5 个架构决策,决定你的客服 Agent 能不能上线——为什么必须做成 L2,而不是 L3|Agentic AI 落地方法论(二)
《Agentic AI 落地方法论》系列第二篇。 第一篇《28 个所谓 Agent 项目,只有 5 个是真的》给出了 L0-L3 分级框架——对齐语言、看清现状。这一篇兑现上一篇结尾的预告。在那张 5 个真 Agent 的清单里,客服 Agent 到底怎么做?为什么不能用 L3 autonomous?English version: Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship.
一笔被自主链路推过去的退款
某个零售客服 Agent 项目进入试点。供应商方案号称 "L3 多 Agent 自主规划"——LLM 看完用户对话,自己决定查哪个系统、调哪个 API、给出什么动作。Demo 视频里 Agent 自主完成退款全流程那一段非常炫。业务方看完,签字试点。
试点第二周,一通真实对话。用户敲下「我要退」。Agent 的自主决策链:查订单(成功)→ 命中 "7 天无理由退货" 政策(成功)→ 调财务 API 发起退款(成功)。干净利落。
但这单是「品牌寄售」模式——平台只负责门店和履约链路,实际由品牌方发货,平台没有货权。这种单的退款不能直接发,本该走「平台先垫付、再向品牌方追回」的人工审批流程。否则平台账上没账可对,品牌方那头还在按原订单发货。
24 小时后,舆情爆发。用户拿到了退款,品牌方还在催发货,客服群里一片混乱。复盘会上大家以为 LLM "判错政策"。真相是它根本不知道这单的归属层。
「平台直营」和「品牌寄售」这种分层,在系统里只是订单表的一个隐藏字段,业务文档里写得很简单。但这种「看不见的边界」在 L3 自主规划下,没人去喂给 LLM——它会沿着自己以为合理的路径一路走完,然后让你为这个"合理"买单。
这不是 LLM 不够聪明,也不是供应商不够努力。是 L3 自主规划本身,在企业客服这种场景上不该用。
不能用 L3,那该怎么做?这一年我在做客服 Agent 项目里看到的,能稳定上线的客服 Agent 全是 L2——但 L2 设计本身也有几个关键岔路口。岔错了,要么退化成"加了 LLM 的 BOT"、要么吹成 L3 但根本上不去。
5 个岔路。每个 5 分钟想清楚。下面。
为什么 Demo 视频里最炫的方案,上不了线
先把结论摆桌面上:L2 客服 Agent 必须用 deterministic workflow,LLM 只在节点里填参,不规划路径。
