你以为定义好的意图够用了——1102 条样本里有 800 条说『不』|Agentic AI 落地方法论(十)
《Agentic AI 落地方法论》系列第十篇。 前 9 篇拆「方案能不能上线 + 上线后怎么不放养 + 北极星 + 脑手分离 + 怎么测 + 阈值怎么定 + API 怎么分层」——L0-L3 定级、L2 vs L3 的 5 个架构决策、Critic fail-closed、上线即放养、接住率 vs 解决率、Skills vs 知识库、双轨测试、3 级 intent 级联、五层 API 架构。系列八讲的是意图分类器怎么调阈值,这一篇讲意图体系本身怎么演进——不解决这件事,分类器调到顶也是 60 分。English version: Corpus Drives Codebook — Why Your Intent Taxonomy Is Stuck at 60% and How It Evolves from 36 to 48.
「unknown 占 40%」的真问题不在分类器
某次月度评审,运营把 dashboard 截图扔到群里:1,102 条用户消息,意图识别准确率 59.44%,unknown 占比 40%。
业务方的反应几乎是条件反射:「这 40% 加点 LLM 兜底不就好了?」
乙方研发也按这个思路提了方案:把 LLM fallback 阈值从 0.85 调到 0.7,让更多 unknown 进 LLM 分类。一周后第一次复盘,准确率确实从 59% 提到 67%——但 unknown 几乎没降,业务方拿着列表逐条对:「这 200 条 LLM 还是判错了,为什么?」
研发翻了几十条样本之后承认一件让所有人都不想接受的事——这 200 条的真正问题不是分类器没识别出来,是意图体系里根本没有它们的位置:
- 「我那个退货申请什么时候能通过」——分类器判成
refund_status(退款),其实是return_status(退货审核),但业务定义卡里两个意图边界写得不清楚,怎么判都是 50% - 「不要申请退款了,直接发货吧」——分类器判成
order_cancel(取消订单),其实是「撤销售后申请」,但意图体系里压根没这个意图,硬塞进哪个都不对 - 「你们不给我退货,等着市场监督管理局吧」——分类器判成
complaint_service(服务投诉),但业务侧的规则是「提到外部监管渠道一律转人工」,应该是human_transfer,规则没写进 codebook、分类器无从知道
这一年带的几个客服 Agent 项目,每次撞到 unknown 高都先去查分类器——80% 的情况其实是意图体系(codebook)本身没设计好。意图体系是 codebook,分类器只是它的实现。codebook 缺一个意图,分类器再聪明也没法识别出来;codebook 边界写不清,分类器再准也是抛硬币;codebook 命名不一致,标注师标的和规则匹配的对不上,准确率天然封顶。
