critic explicit "no" | Escalate to human | Escalate to human | One of the two cases both designs agree on |
| Critic explicit "approved" + high confidence | Execute | Execute | The other case both designs agree on |
Out of five possible Critic returns, fail-open and fail-closed agree on four — the split is on the three failure modes. Fail-open treats failure as approval. Fail-closed escalates without exception. The cost is a 30% human-escalation rate. The $980 incident is your evidence that the cost is worth paying.
A vendor will often counter: "Our Critic failure rate is only 3%, low impact on the system." What's wrong with that? Failure isn't randomly distributed. The 3% that fails is precisely the high-risk 3% — every incident concentrates inside that 3%.
Customer-Service Write Ops Are the Same Class of Problem as Bank Transactions — That's Where Fail-Closed Comes From
A lot of LLM engineers approach Critic design as if they're inventing something. They're not. Customer-service write operations are the same class of problem as bank transactions, medical orders, and aviation checklists. Every system in that class has converged on the same answer over the past several decades: fail-closed.
Pull the four defining traits of this problem class apart:
- Write operations are irreversible. A refund posted = money on the user's card. A ticket created = the store has been notified. An SMS sent = the user has formed an expectation. Reversing takes a separate flow, often inside a time window outside of which it can't be reversed at all.
- Accountability must land somewhere. After a customer-service project goes live, four groups will keep asking why a transaction went the way it did — regulators, compliance, internal audit, and customer complaints. Every step has to be auditable.
- The backstop itself fails. The Critic times out, errors, returns low confidence — the three modes above. Backstop failure needs its own backstop, and that layer is "where do we route when it fails."
- Marginal decision cost is far below incident cost. One extra manual approval versus one wrong refund — the latter is one to two orders of magnitude more expensive. That asymmetry decides: better to over-escalate ten times than under-execute once.
Stack those four together and the conclusion is that the backstop must be fail-closed — fail = escalate, do not pass through. This isn't an LLM-specific problem. Every system involving "high-cost irreversible write operations" handles it the same way. A few cross-industry examples:
- Bank transactions: risk engine fails → reject + escalate to human. Regulatory frameworks (PCI-DSS, SOX, every central bank's clearing rules) write this in plain text. Any review step fails, the transaction must hold; no pass-through. Thirty years of finance industry experience.
- Medical orders: drug / dosage cross-check fails → suspend the order + escalate to a pharmacist for second review. Hard requirement under HIPAA + JCI.
- Aviation checklists: any "unverified" item before takeoff → no takeoff. The NTSB database attributes about 20% of all aviation incidents to "skipped checklist."
Across these three systems, the shared design philosophy is one line — "safety is what happens when nothing happens." When the system works as intended, no one notices fail-closed. The moment the backstop is needed, fail-closed is the only design that lets you explain yourself to the board, the regulator, or the courtroom after the incident.
Customer-service Agents line up on all four traits, which gives you the same conclusion: Critic fails → escalate + hold, no pass-through.
That paragraph is worth speaking out loud in front of the CEO. Once a CEO understands "this is engineering consensus from high-stakes systems over the last several decades, not the LLM team's purity," half the resistance to fail-closed disappears. Translating fail-closed from "engineering preference" into "industry best practice" is the most effective way to win the team design authority.
The flip side. If a vendor tells you "our Critic is fail-open because LLM systems are different" — you can ask back: "Would you connect a fail-open risk engine to your own online banking? Would you sign off a fail-open medication check for your own family?" An LLM system doesn't escape these four traits by being an LLM. A vendor defending fail-open with "LLMs are different" is the same as a bank saying "our risk engine is different so it can pass through." No one buys it.
The Critic Prompt — From "Review This" to "Check These N Known Errors"
Plenty of teams write their first Critic prompt like this:
You are the second-pass reviewer for a customer-service Agent. Please review
the refund decision below for reasonableness:
[refund decision]
Answer: approve / reject + reason.
Run it for two days and the problem is obvious — the LLM will confidently "approve" almost everything. Not because the decisions are right. Because "review" is an abstract task and there's no concrete hook for the LLM to fire on "reject." The Critic becomes a rubber stamp.