这是反直觉的。Demo 视频里 L3 多 Agent 自主协作那一段总是最炫的——一个 Agent 召唤另一个 Agent、自主选择下一步、自己反思自己改方案。老板看完拍板"我们也要做"。但反过来——这件事很重要——这一年我跟过的客服 Agent 项目里,能稳定上线的全是看起来「笨」的 deterministic workflow,越像 L3 demo 的方案上线越翻车。下面三条理由解释为什么。
可逆性。 客服 Agent 的写操作——退款、改单、创工单、扣库存、给用户发短信——大都不可逆,或非常难追回。退款发出去,钱已经到用户卡上,追回要走单独的撤销流程。工单一旦创出来,负责门店收到通知,再撤销也需要人工跟进。短信已经发出去,挽回不了用户已经形成的预期。让 LLM 自主规划 = 让一个会幻觉的人按"是 / 否"按钮。而且按完没有 undo 键。 Deterministic workflow 的价值就在这——每一条可能的执行路径都是人工设计 + 业务专家评审过的,每条路径走到写操作那一步之前,一定有规则关卡和(下文要讲的)Critic 二次审核。L3 autonomous 的设计哲学是 "LLM 足够聪明、能自己判断"——但企业客服场景,赌"足够聪明"的代价不是用户投诉,是真金白银。
归责。 客服项目上线之后,永远会被三类人追问"为什么走这条路径"。客诉用户问:「我明明没要求退款,你们怎么就退了」。监管/合规问:「这笔退款的审批链路是什么」。内部复盘问:「上周的事故,Agent 在哪一步判错的」。Deterministic workflow 有完整的执行日志可查——意图节点输出什么、路由到哪条边、Critic 判定什么、最终走到哪个动作。每一步都能定位。Autonomous 的 prompt 链给不出答案。LLM 内部"想了什么"是 black box,每次执行路径都不一样,复盘的人只能拿到一段对话和一个动作——中间发生了什么,LLM 自己也说不清。责任落不下来,就没人敢拍板上线。这件事在做企业项目的人手上分量很重。供应商可以拿"模型黑盒"当解释,业务方上线后出了事不能拿这个跟老板交代。
可观测性。 Autonomous 每次执行路径都不一样 → 测试集不可能覆盖所有路径 → 实际线上风险无法度量。举个数字感受一下:一个客服 Agent 涉及 20 个意图 + 6 个外部系统 + 5 种写操作。Deterministic workflow 下,所有可能路径(含分支)大约几百条,每条都能写测试,上线前测试覆盖率能给出明确数字。Autonomous 下,理论路径是组合爆炸的——LLM 在每个节点都可能选择不同方向。你能写的测试只能 cover 已经发生过的对话,没发生过的全是盲区。Autonomous 给不出测试覆盖率。