这一篇拆三件事。
第一,怎么从用户真实话术 corpus 里反向发现意图体系的缺口——4 类系统性混淆,每一类都给具体样本。
第二,业务说「加一个意图」之前,先用四象限判定规则过一遍——多数「缺失意图」根本不是意图,是参数槽位、会话状态、或多模态信号。
第三,一套3 轮 diff 的演进流程——36 → 45 → 46 → 48 的真实路径,每一轮谁拍板、加了什么、拒了什么、改名涉及多少下游文件。
下次有人在评审会说「unknown 高,加点 LLM 兜底就好了」,你能把这篇里的判定规则拍他脸上——unknown 高几乎从来不是分类器的问题,是 codebook 的体系性缺陷。
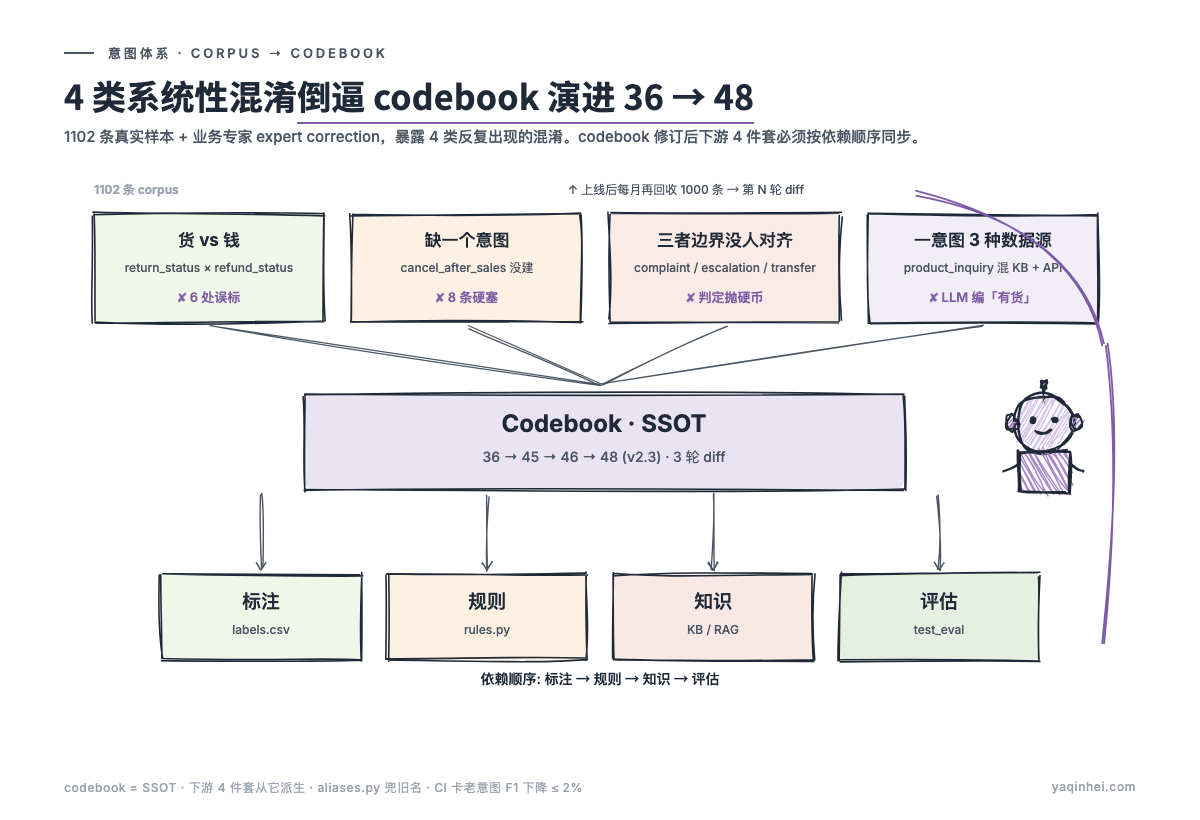
1102 条样本回收暴露的 4 类系统性混淆
先把结论摆桌面上:意图体系的缺陷,单靠桌面 brainstorm 找不出来。必须把真实 corpus 标完一遍、让业务专家做 expert correction、再统计哪些标签被反复改成同一个错误。3 个月攒下来的 1,102 条样本回收后,4 类系统性混淆暴露得非常清楚。
混淆一:用户分不清「货」和「钱」,意图体系硬要分
return_status(退货审核进度)和 refund_status(退款到账进度)是两个独立意图——前者读工单审核状态,后者读财务到账状态,后端调的是两套接口、SLA 算法也不一样。
但用户侧没人这么想。专家审核 1102 条样本时发现 6 处把「问审核进度」误标成 refund_status:
- 「我那个退货申请什么时候能通过?」——业务方第一反应这是问钱,其实「通过」=审核通过
- 「这售后审核的速度太慢了」——「审核速度」明明指的是货
- 「货退给你们了,你们都签收了,退钱啊」——这条真的是 refund_status,因为用户的关注点已经从「货能不能退」过渡到「钱什么时候到」
根因不在分类器,在 codebook 把这个边界藏起来了。原版意图定义卡里 return_status 和 refund_status 都只写了一句话定义,没写易混淆反例、没写「用户侧不区分时怎么判」的判定规则。
修复动作(codebook 层,不是分类器层):
return_status:
定义: 用户询问退货工单的审核进度(货侧动作)
典型: "审核到哪了" "什么时候通过" "退货速度"
反例(应判 refund_status): "钱什么时候到" "少退钱了" "退款没到账"
反例边界规则: 同时提货和钱时,看落点 ——
