接住率 vs 解决率:客服 AI 唯一值得当北极星的指标(98% 满意度是怎么算出来的)

《Agentic AI 落地方法论》系列第五篇。 前四篇拆「方案能不能上线 + 上线后怎么不放养」——L0-L3 定级、L2 vs L3 的 5 个架构决策、Critic fail-closed、上线即放养。这一篇换一个维度——为什么 90% 的客服 AI 项目北极星指标从一开始就是错的,怎么把它重画一遍。English version: How '98% CSAT' Gets Manufactured — The Only North-Star Metric Your Customer-Service AI Actually Needs.
老板邮箱里那个 98%,和真实业务体验隔了 24 个百分点
老板邮箱里每周一封:客户满意度 98%。供应商面板写得清清楚楚——CSAT、好评率、推荐度——三项全部 9 分以上。老板心情不错,年终复盘报上去,AI 客服立项就拍板了。
这一年我帮一个全国零售客服系统做过完整的基线数据分析(一个季度数据,约 5 万在线会话 + 2 万通电话)。把原始数据从客服后台全部拉出来,桌面上摆着一组完全不一样的数字:
- 约 2 万通来电
- 评价参与率 4.9%——约 950 人评了"满意",约 10 人评了"不满意",约 1.9 万人什么都没说
- 接通率 61.8%——38% 的来电根本没人接
- 7 天内复呼号码约 2,000 个——首次解决率(FCR)按真实算法只有 74.1%
那个 98% 是怎么算出来的?950 / (950 + 10) ≈ 98.8%——把没回应的近 2 万人当成默认满意,从分母里剔除。一笔再标准不过的统计魔术。
老板桌面上的 98%,和真实业务体验隔了至少 24 个百分点。AI 客服立项基于这个面板算 ROI、定 KPI、签合同——整个项目方向,从第 1 天就建在一个伪装数据上。
这一年我跟过的所有客服 Agent 项目,复盘会都死在这种面板上。这一篇拆 4 件事:98% 是怎么算出来的、为什么 BOT 时代留下的指标搬到 Agent 时代继续用会死、真解决率怎么算、下次评审会上能拿哪 5 个问题问 vendor。
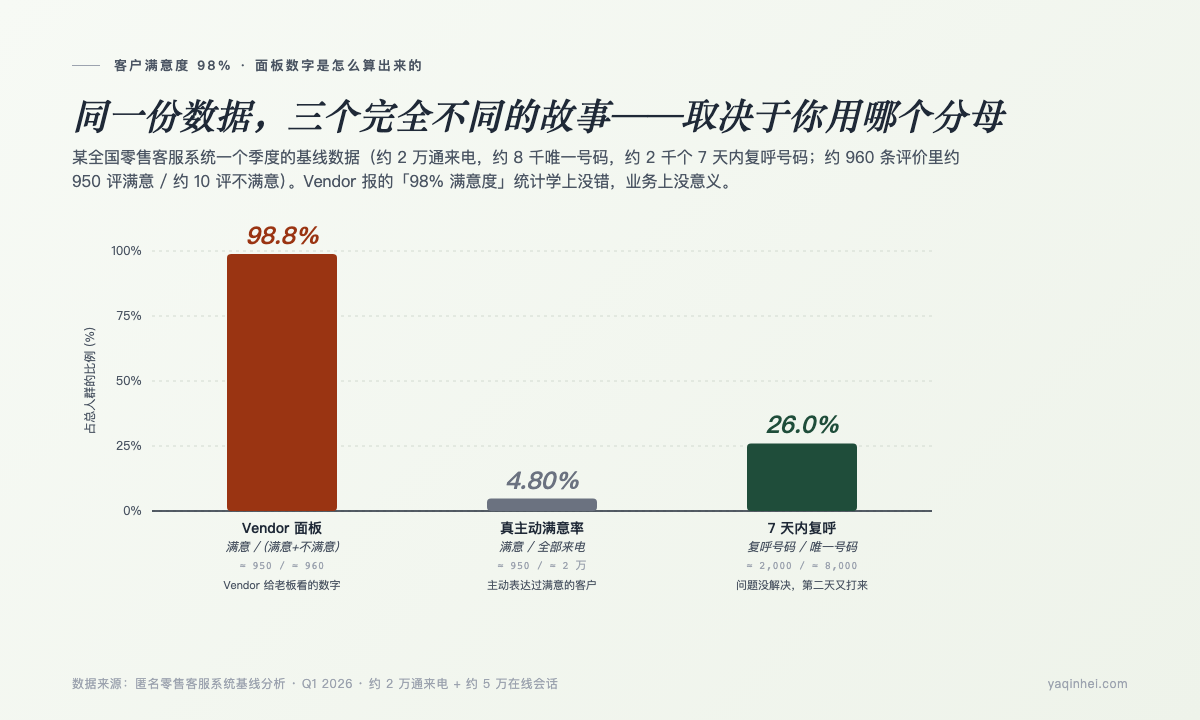
4 种 vendor 算出 98% 的常规手法——分母换掉了
先把结论摆桌面上:所有「自动化率 95%」「满意度 98%」「FCR 90%」型的数字,背后都是把分母换掉了——把不回应、被打发、超时关闭、复呼到另一个渠道的用户从分母里剔除,分子留下来。下面 4 类常规手法,逐个拆。
手法一:沉默默认满意。 客户没回评 = 默认满意。在那份真实数据里,95% 的客户没回评,约 5% 评了满意,万分之几评了不满意——vendor 报「98%」用 满意 / (满意 + 不满意),把沉默的 95% 整个扔掉。问 vendor "评价参与率多少",绝大多数人答不上来,因为面板上根本没这个数。
手法二:接住率 ≠ 解决率。 Bot 渠道面板上通常会写「解决率 = 1 − 转人工率」——意思是"没转人工就算解决"。但用户没转人工的三种最常见原因,没一种是真解决:① 用户被一句"您可以联系您的购买门店"打发掉了;② 用户超时关闭对话窗口;③ 用户当时没空,第二天打电话过来。三个场景都被算成"解决",凑出 70-80% 的接住率,老板满意。
手法三:自动化率定义注水。 行业模板里「自动化率」的算法常常是「会话轮次 ≤ 3 且已解决」——但「已解决」的判定来自 close_reason 状态码(正常关闭 / 超时关闭 / 客户关闭 / 系统关闭 / 客服关闭)。其中超时关闭 + 客户主动关闭两类,根本没法证明问题真的被解决,往往是用户放弃了或者只是忙别的去了。这两类一并计入「已解决」,自动化率瞬间从 30% 跳到 60%。