The shippable version replaces "review" with "check against these N known error patterns" — turning the task from open-ended judgment into enumerated matching. An example:
You are the second-pass reviewer for a customer-service Agent. Below is the
first LLM's refund decision. Check item by item against these **8 known
error patterns**. Any match → output "reject" + the matched pattern id.
## Known error patterns
1. Refund amount digit count doesn't match the actual item amount (e.g.
the small item should refund $98 but the LLM filled $980 — extra zero)
2. Order belongs to "brand consignment" but the decision took the
"platform-owned" refund path
3. Item state is "used" but the decision took the "7-day no-reason return" path
4. Logistics state is "delivered more than 30 days ago" but the decision
took the "not yet delivered" refund path
5. User identity verification missing (order not placed by the requester +
no identity proof)
6. Refund amount exceeds the per-call authorization (above $5,000 must
route through human approval)
7. The same order has been refunded within the last 30 days (duplicate
refund risk)
8. Refund reason text contains sensitive keywords (suspected fraud /
system exploit / pricing anomaly)
## First LLM's refund decision
[decision]
## Output format (JSON)
{
"verdict": "approve" or "reject",
"matched_pattern_ids": [],
"confidence": 0.0-1.0,
"reasoning": "one sentence"
}
Three differences. First, the Critic is no longer asked "is this right?" but "does this match any of the following known errors?" — LLM execution quality jumps an order of magnitude. Second, every error pattern is concrete and matchable — the Critic doesn't need to "understand" the business, just to "match" patterns. Third, structured JSON output lets the downstream auto-route to different human queues based on matched_pattern_ids: amount anomaly → finance approval, ownership error → business expert, identity verification missing → risk.
Where do those 8 patterns come from? From the post-mortems of your last 3-6 months. Every post-mortem's output should include "what's the signature of this class of error" — those signatures are the patterns in your Critic prompt. Pattern 1 in the example above (digit-count mismatch) was extracted from the $980 incident.
The Critic prompt isn't written once. It's a loop — incident post-mortem → pattern extraction → prompt update. Across the customer-service Agent projects I've followed, after 3-6 months the Critic prompt's pattern list typically grows from a starting 6-8 to 18-25. That growth is healthy. It means the team is systematically learning from production.
If a vendor's Critic prompt has no concrete pattern list — just vague phrasing like "review / second-pass check / verify reasonableness" — it's effectively no Critic at all. If the prompt hasn't been updated in six months, the team isn't extracting patterns from incidents, the Critic is going stale, and coverage will fall behind the next class of scenario.
Setting Thresholds — A 2D Table of Confidence Times Business Criticality
The most common design is "confidence below 0.7 escalates to human" — a single cut-off. The problem is that 0.7 means completely different things at different business criticalities. A bad content recommendation, no one cares. A bad refund amount, that's an incident. Same number, two different worlds.
The escalation threshold should be a 2D table — confidence on one axis, business criticality on the other, four combinations driving four actions:
| Confidence \ Criticality | Low (e.g. content rec) | Medium (e.g. logistics lookup) | High (e.g. refund / order edit) |
|---|---|---|---|
| High (above 0.85) | Execute | Execute | Execute |
| Medium (0.65 - 0.85) | Execute | Execute | Escalate |
| Low (below 0.65) | Execute + log | Escalate | Escalate |
| Critic failed | Execute + log | Escalate | Escalate |
How is business criticality defined? Three dimensions: reversibility (irreversible = high), dollar value / blast radius (high = high), compliance exposure (involves money / customer PII = high). Roughly how customer-service Agent write operations distribute:
- High criticality: refunds, order edits, ticket creation (touches store logistics), inventory deductions, outbound user push notifications — irreversible / touches money / hits external systems
- Medium criticality: logistics lookup, order lookup, membership-point lookup — read-only but visible to the user
- Low criticality: dialogue context summarization, content-recommendation re-ranking, FAQ disambiguation — lightweight in-dialogue actions
The 0.65 / 0.85 thresholds are starting points based on experience. Tune from data after 1-2 weeks. Direction depends on the escalation rate: any tier escalating above 40% → loosen (0.65 → 0.55); any tier below 5% but incident rate climbing → tighten (0.65 → 0.75). Thresholds aren't set once. They're a closed-loop process.
