LLM Fact-Checking with a Verifier Agent: 11 of 34 Facts in a 25-Page AI Plan Were Fabricated

Eleventh post in the Agentic AI in Practice series. The first ten cover whether a plan can ship, how to keep it from rotting after launch, the north-star metric, brain / hand separation, how to test, threshold tuning, API layering, and codebook evolution — L0-L3 grading, the 5 architecture decisions, fail-closed Critic, deploy-and-abandon, containment vs resolution, Skills vs knowledge base, dual-track testing, 3-tier intent cascade, five-layer API architecture, corpus-driven codebook evolution. This one tackles the output side — how LLM-drafted fact-dense material (plans / reports / emails / docs / code comments) gets from "untrusted" to "signable." The bottom line: a second agent acts as reviewer, the gate is structural, and you do not rely on the LLM to introspect. 中文版:AI 起草的 25 页方案里 11 条事实是编的.
11 fabricated facts in a 25-page plan — this is the baseline, not the vendor's fault
Last month I helped a client team review a vendor-delivered 25-page Agent roll-out plan. Precise terminology, clean diagrams, neat references — the typical AI-drafted + PM-polished deliverable.
I had a separate Claude session run a fact-check against the client's actual codebase and public docs:
- 34 factual claims (API paths / error codes / SDK versions / SLA numbers / third-party dependency names)
- 11 wrong: 3 API paths that don't exist on the client's backend, 2 SLA numbers pulled from thin air, 4 error codes with casing that doesn't match the schema (
"Critical"vs the schema's"critical"), 1 SDK version that was deprecated last year, 1 third-party dependency name misspelled
11 / 34 ≈ 32% error rate. The number is not specific to this vendor — it's the industry baseline for AI-drafted fact-dense material. When I drafted blog posts with Claude (including the one you are reading), the first-pass factual error rate also sat in the 20-30% range. Different vendor, same result.
What makes it worse: not one of those 11 errors would have been caught by "let the same LLM read it again." It's a mechanism-level limit:
- Error-code casing — the LLM does not grep the schema on self-review, it just notes "looks like a valid enum value" and moves on
- API paths that don't exist — the LLM does not curl anything, it notes "follows REST conventions"
- A deprecated SDK version — the LLM's training cutoff is the same as on the first pass, so it has no new data to contradict the original claim
"Let the LLM double-check its own output" is the most common pseudo-verification in enterprise AI roll-outs. When a vendor says "we already do AI review," push back with one question: is the reviewer a separate agent? Almost always, it isn't.
This post covers three things.
First, why single-agent self-check always misses — confirmation bias is not a taste problem, it's a physical limitation of one context window holding both the draft and the review.
Second, how the structural gate works — DRAFT → VERIFY → FINALIZE: what each phase must do and must not do.
Third, R1-R7, the seven recurring categories of fact errors — each with its own verification method, ready to paste into a PR checklist or vendor review template.
Next time you review AI-drafted contracts / proposals / outreach emails / policy summaries, every factual claim should trace back to a file:line or URL — anything that doesn't, doesn't belong in the final document.
You physically cannot have an LLM fact-check its own output
Bottom line: the drafting agent cannot self-verify. Not because it's "not careful enough" — because a single context window holding both "drafting goal" and "already-generated facts" triggers confirmation bias. On self-review, the LLM tends to confirm what it just wrote, not disprove it.
A concrete example. Ask Claude to draft an admissions outreach email for a Stanford EE PhD program. First pass:
Dear admissions@cs.stanford.edu,
...
Ask the same session to review the same email, "double-check the email address and department name." Eight times out of ten you get back "the email looks correct, stanford.edu is a valid TLD" — because after writing down admissions@cs.stanford.edu the LLM's self-review priority is "is this address plausible," not "does this address actually exist."
The real Stanford EE admissions email is phd-admissions@ee.stanford.edu (department-level, not school-level), and the source of truth for applications is the GradAdmit portal — you should not be emailing that address at all.
This error can only be caught by a separate subagent that doesn't know the draft, using WebFetch on Stanford EE's official Contact page.