把这三条理由翻译成架构,L2 的本质长这样:固定 workflow 状态机(人工设计 + 业务专家评审),每个节点 LLM 判断该走哪条边 + 填参数,然后进入下一个节点 / 终止 / 升级人工。LLM 不规划路径,只回答某一步该往哪走。Workflow 由人工设计 + 业务专家评审,所有可能路径都被穷举过,每条边都有测试。
具体到一个真实场景:退款判定怎么做?错误做法是把"退款判定"做成一个 prompt,喂给 LLM 整个用户对话 + 所有可用 API 描述,让它自己决定查什么、判什么、最后调什么 API。正确做法是把"退款判定"做成一个固定 6 步 workflow——识别订单归属层、拉物流状态、核对时效政策 + 商品状态、决定执行路径、Critic 二次审核、执行 + 留痕。每一步 LLM 只回答这一步的问题。Workflow 的下一条边由"当前步骤的输出 + 业务规则"共同决定,不是 LLM 自由 plan。开篇那个事故里,LLM 直接跳过了第 1 步(识别归属层)——在 deterministic workflow 下这个跳过根本不可能发生,因为没有 LLM 自由规划路径的余地。
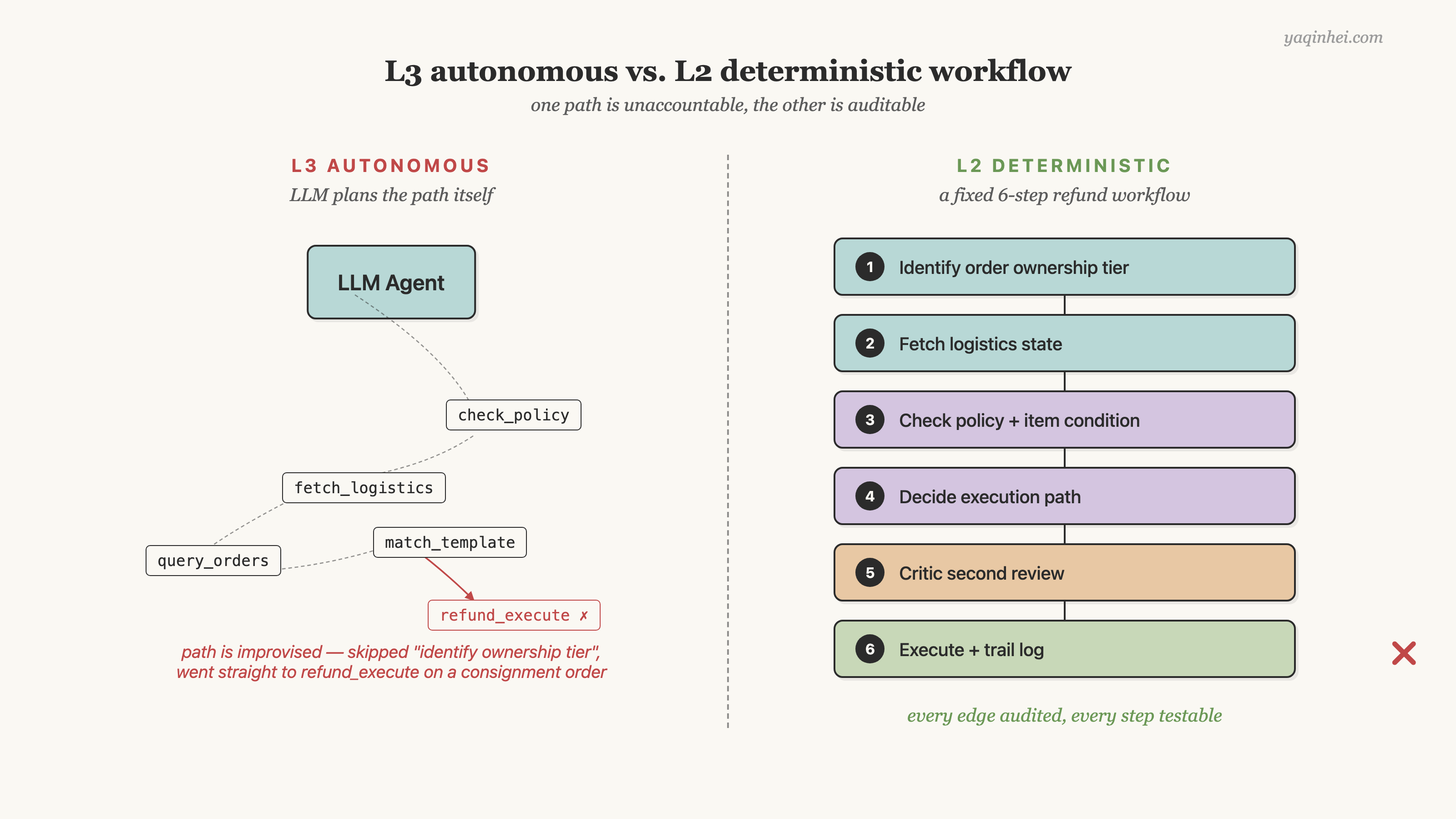
几个迹象,意味着架构是"autonomous 的伪装"。供应商说「我们 Agent 自主规划路径」——问他路径列表能不能枚举出来,枚举不出来 = autonomous。交付物只有「100 个对话样例」而不是「workflow 的每条边都覆盖」——同样的问题,因为 80% 的上线后对话都没测过。架构图里没有状态机,只有「LLM Router + Tool Calls」这种笼统的框框——大概率是 L3 autonomous 在干净图后面包装。真 L2 的架构图一定能画出每个意图对应的 workflow 状态机。
那 deterministic workflow 里的核心节点——意图分类、API 路由、政策判定、写操作、评估——各自怎么设计?接下来 4 个决策。
意图分类的三级 fallback
意图分类是 workflow 的第一个节点——用户进来说一句话,先得知道他想干嘛,才能路由到对应的 workflow。这一步选错,后面 4 个决策都白做。
纯规则太脆、纯 LLM 太贵——3 级 fallback 是工程上 only viable 路径。这是我看到所有稳定上线的客服 Agent 共同的选择。