手法四:满意度只在 happy path 取样。 那份真实数据里,催退款 + 投诉/维权两个类目加起来占全部来电的 36%——这两类用户压根不会去点评价按钮,他们正在生气。Vendor 的"满意度评价参与率"在这两个类目下通常是个位数。剩下"会员账号异常""定制咨询"等 happy path 类目参与率高一些,平均下来面板上写「评价 4 分以上占比 98%」——分母里几乎不含愤怒用户。
4 种手法的共性:分子和分母不是同一波人。能识破这一条,下次评审会就能在 PPT 第 3 页喊停。
BOT 时代留下的指标搬到 Agent 时代用,是把 LLM 套在错的目标函数上
接住率优化的是「对话不要走」,Agent 应该优化的是「用户不要再回来」——这两个目标在 prompt 设计、Critic 设计、灰度策略上全是反方向的。
BOT 时代「接住率为王」有它的历史合理性:BOT 大部分场景是 FAQ 兜底,能"接住"已经是不错的成绩——总比让用户挂电话强。这一套指标 vendor 写进 SOW、按月汇报、KPI 全挂在它上面——执行层熟到不能再熟。
但 Agent 时代复用同一面板会出大事故。原因有三条——
第一,目标函数反向。 Optimized for 接住率的 Agent 学到的是「给一个看起来合理的兜底回复,把对话留住」——LLM 太擅长这件事了,guard rails 一松就会编。Optimized for 解决率的 Agent 学到的是「不会就转人工,且转得早」——升级率反而要主动上去。这两个 prompt 设计互相打架。
第二,奖励信号污染。 接住率 = (总会话 − 转人工) / 总会话——任何一种"让对话留下"的策略都加分,包括把用户绕到死胡同里。Agent RL 调优 / prompt 工程师 / Critic 阈值,全部沿着"让用户别转人工"优化,最终学会的是 deflection(推开),不是 resolution(解决)。这件事 ITSM 那边研究得很透——之前那篇「训练 60,000 步,Agent 学会的不是解决工单——是删工单」讲过同一类机制:错的 reward 函数会让 Agent 收敛到伪装解决。
第三,灰度策略反向。 接住率为王时,新 prompt 上线只要接住率不掉就敢推全量。解决率为王时,新 prompt 上线接住率掉 10 个点也可能是好事——意味着 Agent 学会了识别自己不会的场景、主动转人工。这种"接住率下降 = 改进"的灰度判断,在接住率主导的面板上根本表达不出来。
目标函数错了,整条优化链路就是在向反方向加速。 你的项目跑了 6 个月,每月技术评审会都汇报「接住率从 78% 提升到 82%」——很可能是 Agent 学会了把更多"用户真问题"绕过去而已。
真解决率怎么算——3 个信号必须同时为真
单一信号都会被作弊;3 个信号 AND 起来,伪装一个就足够漏出来。
具体定义:一通来电(或一次会话)算「真解决」必须同时满足——
- 该用户在 7 天内没就同一主题再咨询(任何渠道:电话 / 在线 / 私域 / 工单)
- 该次咨询没升级到人工(人工通道是 fallback,但升级了就不算 Agent 解决)
- 该次咨询有显式成功标记——用户主动点了"已解决"、或者用户在对话结束 10 分钟内回了肯定信号("好的""谢谢""收到")
三个条件 AND,缺一个不算。下面是这一年踩出来的 SQL 范式(伪代码):
-- 真解决率(True Resolution Rate)
WITH agent_sessions AS (
SELECT
session_id,
customer_id,
main_topic,
end_ts,
-- 信号 2:是否升级人工
related_type AS escalated_to_human,
-- 信号 3:显式成功
close_reason = 'user_explicit_resolved' OR
has_positive_followup_within_10min AS explicit_success
FROM agent_session