Note one counter-intuitive design — at low criticality, "low confidence" still executes + logs, no escalation. Even when low-criticality is wrong, the cost is low (a bad recommendation, an imprecise summary), but the cost of escalating to a human is fixed (occupies a seat, increases user wait time). Fail-closed at low criticality is over-design. The point of fail-closed isn't "escalate on any failure" — it's "escalate on failure in high-cost scenarios."
A vendor giving you a single threshold ("escalate below 0.7"), with no distinction by business criticality, means the design hasn't thought about cost distribution. Either they crush the human seats (one-shot tightening) or they bury landmines in high-criticality scenarios (one-shot loosening).
Rules Critic vs LLM Critic — Which One When
A lot of teams ship a pure-LLM Critic chain: first LLM proposes, second LLM reviews. Three problems show up in production — LLM Critic is slow (+1-2s latency), expensive (+50% LLM cost), and on some checks it's less accurate than a rule (numeric comparison, format validation — rules are more stable).
The design that holds up in production is two layers: rules Critic first (millisecond), any match → escalate immediately + skip the LLM Critic; rules all pass → LLM Critic runs the second-pass semantic review.

Rules Critic fits every check that can be expressed precisely:
- Numeric bounds: refund amount above per-call authorization (above $5,000) → hard stop
- Format validation: JSON schema, required fields, enum validity
- State-machine constraints: order state ≠ "completed" → no refund; user identity unverified → no order edit
- Frequency / rate: same user, refund count > 3 inside 5 minutes → flag
- Blacklist / whitelist: high-risk users, specific SKU exceptions
LLM Critic fits every check that requires semantic judgment:
- Intent-action alignment: user says "this thing isn't great," LLM interprets it as "return intent" — whether that interpretation is right, no rule can capture
- Context coherence: dialogue history shows the user said "not returning for now," the new LLM output says "your refund has been processed" — no rule catches this contradiction
- Policy application reasonableness: item state + logistics state + user identity + time window + category policy, five variables cross-judged — rules would explode; LLM is actually good at this
Side by side:
| Dimension | Rules Critic | LLM Critic |
|---|---|---|
| Latency | < 10ms | 500-1500ms |
| Cost | ≈ 0 | cents to tens of cents per call |
| Accuracy (in scope) | 99%+ | 85-95% |
| Maintenance cost | new rule = new code | new pattern = prompt edit |
| Fits | precisely expressible checks | checks requiring semantic judgment |
| Critic's own failure rate | < 0.1% | 3-10% |
The last row is worth a second look. Rules Critic essentially never fails (barring code bugs). Running rules first means most write operations get filtered at the rules layer, and the LLM Critic only handles the remaining edge cases. This layering drops LLM Critic call volume by an order of magnitude — big improvements on both cost and latency.
If a vendor says "our Critic is a pure LLM design, no rules layer" — odds are cost and latency both spiral out of control after launch, because the LLM Critic is doing work rules should be doing (amount checks, format validation, state-machine judgments). This design looks fine in the demo reel; it falls over under production concurrency.
Managing the Human Queue — The 30% → 5% Curve, Don't Engineer It Backwards in the Early Phase
The verdict on the table first — early-phase fail-closed escalates 30% of write operations to humans. That's valuable feedback, not a failure signal. Three to six months in, it naturally drops below 5%, and the automation rate ends up higher than a fail-open design's.
This section is for the CEO, not the engineer. The engineer gets it. Under automation-rate pressure, the CEO will ask to "do fail-open first, switch to fail-closed once it's stable" — that's the most common way a fail-closed project dies.
Three dynamics behind the descent curve:
First, in the early phase the Critic prompt is incomplete — the pattern list only has 6-8 entries — and any edge case not yet covered triggers a false escalation. Of the 30% escalated to humans, roughly 20% are false escalations (actually fine but escalated) and 10% are risks the Critic correctly caught. The 20% false escalations are the product team's gold mine — every false escalation reviewed becomes a new prompt pattern or threshold tweak, and inside 3 months Critic precision improves 2-3x.