架构很直接。用户输入先过规则。规则覆盖"标准表达"——「我要退货」「物流到哪了」「我要查订单」——高频出现、表达方式稳定,规则匹配快、准、便宜,能 cover 60-70% 的输入。规则 miss 的,落到 embedding 语义检索,覆盖"换种说法"——「这个东西我不想要了」实际是退货意图,但规则匹配不到;embedding 把它和"我要退货"映射到同一片语义空间,召回成功。embedding 仍然不确定的,落到 LLM 分类,覆盖"长尾 / 复合表达"——「我昨天买的鞋子穿着不舒服,店员说可以退但是我现在想换个颜色行不行」这种长句套着多个意图,只有 LLM 能拆得清。LLM 也不确定的,老老实实交给人。别强行猜——猜错的成本远高于"早一步转人工"。
trade-off 是机械的。每升一级——成本约 10x(规则 ≈ 0;embedding 几分钱/次;LLM 数毛/次),精度 +10-15%(每级 cover 上一级 cover 不到的长尾),延迟 +200-500ms(embedding 比规则慢一个量级,LLM 又比 embedding 慢一个量级)。3 级 fallback 的本质是——用最便宜的解决 80%、用稍贵的解决 15%、用最贵的兜底 5%,剩下转人工。任何把这个比例做反的方案,要么成本失控、要么延迟撑不住高并发、要么准确率上不去。
关于意图体系本身说一句。3 级 fallback 是技术架构。意图体系本身——你的客服总共有多少个意图、每个意图怎么定义——不是一次设计完的,是 corpus → codebook 的多轮迭代。一个真实的客服项目,意图体系从 v1 的 36 个演进到 v2 的 48 个,每次扩充都是因为线上数据告诉你"这一类问题在 unknown 里高频出现"。这是本系列后续单独一篇的话题。
值得警惕的两个信号。供应商说「我们直接用 LLM 分类,简单可靠」——成本会失控(高并发场景每天百万级调用,按 LLM 单价算月成本到六位数),延迟也撑不住(用户每发一句话等 1-2 秒)。供应商说「我们 100% 用规则匹配,绝对可控」——意图体系一旦超过 30 个,规则之间会打架,维护成本指数级,工程团队半年内必反弹。
3 级 fallback 的具体调参——置信度阈值怎么定、什么时候该 cache、unknown 的二次召回怎么做、新意图上线怎么不影响存量——会单独写一篇深挖。
Critic 为什么必须 fail-closed
写操作是出事的地方。退款、改单、创工单、扣库存、给用户发短信——任何会改业务状态、产生不可逆后果的动作。L2 客服 Agent 上线之后,所有事故的源头都在这一类节点——其他节点错了顶多输出别扭、用户骂街,写操作错了就是真金白银 + 舆情爆发。