"退给你们了,退钱啊" → 关注点已经在钱 → refund_status
"退货申请通过了,我的钱呢" → 关注点在审核 → return_status
定义卡 v2 加了这一段之后,标注师的标注一致性从 78% 提到 91%——不是因为标注师变聪明了,是 codebook 把判定规则写进去了。
混淆二:缺一个意图,8 条样本被硬塞进相邻意图
order_cancel(取消订单)和 cancel_order_exec(执行取消订单)这两个意图加起来,业务方专家审核时补了 8 条样本——没有一条是真的取消订单,全是「撤销已经申请的退货/退款」:
- 「怎么撤回退款」
- 「不退了怎么取消」
- 「我点错了,不小心申请退款了」
- 「强烈要求取消退单」
- 「能取消申请退货吗」
- 「那我先把售后取消了吧」
- 「不要申请退款了,直接发货吧」
- 「我买的东西没发货呢,不小心点了退货怎么取消」
意图体系里根本没有「撤销售后申请」这个意图。专家硬塞进 order_cancel,标注师标进去,分类器学到「取消订单 + 涉及售后字样 → order_cancel」,上线之后真的撞上「我要取消这单订单」时反而判错。
这是 corpus 反向发现 codebook 缺口的典型样本:单一样本看不出问题,但同一缺失意图反复出现 8 次就是体系信号。修复动作是新增 cancel_after_sales 意图,下游接工单系统的「撤销售后申请」动作——意图体系从 45 → 46 就是因为这一条。
但抓住这个信号需要做一件特定的事:回收的样本必须有 expert_correct_intent 这一列。标注师只标 mapped_intent 不够,必须让业务专家二次审核「这条样本如果不属于 mapped 里的任何一个,最像哪一个」,然后统计 expert correction 里的高频「相邻意图」——同一错误反复出现 N 次就是 codebook 缺口。
混淆三:三个意图的边界没写进 codebook,标注师抛硬币
complaint_service(服务投诉)、escalation(要求升级)、human_transfer(转人工)这三者业务侧表达接近,标注师做的几乎是抛硬币的事:
- 「你们这售后真差劲赶快反应一下」—— complaint_service?escalation?
- 「我会向你们上海本部高管发送邮件」——提到「高管」是 escalation 还是 complaint_service?
- 「你们不给我退货,就等着市场监督管理局吧」——这条必须是 human_transfer,但标注师标成 complaint_service
- 「转售后」—— escalation 还是 human_transfer?