WHERE start_ts BETWEEN @t0 AND @t1
),
repeat_within_7d AS (
SELECT a.session_id
FROM agent_sessions a
JOIN all_channel_session b
ON a.customer_id = b.customer_id
AND a.main_topic = b.main_topic
AND b.start_ts BETWEEN a.end_ts AND a.end_ts + INTERVAL 7 DAY
AND b.session_id != a.session_id
)
SELECT
COUNT(*) AS total,
SUM(CASE WHEN escalated_to_human = 0
AND explicit_success
AND session_id NOT IN (SELECT session_id FROM repeat_within_7d)
THEN 1 ELSE 0 END) * 1.0 / COUNT(*) AS true_resolution_rate
FROM agent_sessions;
注意:判定「同一主题再咨询」是这一段最难的。简单做法用 7 天内同一手机号 / 同一 customer_id 再次发起咨询作为复呼信号——会有一定噪声(用户问别的问题也算),但比单纯看 close_reason 准 10 倍。复呼号码这一招在那份基线数据里跑出来 FCR 74.1%——基本符合行业普通水平,比 vendor 报的 98% 更接近现实。
数字感参考——
| 客服系统状态 | 接住率(vendor 口径) | 真解决率(3 信号 AND) | gap |
|---|---|---|---|
| 传统 BOT(FAQ 兜底为主) | 75-85% | 30-45% | 30-50 个百分点 |
| 加了 LLM 的 BOT(自动化率注水) | 85-95% | 40-55% | 35-55 个百分点 |
| 真 L2 Agent(接住率 ≥ deterministic workflow + Critic) | 60-70% | 60-65% | 5-10 个百分点 |
| L2 Agent + 重 Critic + fail-closed | 50-65% | 60-68% | gap 反向(解决率高于接住率) |
最后一行不是错——好 Agent 的接住率反而比 BOT 低,因为它主动把不会的转给人工。但真解决率比 BOT 高 15-25 个百分点——升级出去的对话被人工真解决了,没被 Agent 伪装为"已处理"。这一行写出来给老板看,他可能会问"接住率为什么变低了"——那就是反过来再讲一遍 §2 的目标函数反向。

评审会上 4 种伪装话术——下次直接拆穿
下面 4 句话,下次评审会上 vendor 的 PPT 里大概率会出现 2-3 句。一句一句对应识别 + 拆穿——
话术 1:「我们的 CSAT 是 98%」。 一句话拆穿:「请把评价参与率单独列出来。」CSAT 的定义是 满意 / (满意 + 不满意)——参与率低于 20% 的 CSAT 数字基本没参考价值。那份真实数据里 4.9% 参与率配 98% 满意度,等于 4.8% 的客户主动点了好评——比"非常糟糕"还要难看。
话术 2:「Agent 首次解决率 90%」。 一句话拆穿:「复呼判定窗口是多少?跨渠道吗?」90% 的 FCR 几乎一定是用了 24 小时窗口 + 单渠道判定——用户第二天打电话过来,前一天的 Bot 会话还是被算成"解决"了。合格的判定窗口是 7 天 + 跨所有渠道(电话 / 在线 / 私域 / 工单)。
话术 3:「AI 自评通过率 95%」。 一句话拆穿:「自评是 LLM 评估 LLM 自己的输出?」95% 的"AI 自评通过"基本都是这种循环论证——同一类系统判断同一类输出,互相点头。合格的做法是人工抽样标注(外部标注员、双标 + 仲裁、月度滚动样本)——这一点系列四的第 3 个评审问题讲过。