结论有两部分。写操作的 LLM 决策必须配 Critic 二次审核。而且 Critic 必须在 timeout / error 时升级人工,不能放行。第二句是反直觉的,是大部分团队会做反的地方。
为什么单个 LLM 直接执行写操作不行,三个老毛病。它会幻觉——自信地输出错的判断。「这单符合 7 天无理由退」——但忘了商品已经被使用过。它看不到全部上下文——context window 是有限的,长对话里早期的关键信息会被挤出去。它不会承认不确定——低置信度的输出长得和高置信度一模一样,没办法从输出本身判断"这次它把握不大"。第二个 LLM 来"审稿"——一个出方案、另一个审方案——这是 Critic 的来源。本质就是 AI 互相校稿。
有意思的问题是 Critic 自己遇到麻烦的时候怎么办。三种情况:超时、报错、置信度低。这三种情况下,Critic 自己也没给出明确判断。问题是:放行还是不放行?
Fail-open 设计是说:第一个 LLM 判定「该批退款」,Critic 超时或报错,"反正 Critic 失败了" → 放行第一次的判定 → 退款发出。Fail-closed 设计是说:第一个 LLM 判定「该批退款」,Critic 启动,超时 / 报错 / 网络挂 / 置信度低——任何一种 → 升级人工。只有 Critic 明确返回"通过" + 高置信度 → 才执行。
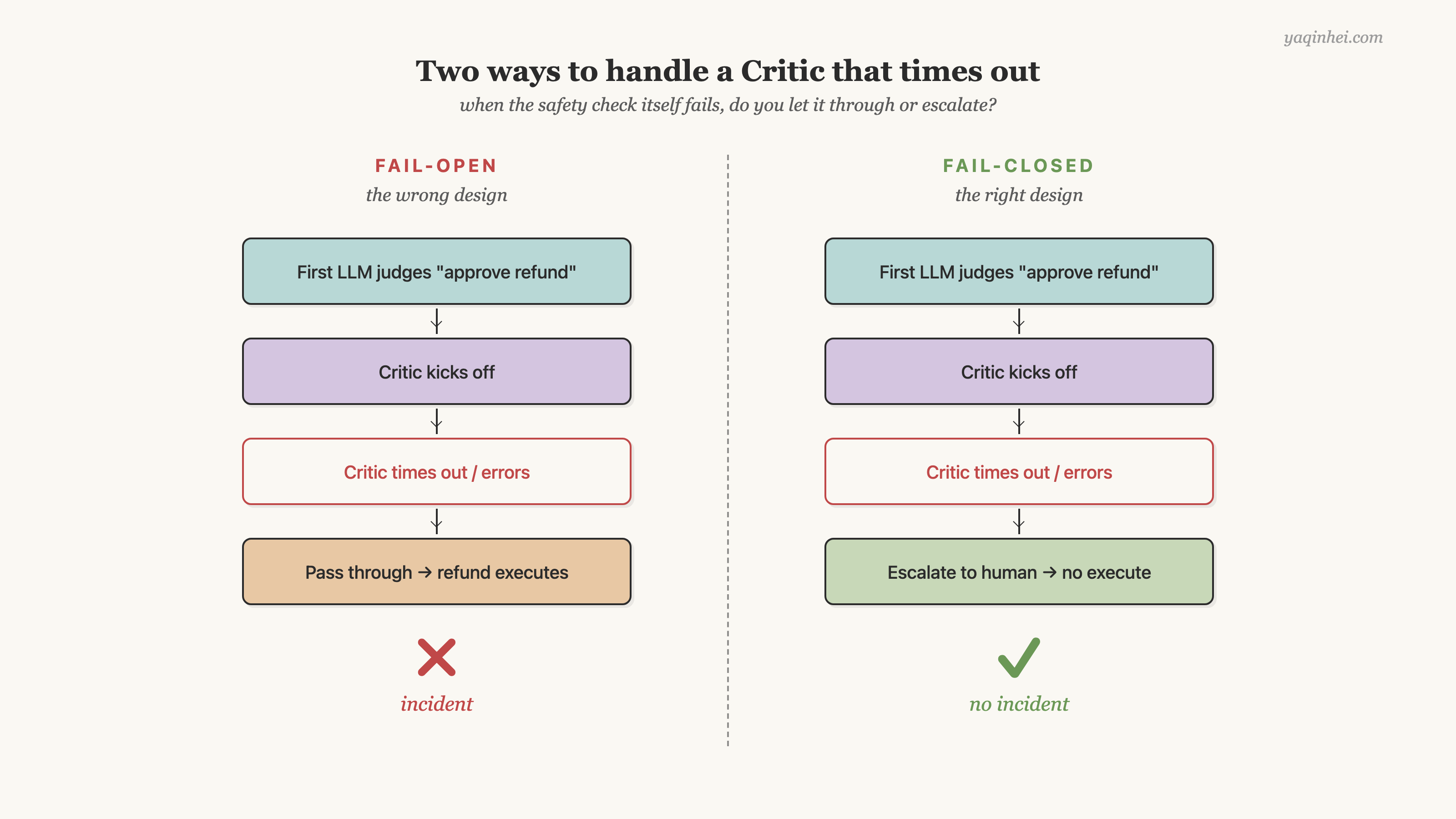
Fail-open 设计总是错的,原因要分三层。超时通常意味着 LLM 服务降级——模型负载高、网络抖动、上游限流——质量本来就没保障。正是最需要审查的时刻,反而被放过去。错误通常意味着输入异常——数据脏、corner case、对话里有了没见过的字符或结构——正是最需要 Critic 看一眼的时刻,反而被跳过。放行 = 把"兜底"做成"自欺欺人"——业务方以为有 Critic 保护,实际很多次 Critic 根本没起作用,但事故出来之前没人知道这一点。
"写操作的兜底设计要 fail-closed"——这是金融行业 30 年的经验,移植到 LLM 系统不需要重新发明。
自然的反问:人工兜底率会升高吗?会。短期升高,长期下降。起步阶段,Critic fail-closed 会导致 30% 左右的写操作升级人工。这个 30% 恰好是宝贵的反馈——观察哪些场景 Critic 不放心,反哺 workflow 设计、补 prompt、调阈值。跑稳之后,人工兜底率会降到 5% 以下,自动化率反而高于 fail-open 设计——因为 fail-open 设计起步就出事故、被迫整体下线整改、再也起不来。别在起步阶段为了"自动化率 KPI 好看"把它做成 fail-open——这是我看到客服 Agent 项目最常见的死法之一。