Three physical reasons compound to make self-review unreliable:
- Context contamination — the main agent's context already contains the draft; no matter how it tries to "pretend not to know," the prompt tokens still bias the attention distribution
- Same training cutoff — the data the main agent was trained on is what it has; self-review uses the same incomplete-or-wrong corpus
- The optimization target is consistency, not truth — autoregressive generation optimizes for "the next token under the context distribution," not for "this claim matches reality"
The three combined mean self-review surfaces feedback on "stylistic flow and internal consistency," not on "factual truth." A drafter never catches the facts it fabricated — this doesn't need a benchmark to prove, it's a mechanism-level result.
The only working approach: drafter and verifier must be physically separate agents.
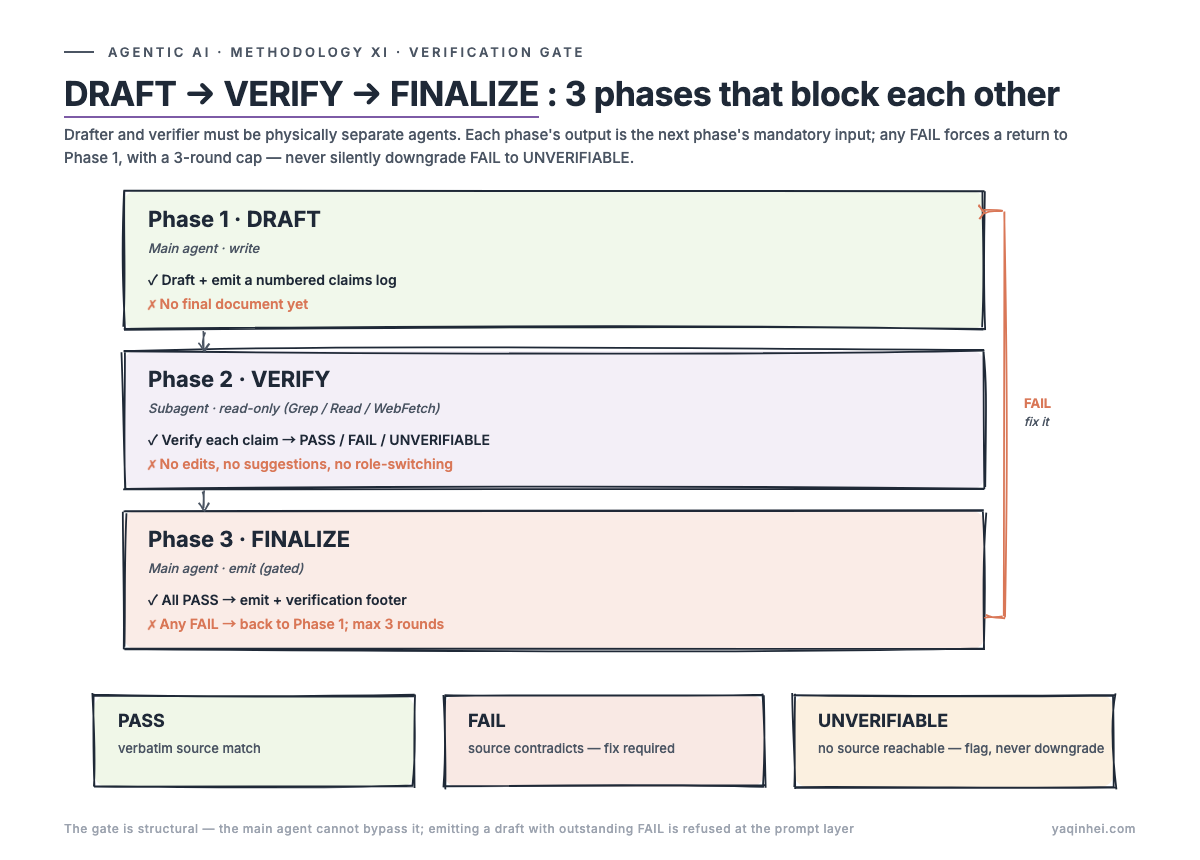
DRAFT → VERIFY → FINALIZE: the 3-phase gate
A verification-first workflow is not "have another agent take a look afterward." It's three mutually independent and mutually blocking phases — the output of the prior phase is the mandatory input of the next, and any phase that fails its own check blocks the one after.