Second, in the early phase the first LLM's decision quality is also iterating. The first LLM's prompt keeps getting tuned (against human feedback), output quality climbs — Critic escalations naturally fall.
Third, the business team gradually identifies "scenarios the Agent shouldn't be doing at all" — those scenarios get peeled off (routed directly to rules or humans), and the Agent handles the remaining scenarios better.
Stack the three dynamics, and 3-6 months in, the escalation rate drops from 30% to below 5%. Every fail-closed project I've followed has traced this curve. No exceptions.
The fail-open trajectory looks the opposite. Starts at 95% automation rate (looks great) → first incident hits in week 3-6 (wrong refund / wrong ticket / wrong SMS) → post-mortem → whole thing taken offline for 1-2 weeks of remediation → relaunch with extreme caution + a pile of hard-stop rules added (effectively degraded to fail-closed) → automation rate sits below 50% and never recovers. Long-term, fail-closed beats fail-open. It's not a contest.
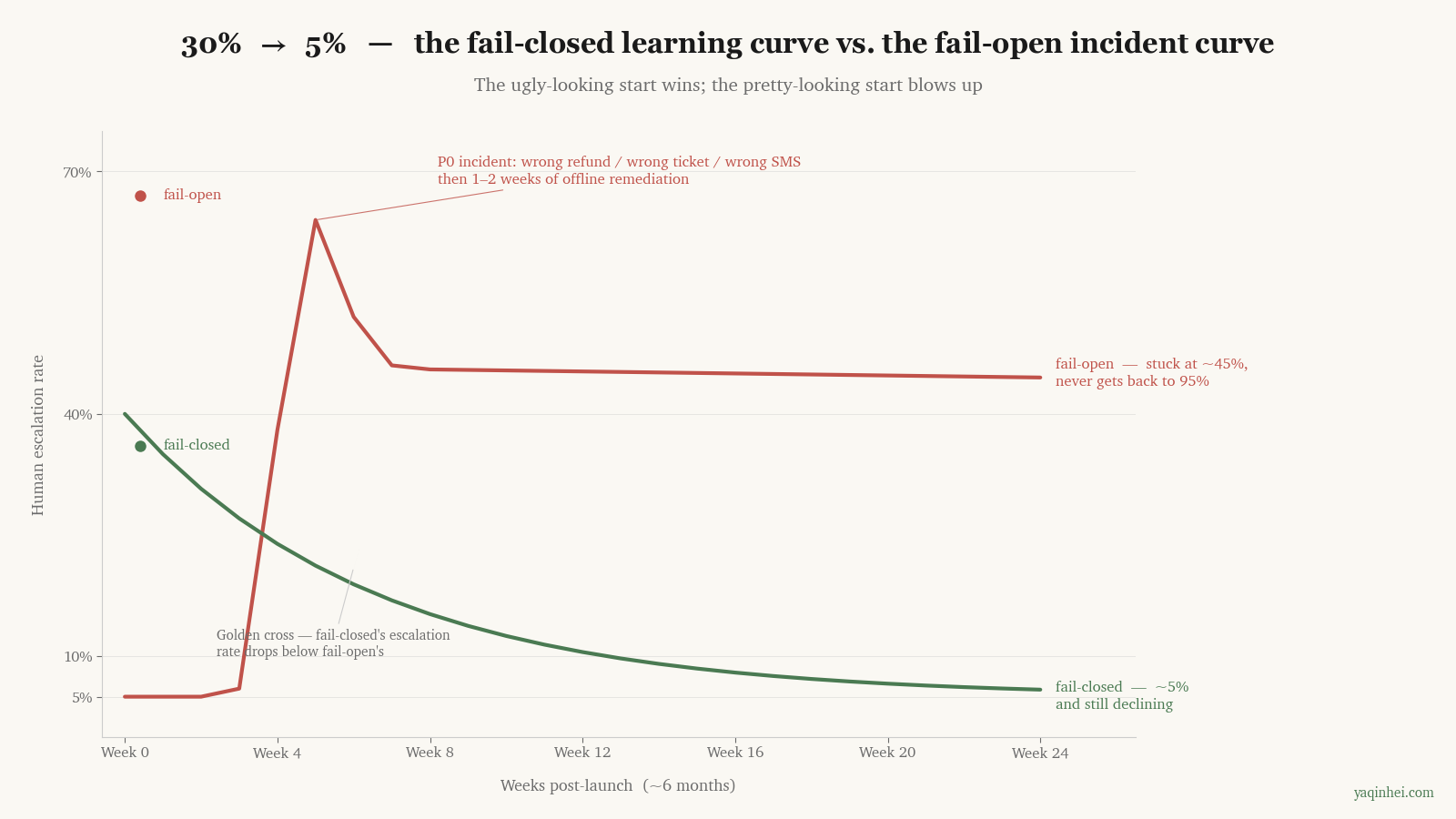
Put that curve in front of the CEO. The first glance is counter-intuitive — one starts at 30%, the other at 5%. The second glance is the one that lands — you have to look at the whole 6-month curve, not the week-one cross-section.