两个值得警惕的信号。供应商展示「自动化率 95%」——问他「Critic 超时怎么办」,答「自动放行」就一定出事故。没有 Critic、第一个 LLM 直接执行写操作——本质是 L3 autonomous,不是 L2。一切退款 / 改单 / 创工单 / 资金类动作,只要没有 Critic 二次审查,企业客服场景不能上线。
Critic 的具体设计——prompt 怎么写、阈值怎么定、人工兜底队列怎么管、什么时候用规则 Critic 什么时候用 LLM Critic、Critic 本身怎么 eval——会单独写一篇深挖,是整个系列最反直觉的一篇。
25 个 API,应该长成 5 个 Tool 的样子
客服 Agent 不是一个孤立系统。它要嫁接到企业现有的 SaaS 生态里——查订单、改订单、退款、创工单、查物流、调电商平台数据——这些都是已经存在的系统,每个系统都有自己的 API。
数量很重要。一个典型企业客服 Agent 涉及 6 大系统。订单系统有 5-8 个 API(查 / 改 / 退款)。工单系统有 3-5 个 API。物流系统有 4-6 个 API(追踪 / 异常 / 重发)。电商平台往往不止一个,每个 4-6 个 API。财务系统 3-4 个。数据 / 风控 2-3 个。合计 25+ 个 API。直接全塞 prompt 给 LLM——token 爆炸 + 选错率 30% 起步。
写一堆 routing 规则也不行——每个意图绑死调哪个 API,意图加一个规则文件就加一片,3 个月后没人能维护。唯一站得住的路径是把 API 包装成业务能力——Tool Layer。上层暴露一个能力叫"退款",下层封装"识别归属层 → 查物流 → 调财务" 3-5 个 API。LLM 只看到"退款"这一个 tool,看不到下层 API。
一张极简契约:process_refund 接收 order_id 和 reason_code,返回 success 加上可选的 ticket_id 和 escalation_reason。内部根据归属路由到平台直营 / 品牌寄售 / 调拨路径。LLM 不知道下层有 3 条不同路径,也不需要知道。它看到的就一个 tool 加 2 个输入参数——清晰、稳定、好测。下层路径变化(接入新电商平台、调拨流程改动、财务系统升级),上层 tool 契约不动——这是 Tool Layer 真正的价值。
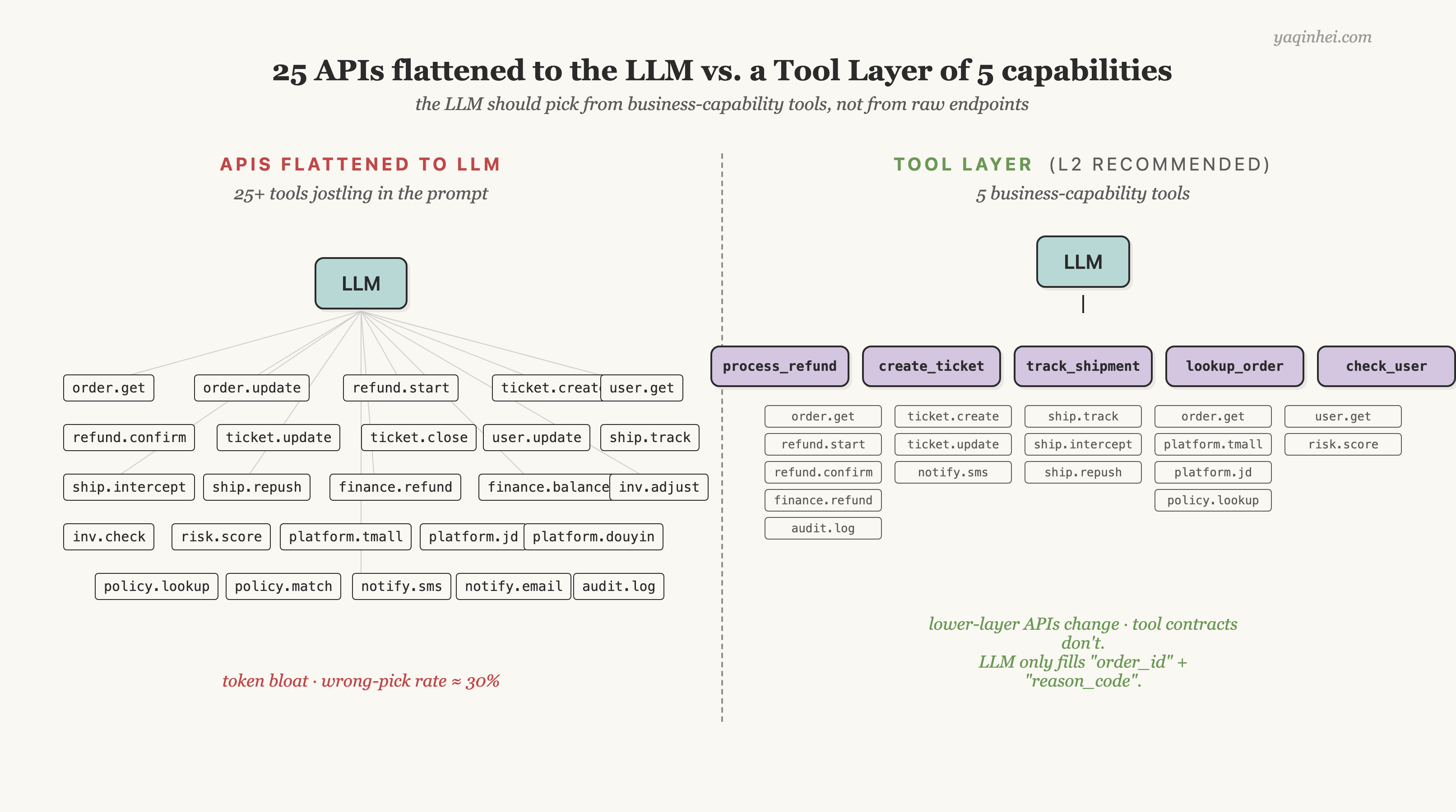