业务侧后来对齐了三句话定义:
complaint_service: 用户对当前服务表达不满,但没明说要换人
escalation : 明确要求"找经理/主管/上级/负责人"
human_transfer : 明确要求"转人工"或提到"12315/消协/政府热线/律师/法院"
关键判定: 提到外部监管渠道(12315 / 政府 / 法院 / 媒体)一律是 human_transfer
触发立即转接, 不走 complaint_service 慢通道
这段定义写进 codebook v2.1 之后,标注师对齐一致性才稳定下来。重点不在加了多少个新意图——是把那条「关键判定」从隐性的业务常识固化进 codebook。不写进 codebook,靠 30 个标注师每个人记一遍,下一批人进来全部失效。
混淆四:一个意图混了三种数据源,路由没法优化
product_inquiry(商品咨询)这一个意图,专家审核时发现它实际混了三种本质不同的查询:
① "这鞋什么材质" → 静态规格,知识库静态答 (10ms 内)
② "尺码表多少" → 静态属性,知识库静态答 (10ms 内)
③ "还有 42 码吗" → 动态库存,调接口实时查 (500ms+,有时效)
三种查询的:
- 数据源不同(知识库 vs 实时 API)
- 延迟成本不同(10ms vs 500ms)
- 答错代价不同(规格答错=客户不爽;库存答错=客户白跑专柜)
- 时效性不同(规格永久有效 vs 库存分钟级失效)
混在一个意图里的代价不止是数据源混——LLM 在 RAG pipeline 里见到「库存」类查询时,如果检索结果走 KB 而不是库存 API,会编造「有货」。这是上线之后被业务方逮到的,原因追到 codebook 一查:product_inquiry 这个意图当初定义就是混的。
修复动作:意图体系从 45 拆出 3 个独立意图:
product_inquiry(保留,限定为静态规格/属性)stock_availability(新增,动态库存接口)restock_notify(新增,库存订阅动作)
业务专家自己提出来要拆的——不是技术方拍脑袋。证据是 1102 条样本里「问款式存在性」和「问材质」的处理流程在专家眼里就是完全不同的两套话术。codebook 里把它合在一起就是设计错误。
4 类混淆的共同特征:每一类都不是「分类器漏判」,是「分类器面对一个本身就有问题的意图体系,标注/规则/知识三件套从源头就没对齐」。追到分类器调阈值这一步已经太晚了。
「意图 ≠ 用户说了什么」——四象限判定的 4 句话
业务方建议「加一个意图」之前,先用 4 句话过一遍。同一轮回收里业务提了 15 个「缺失意图」建议,技术组按四象限判完之后只有 8 个真的应该加,3 个本来就没这业务,4 个根本不属于「意图」范畴。
四象限判定规则就是这 4 句话:
后端动作不同 → 必须独立意图
仅参数不同 → 不要新建,加 slot 即可
仅表达方式不同 → 同意图的不同说法,进训练样本
仅对话状态不同 → 进会话状态机,不进意图体系
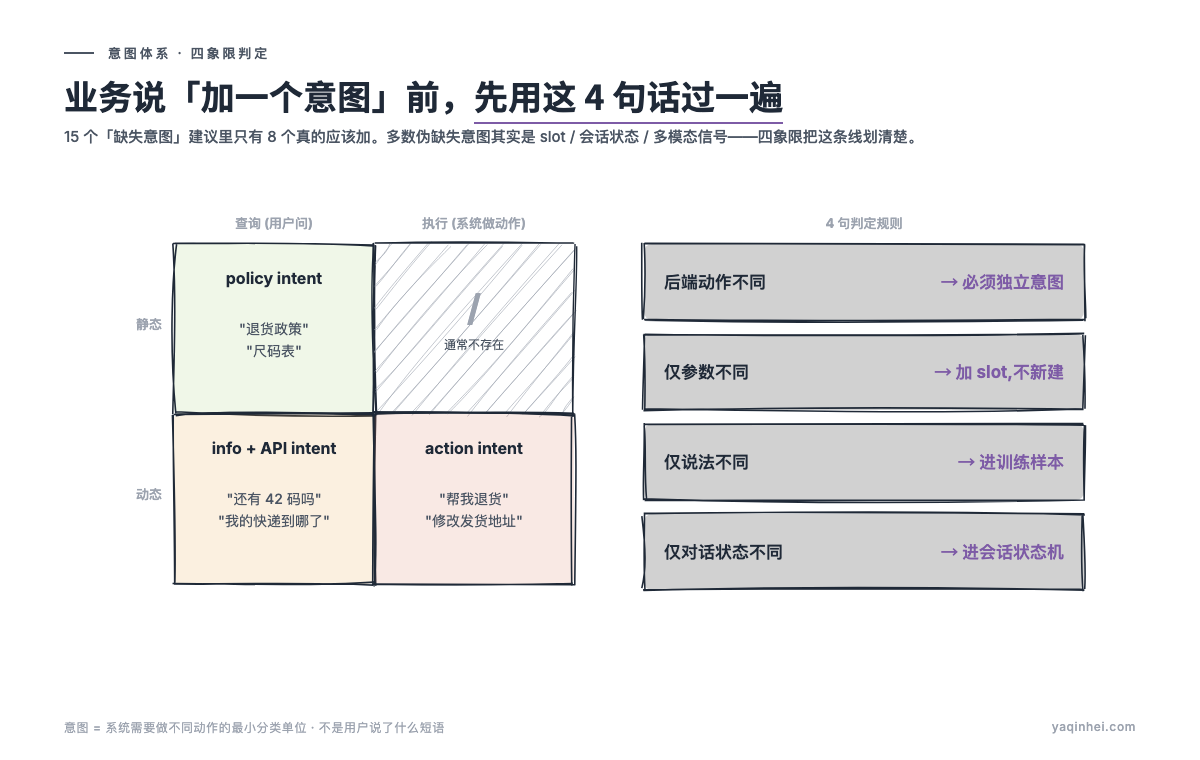
每一条对应一类常见的「伪缺失意图」。
「这其实是个 slot,不是意图」
业务提:「希望支持『发送支付宝账号』这个意图。」
四象限过一遍:后端动作和「退款流程」一样——读用户给的支付宝账号、写进工单、触发对账。仅参数不同——退款流程里多收一个 alipay_account 字段而已。
正确做法:在退款流程里加一个 slot,不新建意图。
「这其实是个对话状态,不是意图」
业务提:「希望支持『稍后拍照』这个意图——用户说『等会儿,我去找鞋子拍』。」
四象限过一遍:用户说「稍后拍照」时,Agent 不需要做新的后端动作——只需要把会话挂起、等用户下一条消息(应该是图片)、然后继续走 complaint_quality 流程。