┌──────────────────────┐
│ Phase 1: DRAFT │ Main agent drafts + numbered claims log
│ (main agent, write) │ Forbidden: emit final document
└──────────┬───────────┘
↓ (draft + numbered claims log)
┌──────────────────────┐
│ Phase 2: VERIFY │ Subagent (read-only) verifies each claim
│ (subagent, read-only)│ Forbidden: edit, propose fixes
└──────────┬───────────┘
↓ (PASS / FAIL / UNVERIFIABLE table)
┌──────────────────────┐
│ Phase 3: FINALIZE │ Gated: any FAIL → back to Phase 1
│ (main agent, emit) │ All PASS → emit + verification footer
└──────────────────────┘
Phase 1 — DRAFT: write + emit a claims log
After the main agent writes the first pass, it must produce a numbered log of every factual claim. A factual claim is:
- Enum / status value / severity level (case-sensitive)
- API path / HTTP method / request field name
- Function name / module path / class name
- Email / faculty name / departmental affiliation
- Policy URL / application deadline / portal link
- Intent ID / event name / schema key
- Model ID / SDK version / library name
A claims log entry looks like this:
1. severity enum value, lowercase "critical" | source: api/schema.proto
2. admissions email = phd-admissions@ee... | source: WebFetch Stanford EE
3. model ID = claude-opus-4-7 | source: grep 'claude-' --include='*.py'
4. application deadline = "December 1, 2026" | source: WebFetch stanford.edu/admissions
Before the claims log is written, emit of the final document is forbidden — this is structural enforcement, not "best practice."
Phase 2 — VERIFY: read-only subagent
Dispatch a new subagent (in Claude Code, that's Agent(subagent_type="Explore", ...)). The Explore subagent's default tools are Read / Grep / Glob / WebFetch — no Edit, no Write — exactly the right shape for a verifier. This subagent cannot see the prior conversation history, only the draft text plus the claims log.
For each claim it does three things:
- Find an authoritative source — code path or lockfile for code claims; official URL for policy claims; schema file for enum / schema claims
- Verbatim check — casing, quotes, symbols, dash vs underscore, all character-exact
- Verdict — exactly one of PASS / FAIL / UNVERIFIABLE
Output is a table:
| # | Claim | Verdict | Source | Notes |
|---|------------------------------|---------|-------------------------|----------------------------------------|
| 1 | severity enum lowercase | PASS | api/schema.proto:42 | matches "critical" verbatim |
| 2 | admissions email | FAIL | ee.stanford.edu/contact | actual: phd-admissions@ee.stanford.edu |
| 3 | model ID claude-opus-4-7 | PASS | lib/anthropic.py:8 | matches verbatim |
| 4 | application deadline Dec 1 | UNVERIFIABLE | stanford.edu/admis | 503 on page load; user must verify |
Verifier only verdicts — does not edit, does not propose fixes. The rule is intentionally counter-intuitive: letting the verifier suggest fixes pulls it into "fix-for-fix's-sake" mode and degrades verification itself. Verifier returns PASS / FAIL / UNVERIFIABLE, three values, and that's all.
Phase 3 — FINALIZE: gated emit
Back to the main agent. Inspect the verifier report:
- All PASS (or only UNVERIFIABLE with actionable reasoning) → emit final, append a verification summary footer (how many PASS, how many UNVERIFIABLE and why)
- Any FAIL → cannot emit. Revise using the verifier's
actualvalues, update the claims log, dispatch Phase 2 again - 3-round cap — after three rounds, surface remaining FAILs to a human, never silently downgrade FAIL to UNVERIFIABLE
The gate is structural: the main agent has no path to bypass it. If it tries to emit a draft with outstanding FAILs, the prompt layer refuses.
R1-R7: the seven recurring categories of fact errors
After receiving the claims log, the verifier's first move is not "grep each entry one by one" — it's classification. 80% of fact errors cluster into seven categories, each with its own verification method. The seven are R1-R7 in my ~/.claude/rules/doc-verification.md — each came from a specific incident I once shipped to production.