How do you manage that 30% escalation queue? Three things:
Classify the queue. Route per the Critic's matched_pattern_ids to different human groups (amount anomaly → finance, ownership error → business expert, identity verification missing → risk). Each group has a different SLA (amount anomaly is highest priority, must be handled inside 5 minutes). Don't dump it all on the customer-service queue.
Feedback must flow back. Every escalation case, after the human handles it, gets two fields marked: "was the Critic escalation correct" (true/false) + "if false, why?" These two fields aggregate weekly, driving prompt and threshold updates.
Reset the KPIs. Early-phase fail-closed can't use "automation rate" as the team KPI — it pushes the team to quietly flip fail-closed back to fail-open. Replace it with "net automation rate": (automated handled - incident-affected orders × 100) / total volume. One incident equals 100 automated transactions docked, a weight that means fail-open never wins on the KPI. If a vendor only gives you "automation rate" as a single metric, push for net automation rate or a similar composite — otherwise you're hiring a KPI whose job is to push the team toward fail-open.
Evaluating the Critic Itself — The Meta-Problem of Recursive Review
The Critic is also an LLM. It also makes mistakes. It needs a ground-truth eval set running continuously, watching two numbers: miss rate (false-negative) and over-escalation rate (false-positive).
This section gets technically deep. Business sponsors can skip it. But projects often die at this step — no one evals the Critic after launch, it slowly becomes a black box, and the incident is what tells you.
Two sources for the eval set:
Historical incidents + counter-examples. The last 3-6 months of post-mortems plus known edge cases, curated into a ground-truth dataset. Each entry has an "input decision" and the ground-truth label "should escalate / should approve." This set must score 100% — any miss is a pre-launch bug.
Random sampling on the happy path. Sample 500-1000 normally-approved decisions from production (human-confirmed as genuinely "should approve"), run them through the Critic, check whether the Critic labels them all "approve." This set measures over-escalation rate: the Critic shouldn't be false-escalating normal cases.
Together they form the eval set. Run it on a schedule:
| Metric | Definition | Target |
|---|---|---|
| Miss rate (false-negative) | Share of "should escalate" cases the Critic labeled "approve" | Below 1% (hard constraint) |
| Over-escalation rate (false-positive) | Share of "should approve" cases the Critic labeled "reject" | Below 20% at start, drop below 10% in 3 months |
| Critic's own failure rate | Total share of timeout / error / low-confidence | Below 10% at start, below 5% once stable |
The two metrics' priorities are very different. Miss rate has to approach zero — the Critic is the backstop, a miss = an incident. If a prompt change moves the miss rate from 0.5% to 1.5%, the change has to be rolled back, no matter how nice it looks on other dimensions. Over-escalation rate can come down slowly. 20% is normal at start (Critic growing up in conservative mode), drops below 10% in 3-6 months.
Update the eval set weekly: add last week's production incidents + cases of "Critic false-escalation" from human feedback, then re-run the full set. The eval set should grow. It shouldn't sit still. An eval set that doesn't grow is a sign the team isn't learning from production.