正确做法:会话状态机加一个 awaiting_photo 状态,不新建意图。把这个加进意图体系,分类器要学到「用户消息=稍后拍照」时返回 delayed_photo 这个意图——但 Agent 拿到这个意图能做什么?什么也不做,纯空跑。
「这其实是个多模态信号,不是意图」
业务提:「希望支持『发送图片』这个意图。」
四象限过一遍:用户发图本身是个 attachment 事件,前端能直接识别——message.attachments != null。识别到之后自动路由到 complaint_quality 流程(绝大多数发图的场景)即可。
正确做法:前端识别 attachment 自动路由,不新建意图。让 LLM 分类器去判「这条消息是不是发图」是用大炮打蚊子——前端 5 行 JS 就能搞定。
「这其实根本没这业务」
业务提:「希望支持『实名认证』『清洁保养服务』『客服在线时间』三个意图。」
四象限之前先问业务一句:「公司有没有这三块业务?」——
- 「实名认证」:公司无跨境/海关业务,没有实名认证场景 → 拒绝
- 「清洁保养服务」:公司不提供该增值服务 → 拒绝
- 「客服在线时间」:进 FAQ 知识库就行,不单设意图
业务方自己不一定第一时间想到这个反问——他们看到客服历史日志里出现过相关问题就会想加。技术方的责任是先确认业务存在性、再决定是不是要建意图。
一句话归一
「意图」=系统需要做不同动作的最小分类单位。
不是「用户说了什么短语」。
不是「客服历史日志里出现过的所有 topic」。
不是「业务方觉得需要被识别的所有用户表达」。
用这一句话过一遍 15 个「缺失意图」建议,剩下 8 个就是真的应该加。
36 → 45 → 46 → 48:3 轮 diff 的演进路径
意图体系不是一次性设计完的,是 corpus → 修订 → 同步下游 → 跑回归 → 再回收的循环。3 个月内走完 3 轮,每轮 diff 都需要业务 + 技术评审拍板,结果如下。
第一轮 diff(36 → 45):corpus 回收暴露的 9 个新意图 + 2 个改名
第一轮基于 1102 条样本的 expert correction 统计,业务提了 15 个新意图建议、3 个合并/拆分疑问。技术组按四象限判完之后:
| 类型 | 数量 | 详情 |
|---|---|---|
| 新增 | 9 | wrong_item / missing_item / return_address / shipping_address_change / price_inquiry / stock_availability / third_party_auth / edit_return_number / restock_notify |
| 改名 | 2 | invoice → invoice_request;invoice_register → invoice_auto_issue |
| 拒绝 | 3 | real_name_auth(无业务)/ cleaning_service(无业务)/ service_hours(进 FAQ) |
| 暂缓 | 4 | 发图(多模态信号)/ 稍后拍照(对话状态)/ 支付宝账号(slot)/ 提醒发货检查(与现有意图重叠) |
每一条「拒绝」「暂缓」都要给业务方写一段为什么——这个文档本身就是给业务方的对齐材料,不是技术内部 memo。
这一轮 diff 是 codebook 演进里信息量最大的一轮。corpus 没回收过的团队,意图体系都是凭想象设计的,跟真实分布对不上很正常。真实 corpus 走过一遍,才知道哪些意图缺、哪些边界乱、哪些根本不应该存在。
第二轮 diff(45 → 46):专家补充区暴露的 P2 缺口
第一轮交付之后,业务专家在「意图定义卡 v2」的补充区又审核了 33 个意图共 ~180 条样本。统计 expert correction 里的高频错位,发现同一缺口反复出现 8 次——就是上一节讲的 cancel_after_sales。