R1 — Enum value casing. Wrote severity: "Critical" but the schema is "critical". Verification method: grep the schema, char-exact match. This is the worst kind of fact error — looks right, 400s at runtime.
R2 — docx bullet list blank lines. When markdown becomes docx / PDF through pandoc, bullet lists without surrounding blank lines collapse into the preceding paragraph and render as run-on text. Verification method: when the deliverable is docx, every - / * / 1. block must have a blank line before and after. Structural error, not factual, but the reader-side impact is worse — they can't see the markdown source.
R3 — Fabricated faculty / admissions emails. LLMs default to admissions@cs.<school>.edu when they don't know — almost always wrong. School admissions are often centralized (gradadmissions@school.edu) or portal-only. Verification method: WebFetch the department's "Contact" / "Graduate Admissions" page, cite only verbatim. Mark UNVERIFIABLE rather than guess; tell the user to use the portal.
R4 — Function names / API paths from memory. getUserById sounds reasonable but is actually fetchUserProfile. Function and API names drift; memory is not authoritative. Verification method: grep the literal value in the current codebase, cite file:line, match HTTP method + path + parameter style ({id} vs :id vs ?id=).
R5 — Policy URLs and deadlines. Application deadlines change every cycle; university sites reorganize URLs. Verification method: WebFetch the live page during the verification phase, verbatim-quote the deadline text, log the access date in the footer.
R6 — Intent IDs / event names / schema keys. Wrote intent_id: "user.signup.completed" but the producer is actually emitting User_Signup_Completed. Downstream filters / dashboards / billing all run on that exact string. Verification method: grep the emitter callsite (track( / emit( / producer.send(), match the literal including underscore vs dot vs dash and casing.
R7 — Model IDs / SDK versions. Wrote claude-opus-4-5 but the SDK is on 4-7. Verification method: grep the project lockfile (uv.lock / package-lock.json / poetry.lock), not pyproject.toml or package.json — the lockfile is what's actually running.
Common thread across all seven: the LLM always self-passes them; only grep / WebFetch / lockfile lookup catches them. A verifier subagent runs the seven in 1-2 minutes — what it saves is the 3-week scramble after business catches "this API path doesn't exist" on launch day.

Why the verifier must be "another agent," not the same agent on a different prompt
Verifier must be a physically distinct subagent — having the main agent switch prompts post-draft and "act as a verifier" does not work. The reason is context isolation.
Concrete difference:
❌ Single agent switching prompts to "verifier mode":
- context = [drafting prompt + full draft + verifier instructions]
- same attention distribution; tokens of the draft still bias the verifier
- verifier tends to confirm what the draft already said
✅ Subagent (independent context window):
- subagent only sees [verifier instructions + draft text + claims log]
- no draft-reasoning trace, no prior conversation history
- tools enforced to read-only (no Edit, no Write)
Tool-layer enforcement of read-only matters. Otherwise some verifiers will "just fix the typo while I'm here" — and once it edits, the verifier role collapses. Verify or edit, not both.
The reverse anti-pattern: many enterprise roll-outs implement the "verifier" as another section in the main agent's prompt ("Now act as a fact-checker and review your own output…"). That's pseudo-verification. Self-test: run the same LLM, same prompt, "self-review" mode, ten times — nine times it confirms what it just wrote. If the vendor's "AI review" pipeline can't be drawn as two independent agents with two independent context windows on the architecture diagram, no verification is happening.
3-round cap + explicit UNVERIFIABLE + never silently downgrade
Three hard rules nobody should relax:
1. 3-round cap. Verifier catches FAIL → main agent fixes → verifier reruns. After three rounds still failing, stop — not "try one more time." A FAIL that survives three rounds isn't going to die at round ten.
After three rounds, persistent FAIL usually means:
- The claim has no authoritative source (downgrade to UNVERIFIABLE and surface to the user)
- The LLM keeps making the same mistake (delete that section, or ask the user to fill it manually)
- The user's recollection of the fact disagrees with reality (ask the user — don't guess on their behalf)
The 3-round cap prevents the "LLM patching LLM" trap — every round feels like "one more fix away," but in practice it's divergent.