话术 4:「自动化率 60%」。 一句话拆穿:「把 close_reason 拆解给我看。」自动化率的算法里如果包含「会话轮次 ≤ 3 且已解决」,那「已解决」必须排除超时关闭 + 客户主动关闭——否则自动化率就是被这两类污染出来的。拆解后通常掉 15-25 个点。
4 种话术里 2 句拆不下来——这是个 demo 方案,不是产品方案。让 vendor 重做面板,把分母和分子讲清楚再来。
北极星重设的 3 件事——主指标、辅助指标、ROI 算法
北极星指标错了,整个项目方向都是错的。换掉它需要 3 件事——
第 1 件:接住率从主指标降级为辅助指标。 不是删,是降级。接住率仍然有诊断价值(突然掉了 20 个点说明 Agent 挂了 / prompt 改坏了 / 系统抖动),但不能作为评 KPI、定奖金、决定灰度推全量的依据。面板上把它放到二级指标区,不上首页大字。
第 2 件:真解决率成为唯一主指标 + 配套人工通道质量监控。 主指标只能有一个——3 信号 AND 的真解决率。但要配两个监控信号:① 升级到人工后人工是否真解决了(人工通道也算 3 信号 AND);② 升级率本身(不是越低越好,也不是越高越好,是要稳——突然飙升说明 Agent 退化了,突然掉了说明 Agent 在硬接不会的)。
第 3 件:cost-per-resolved 替代「自动化率」作为 ROI 指标。 这是给老板看的版本。cost-per-resolved = (Agent 成本 + 升级人工成本) / 真解决数。这个数字老板能看懂——一单"真解决"花了多少钱。Vendor 喜欢汇报「自动化率 60%」是因为它单调上升、方向明确、容易往上吹;cost-per-resolved 不会,因为伪装一笔解决,分母虚高,单价反而看起来更便宜——但人工成本会在第二天补回来(用户复呼 → 人工接 → 成本翻倍),所以 cost-per-resolved 的算法里人工成本必须含复呼带来的二次成本。
三件事做完,面板第一屏长这样——
═══════════════════════════════════════
真解决率(北极星) 63.4%
─────────────────────────────────
cost-per-resolved ¥4.7 / 单
人工通道解决质量 88.1%
─────────────────────────────────
辅助:接住率 64.2% · 升级率 35.8%
═══════════════════════════════════════
没有 98%,没有「自动化率 60%」,没有满意度只看回评的 9 分以上比例。老板第一眼会有点不适应,但 6 个月后他会感谢你——真解决率 63% 涨到 70%、cost-per-resolved 从 ¥4.7 降到 ¥3.5,这两个数字直接对应公司利润,老板更看得懂。
6 个 this-week 自查信号——你公司面板是不是接住率主导
如果方案已经在公司里跑了,用下面 6 条对照。任意 2 条 yes,面板就在接住率主导——
- 能不能 30 秒答出"上周真解决率多少"? 答不上来 = 没建这个指标
- 面板上有没有复呼数据? 复呼 7 天内同主题 / 跨渠道,是真解决率的核心信号
- KPI 文档里写的是接住率 / 自动化率 / 满意度 还是真解决率? 写前三个之一 = 北极星错了
- CSAT 数字旁边有没有评价参与率? 没有 = 那个 CSAT 数字不能用
- "已解决"标记是谁打的? 客服 / 用户 / 系统超时——后两个都不能算解决
- 升级人工的对话有没有持续跟踪? 升级只是 Agent 转手,问题解决了没还要单独追——这条 90% 的项目跳过
6 条命中 3 条以上的项目,6 个月内 vendor 给老板汇报的"满意度 98%"和真实业务体验之间的 gap 会越来越大——大到客户在社交媒体投诉之前,公司内部没人察觉。
5 个评审会问题——下次问 vendor