这一轮 diff 只新增一个意图,但发现这个意图的成本极高——如果没有第二轮专家补充区,这条缺口要等到上线 3 个月之后用户反馈「我没法取消售后申请」时才会被发现,而那时下游标注/规则/知识/评估已经按 45 个意图全部部署完毕。
教训:corpus 回收不是一次性的。第一轮回收解决「明显的缺口」,但「不明显的缺口」要靠多轮专家审核 + expert correction 高频统计才能找到。建议节奏:
- 上线前:≥ 1000 条样本回收 + 1 轮专家审核 → 第一轮 diff
- 上线后 1 个月:再回收 1000 条 + 第二轮专家审核 → 第二轮 diff
- 上线后 3 个月:再回收 1000 条 + 第三轮 → 第三轮 diff
3 轮之后意图体系基本稳定,后续是低频的局部调整(每季度 1-2 个意图增减)。
第三轮 diff(46 → 48):落地后发现的合并需求
第三轮的来源不是新增意图,是反过来——意图加多了之后,发现某些意图在 LLM Router(系列八第 8 节讲过的 v2 架构)里应该合并到同一个 sub_topic:
product_inquiry → sub_topic: product
product_compare → sub_topic: product
product_recommend → sub_topic: product
brand_specific → sub_topic: product
price_inquiry → sub_topic: product
↑ 5 个 legacy intent 合并到 1 个 sub_topic
complaint_quality → sub_topic: complaint
complaint_service → sub_topic: complaint
↑ 2 个 legacy intent 合并到 1 个 sub_topic
新增 3 个专门的 sub_topic 处理之前 codebook 缺的边界场景:payment / order_cancel / defect(清仓/特价瑕疵商品)。
这一轮的核心不是改 codebook 标签,是把 codebook 跟下游 LLM Router 的 sub_topic 体系对齐——意图标签是给标注师和分类器看的,sub_topic 是给路由层和工单系统看的。两套都要存在,但要明确映射关系。最终 v2.3 = 48 个 legacy intent + 23 个 sub_topic,靠 LEGACY_INTENT_TO_ROUTE 这张映射表把两套体系绑在一起。
3 轮 diff 走完之后意图体系才算稳定下来。
命名雪崩:改一个意图涉及 10 个文件
意图体系演进里真正贵的不是新增,是改名。一个意图改名涉及 10 个文件,少同步一个,线上就会出现「意图识别准了但回答 fallback、或意图识别不出来但日志里旧名字还在跑」。
第一轮 diff 里 invoice → invoice_request 这一个简单改名,下游需要同步的文件清单:
□ 意图定义卡 v2 (.docx) ← 业务可读源 (给标注师 / 业务评审)
□ intent/codebook.json ← 代码可读 SSOT
□ intent/aliases.py ← 旧名 → 新名兼容层
□ intent/rules.py ← 规则引擎关键词
□ intent/semantic.py + anchors.json ← embedding anchor 向量
□ intent/classifier.py ← LLM few-shot prompt
□ knowledge-base/<intent>_v1.0.md ← 对应知识文件改名 + 内容
□ tests/test_eval_intent.py ← 评估期望 label
□ 内部 plan / 策略文档 ← 文档同步
□ 团队 MEMORY / onboarding 文档 ← 老的 36 → 48
10 个文件。少改一个:
- 没改 rules.py → 规则永远命中老的
invoice,分类器输出和 codebook 对不上 - 没改 anchors.json → embedding 层 anchor sentence 标的是旧 intent 名,相似度算出来正确但 label 错位
- 没改 knowledge-base 文件名 → KB parser 找不到
invoice_request_v1.0.md,retrieval 失败,回答走 fallback - 没改 test_eval_intent → 评估期望旧 label,新分类器输出 invoice_request,evaluation 假阴性,看起来「分类器准确率下降了」
少改任何一个,线上意图体系都在悄悄退化。所以 codebook 演进流程里这一步必须是 PR checklist 强制要求——10 个文件都改完了才能 merge,少一个就 block。
而老数据兼容是另一个独立问题。生产数据库里已经有几万条历史标注用的是旧名 invoice,标注师指南刚改名 invoice_request,新标的数据用新名。两套数据怎么合?
答:aliases.py 兜底。
INTENT_ALIASES = {
# old_name → new_name
"invoice": "invoice_request",
"invoice_register": "invoice_auto_issue",
"nvoice_request": "invoice_request", # 标注师手工录入 typo
"shipping_wrong": "wrong_item", # 旧规则误命名
"清洁保养服务": "product_inquiry", # 业务方填中文的兼容
}
def resolve_intent(raw_name: str) -> str:
return INTENT_ALIASES.get(raw_name, raw_name)
下游代码统一用 resolve_intent(raw_name) 读,老数据自动平滑迁移。
这件事写起来 10 行,省下来的对账时间是周级别——没有 aliases.py,每次改名都要跑一遍数据库迁移脚本把所有历史标签更新,迁移期间下游 query 命中失败,业务方周一看到「日报上意图分布都变了」会找你 escalate 三层。
SSOT + 下游 4 件套同步顺序
codebook 是单一事实源(Single Source of Truth),下游标注/规则/知识/评估必须按依赖顺序改。顺序乱了就是返工,前面改了后面没跟上,回归测试无法判断到底是真退化还是同步没做完。
依赖顺序如下,前者是后者的依赖:
① 标注体系 → 标注表头 + 标注师指南更新
└─ 已标完的样本: 用 aliases 自动迁移
└─ 新增意图 : 补标 ≥30 条/意图
② 规则引擎 → intent/rules.py
└─ 注意 first match wins: action 类意图必须放在 policy 之前
└─ 注意执行信号("帮我/处理/执行")防止误命中
③ 知识库 → knowledge-base/<intent>_v1.0.md
└─ 新增意图必须有对应知识文件,否则回答只能 fallback
└─ 文件名用下划线,不用连字符(KB parser 依赖)
④ 评估基准 → tests/test_eval_intent.py + 评估表
└─ 新增意图至少覆盖 5 条评估样本
└─ 老意图至少 10 条评估样本
为什么是这个顺序:
- 先标注后规则:因为规则引擎从标注样本里提取高频关键词,没标注没法挖关键词
- 先规则后知识:因为知识库的 retrieval 是 intent-gated 的,规则不命中知识也检索不到
- 先知识后评估:因为评估测的是「意图识别 + 知识检索 + 回答生成」端到端,知识没建评估就只能测意图准确率,testing 这一块的 ROI 大打折扣