2. UNVERIFIABLE must be explicitly flagged. When the verifier finds no authoritative source, the verdict is not PASS, not FAIL — it's UNVERIFIABLE, accompanied by "what I tried, why no source exists, what the user needs to do to verify." The final document footer lists every UNVERIFIABLE claim so readers know which parts are still unconfirmed. Honesty with the reader beats pretending to have verified.
3. Never silently downgrade FAIL to UNVERIFIABLE. After three rounds, reporting a FAIL as "couldn't verify" is the single worst anti-pattern in this workflow. FAIL means "verified, wrong." UNVERIFIABLE means "couldn't verify." Reporting FAIL as UNVERIFIABLE breaks the entire gate.
R3 (admissions email) hit this trap: round 1 verifier caught the email is wrong (actual: phd-admissions@ee.stanford.edu); main agent fixed the email but introduced a wrong department name; round 2 verifier caught it again; round 3 main agent gave up and marked the whole section UNVERIFIABLE in an attempt to slip past the gate — that's silent downgrade. The rule: always surface FAIL to a human, let the human decide (delete / replace / leave UNVERIFIABLE with a written reason).
3 things to do this week + 5 questions for your vendor's next review
3 things to do this week:
-
Pick one AI-drafted plan / report / email — your own from last week, or your vendor's latest deliverable — and extract every factual claim into a numbered claims log. Annotate each with "authoritative source" (a
file:lineor URL). Tally how many trace to a concrete source. Under 70% means the claims log isn't granular enough. -
Dispatch an independent session / agent with that claims log to do verification. In Claude Code that's a single
Agent(subagent_type="Explore", ...)call. In other tools, open a fresh conversation window (it must not inherit prior context). Have it return PASS / FAIL / UNVERIFIABLE row by row. -
Bake R1-R7 into your PR checklist or review template — next time anyone internally reviews AI-drafted content, those seven rows must be ticked. Print and pin: enum casing, docx blank lines, faculty email, function / API name, policy URL / deadline, intent ID / event name, model ID / SDK version.
5 questions to ask the vendor at your next review:
-
"What's the authoritative source for each of the N factual claims in this plan?" — They should be able to hand you a claims log with one source per row. If they can't, the doc was LLM-drafted with no human verification.
-
"Is the verification a different LLM, or the same one re-reading?" — Same LLM, same prompt is pseudo-verification. You want to see two independent sessions in the architecture diagram (ideally two different model vendors).
-
"Does the verifier have an Edit tool?" — A verifier with Edit "fixes things along the way" — verification collapses. Read-only is non-negotiable, enforced at the tool layer.
-
"How is FAIL handled? Maximum retries? How is UNVERIFIABLE surfaced?" — "LLM keeps retrying until PASS" means no gate. "Three rounds then handed to a PM" means a real gate. Bonus points for "never downgrade FAIL to UNVERIFIABLE."
-
"Where do the model IDs / SDK versions in this plan come from?" — "LLM-written" is high-risk R7. "Grepped from the lockfile" is acceptable. Lockfile version numbers are what's actually running;
pyproject.toml/package.jsononly describe the allowed range.
Next time you review an AI-drafted contract / proposal / admissions email / internal policy summary, put these five questions in the header row of your review form. A vendor that can't answer the first three deserves a verifier-subagent pass over the whole document — odds are good 30% of the claims are made up.
This is the eleventh post in the Agentic AI in Practice series — tackling the trustworthiness problem of LLM output, not by using a stronger model but by adding a structured gate. Post VII covered dual-track testing — the quality baseline after launch. This post covers the verification gate — the baseline before AI-drafted content enters production. Both in place, AI-drafted material upgrades from "internal draft" to "signable."
Reply with the keyword
VERIFY-KITand I'll send you the toolkit: (1) DRAFT → VERIFY → FINALIZE 3-phase prompt template (including Phase 2 subagent instructions); (2) R1-R7 verification method cheat sheet (PR checklist drop-in); (3) claims-log JSON schema + report template; (4) 3-round + UNVERIFIABLE handling decision tree.
Reply channels in the footer (WeChat / X). Drop your email in the comments if neither works.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.