A vendor that never updates the Critic eval set after launch is letting the Critic go stale — coverage will fall behind new scenarios. Another thing to watch: a vendor reporting only "precision / recall" on the Critic, never "miss rate / over-escalation rate." The two pairs look similar but mean very different things. Miss rate is the lifeline metric for fail-closed. Without it, you essentially have no eval.
Six Signals — 5 Minutes to See Through a Vendor's Critic Design
Everything above compressed into one table. Bring this to the next meeting and check off:
| # | Signal | Fail-open answer | Fail-closed answer |
|---|---|---|---|
| 1 | "What happens when the Critic times out?" | Auto pass-through / default approve | Escalate to human |
| 2 | "What happens when the Critic errors out?" | Skip + log / default approve | Escalate to human |
| 3 | "What does the Critic prompt look like?" | Vague — "review reasonableness" | Enumerated N known error patterns |
| 4 | "How is the escalation threshold set?" | Single number ("below 0.7 escalate") | 2D table: confidence × business criticality |
| 5 | "Rules Critic or LLM Critic?" | Pure LLM / pure rules | Two layers: rules first + LLM second-pass |
| 6 | "How do you eval the Critic itself?" | No eval / only "approval rate" | Miss rate < 1% + over-escalation < 20%, weekly eval |
Five minutes and you can grade it. Any vendor's Critic design, six questions, and you can see clean through — is this design forged in production, or is it the well-dressed version that's only good in the demo?
If 3 or more of the 6 answers are fail-open, this design will produce an incident after launch. Either make the vendor redo it as fail-closed, or change vendors.
Since publishing
A reader on X (@jsyqrt) pointed out something this article missed: the most upstream guardrail isn't a better Critic — it's typed deliverables.
Pull everything that can live in a schema — refund_amount: number ≤ order_amount, policy_clause: enum, customer_id: required — out of LLM judgment entirely. The LLM still generates the payload, but a type validator rejects anything off-shape before the Critic ever runs. The Critic is left with what types can't express: semantic and policy calls ("is this refund consistent with our return window even though every field is technically valid?").
Types catch what they can; Critic catches what types can't. Two layers, not one. If you're building this from scratch today, do typed deliverables first (Pydantic AI / Instructor / Outlines / OpenAI structured outputs all do it well); the fail-closed Critic in this article applies to the semantic layer on top — a much smaller surface, easier to get right.
The Toolkit
If you want these tools straight in your next vendor-proposal review — without re-reading this article every meeting — I packaged a PDF kit for readers who got this far. Send me the keyword "CRITIC KIT" and I'll send the pack:
- The 6-signal fail-open-vs-fail-closed detection table (business-card-sized cards — tick through them while listening to a vendor's pitch)
- A Critic prompt template that enumerates N known error patterns (the fill-in-the-blank skeleton, ready to paste into your eval set)
- The 2D escalation threshold table (confidence × business criticality, one-page A4 print, for the wall over your desk)
Two years of customer-service Critic work, distilled into judgment tools.
(Channels in the footer — X or email both work.)
What's Next in This Series
Piece four is now live: Deploy and Abandon — The Costliest Misconception in AI Agent Projects — the six post-launch operational environments that get silently dropped from the SOW, paired with this piece's Critic design forms the full "ship-time + run-time" safety net.
The next pieces in the series, scheduled:
- Three-tier intent cascade tuning (decision 2 deep dive): rules + embedding + LLM fallback confidence thresholds, cache strategy, rolling out new intents without disturbing existing ones
- Wiring an LLM into enterprise SaaS (decision 4 deep dive): the 25-API → 5-tool wrapping contract, idempotency, timeout retry, gradual rollout
- Catch rate vs resolution rate deep dive (decision 5 deep dive): KPI migration path, the dual-metric transition period, the script for reporting to the boss
- How to test an AI system (standalone deep dive): dual-track architecture + seven quality dimensions
If your team is building a customer-service Agent, these four are coming over the next 3-4 weeks, one at a time.
This is the third piece in the Agentic AI in Practice methodology series. Earlier pieces:
- Piece one: 28 "Agent" Projects, Only 5 Are Real — The L0-L3 Grading Framework
- Piece two: Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship
The series follows the methodology of taking an Agent project from kickoff to launch. Subscribe at the bottom; new pieces get pushed.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.