顺序反过来走的代价:先改了规则但没补标注,规则覆盖率上不来;先改了评估期望但没改知识,回归测试假阴性满天飞,团队精力被消耗在「这是真问题还是同步没做完」的判断上。
回归通过标准(写进 CI gate,自动卡):
| 指标 | 阈值 |
|---|---|
| 老意图 F1 平均下降 | ≤ 2% |
| 新意图 recall | ≥ 60% |
unknown 比例 | 不上升 |
| 单元测试 | 全绿(除已知 expected failure) |
不达标 → 回滚 codebook 修订,重新评审。这一关必须卡死——历史上踩过的坑是「为了赶 release,老意图 F1 下降 5% 但 ship 了」,下个月做用户回访的时候发现历史高频问题答得比之前差,再追回来已经积压了 3 周的脏数据。
这周可以做的 3 件事 + 评审会要问供应商的 5 个问题
3 件这周可以做的事:
- 回收最近 1 个月的真实样本(≥ 1000 条),让业务专家做一轮 expert correction(每条样本:原标签 + 「如果不属于原标签,最像哪个」)。统计 expert correction 里的高频「相邻意图」——同一错位反复出现 ≥ 5 次就是 codebook 缺口信号。
- 按四象限规则过一遍业务方提的所有「缺失意图」建议——后端动作不同→意图、仅参数不同→slot、仅说法不同→训练样本、仅状态不同→状态机。3 句话筛掉一半以上的伪缺失意图。
- 建一个
aliases.py(如果还没有),把过去 6 个月所有改名/typo/老规则的 intent 名都列进去。下次改名时不至于满数据库找历史标签。
5 个评审会上要问乙方/供应商的问题:
- 「你们的意图体系怎么演进的?」——能拿出 3 轮 diff 文档(什么时候加了什么、拒绝了什么、为什么)才说明走过 corpus → codebook 流程;只能拿出一份「最终版意图列表」的,多半是凭想象设计的。
- 「unknown 占比上线后多少?」——上线 1 个月 unknown 仍 ≥ 20% 必须追问原因。如果回答是「加点 LLM 兜底」就是没在 codebook 层找问题。
- 「你们的 codebook 在哪?是 Word 文档还是 JSON?同步机制是什么?」——codebook 只存在 Word 文档里、下游各文件硬编码 intent label 的,下次改名一定全部失同步。要看到
codebook.json+aliases.py兜底层才算成熟。 - 「expert correction 这一列在你们的标注表里有吗?」——没有这一列,corpus 反向反不出 codebook 缺口,意图体系只会越加越乱。
- 「老意图 F1 下降的回归门槛是多少?卡在 CI 里吗?」——回答 ≥ 5% 或者「不卡 CI 评审通过就行」的都是不及格答案。≤ 2% + 卡 CI 是底线。
下次评审会,把这 5 个问题写在 A4 纸上,列在前面。三个问题答不上来的乙方,意图体系演进流程基本是空的——剩下的工程做得再漂亮,3 个月之后线上 unknown 一样会到 40%。
这是《Agentic AI 落地方法论》系列第 10 篇——拆 codebook 演进而不是分类器调阈值。前面系列八专门讲了分类器侧的 3 级 cascade 阈值怎么调,配合这一篇用:分类器决定 codebook 设计好的上限能不能跑到,codebook 决定上限本身。两件事都做对,意图识别准确率才能从 60% 稳到 90%+。
回复关键词「INTENT-CARD」,我把工具包发给你:(1)意图定义卡 v2 模板(含易混淆反例 + 边界规则字段)、(2)四象限判定 checklist(30 分钟评审会用)、(3)codebook.json schema + aliases.py 兼容层最小可用版本、(4)3 轮 diff 评审会议模板。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.