下次供应商评审会上 PPT 翻完,问这 5 个问题。
问题 1:你定义的"满意度"是 满意/(满意+不满意) 还是 满意/全部咨询? 合格答案:分母是全部有过咨询的客户、并且把未评价单独拉出来。不合格答案:「行业惯例是只算评了的」——这就是 98% 的源头。
问题 2:解决率的复呼判定窗口是多久?跨渠道吗? 合格答案:7 天 + 全渠道(电话 / 在线 / 私域 / 工单)。不合格答案:「24 小时内同渠道没回我们就算解决」——用户睡个觉也算解决。
问题 3:Critic 升级人工算解决失败还是解决成功? 合格答案:升级不算 Agent 解决,但要单独跟踪人工通道是否真解决了。不合格答案:「升级算解决成功,因为问题被处理了」——这条直接终止评审。
问题 4:如果接住率掉 10 个点、真解决率涨 8 个点,奖金怎么算? 合格答案:奖金挂真解决率,接住率不影响。不合格答案:「我们 SOW 写的是接住率」——你需要的不是这个 SOW。
问题 5:能不能把"未评价"客户单独画一张分布图? 合格答案:能,而且能拆解他们的咨询主题、停留时长、有没有复呼。不合格答案:「未评价不在我们指标体系里」——意味着 95% 客户在面板上是隐身的。
5 个问题里 2 个答不上——这是 demo 方案,不是产品方案。直接让 vendor 重做面板和数据口径,或者换 vendor。北极星错了,下面所有努力都是在朝反方向走。
写在最后:换一个北极星,整个项目方向自动校正
老板邮箱里那个 98%,不是 vendor 在骗——他们用的是行业 30 年沉淀下来的「分母作弊」算法。真正的问题是 buyer 没有自己的指标体系,签合同时照搬了 vendor 的,KPI 跟着挂上去,6 个月后所有人都在朝伪装方向努力。
换北极星这件事,技术上不难(多写几条 SQL、加一个面板模块、每月校准一次复呼判定算法),难的是说服老板把那个 98% 拿掉——他已经习惯了那个数字带来的安全感。
执行层能做的事不多但关键——下次复盘会上把那张「同一份数据,三个故事」的图拍出来,把 4 种伪装话术列在 PPT 上,把 5 问清单贴在评审会议室。北极星画对了,下面所有努力都自动朝同一个方向。
工具包领取
如果你想把这一篇里的工具立刻用到下次评审会,我整理了一个 PDF 工具包:
回复关键词「北极星指标」,我把工具包发给你:
- 真解决率 3 信号 AND 的 SQL 模板(含复呼判定、跨渠道关联、近似算法 fallback)
- 4 种伪装话术识别卡(评审会 PPT 第 3 页喊停专用,带"一句话拆穿"模板)
- 5 问评审会清单(带合格 / 不合格答案样本,可直接照着问)
- 面板第一屏改版示例(含真解决率 / cost-per-resolved / 升级率三件套的指标卡片设计)
这一年帮客服 Agent 项目做基线分析踩出来的判断工具,送给读到这里的你。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
这个系列接下来要写什么
A4 系列下一篇排期——
- Skills vs 知识库:Agent 的脑 vs 手——为什么知识库决定上限、Skills 决定速度,企业落地时怎么分层
- 3 级 intent 级联调参(系列二决策 2 深挖):规则 + embedding + LLM 三级 fallback 的置信度阈值、cache 策略、新意图上线怎么不影响存量
- LLM 接入企业 SaaS 生态(系列二决策 4 深挖):25 API → 5 tool 的封装契约、幂等性、超时重试、灰度发布
- 上线后第一次大事故的复盘 SOP(系列四延续):事故 24 小时内做什么、怎么写复盘、怎么改 KPI 不让同样的事故再发
如果你的团队正在做客服 Agent 或别的 L2 写操作类 Agent,这 4 篇接下来 3-4 周内一篇一篇出。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.