下层每条路径的实现是规则代码(不是 LLM),由后端工程师维护。LLM 只负责"在 process_refund 这个 tool 出现的时候、把 order_id 和 reason_code 填对"——这个任务它能稳定做好。
两个值得警惕的信号。供应商展示的架构图把所有 API 都画给 LLM 看——token 成本失控,意图加一个就要重新 prompt 调参,整个系统极脆。集成方案说「我们写了 50 条 routing 规则」——3 个月后规则之间会冲突,没人愿意维护,下一波团队接手会推翻重做。
Tool Layer 的具体契约设计——幂等性、错误码、超时重试、灰度发布、上下游契约对齐、25 API 怎么收敛到 8-10 个 tool——会单独写一篇深挖。
为什么接住率是个虚指标
前面 4 个决策都做对,最后一个决策做错——老板看到的依然是"花了 Agent 的钱、和原来 BOT 没区别"。
BOT 时代的指标是接住率:用户问题被机器识别 + 给了某个答案 / 走完某个流程 = 接住。常见 80-85%。Agent 时代的北极星只能是解决率:用户问题被实际解决——不需要再转人工 + 不需要二次提问 + 24h 内不回访。上线目标 60-70%。
差距巨大。因为"机器给了答案" ≠ "问题被解决"。两个真实场景。用户问「我的快递怎么还没到」,机器答「您的快递正在派送,请耐心等待」。接住了,问题没解决,用户还要转人工。用户问「我要退货」,机器答「请上传订单截图」,用户上传后机器再次答「请按 1 退货、按 2 换货」。接住了 2 次,问题还没解决,用户已经骂街了。
接住率 80% 的项目,解决率可能只有 30%——这种差距才是 BOT 和 Agent 的分界线。所有把"接住率"当 KPI 的 Agent 项目,最后老板都会困惑"做了和没做一样"。
指标体系应该是一个北极星 + 一组子指标。北极星是解决率。子指标暴露系统在哪里失败:意图分类准确率(决策 2 的产出)、政策判定准确率(决策 1 的产出)、写操作准确率(决策 3 的产出)、兜底升级率(Critic 触发率)、二次提问率(用户没拿到答案再问的比例)。子指标是给工程团队定位问题用的——解决率掉了 5%,去看子指标里哪个掉了,对应到 5 个决策里哪一个出了问题。北极星是给业务老板看效果用的——只看一个数字,看不到要问的不是子指标,是"这个 workflow 是不是没设计对"。
两个值得警惕的信号。供应商汇报「接住率 95%」——问他「解决率多少」,答不上来 = 没北极星,这种项目上线后老板会困惑。KPI 设计成「自动化率」或「机器人占比」——这是把"省人工"当目标,不是把"解决问题"当目标。两者经常南辕北辙:为了省人工,把流程做得让用户不容易转人工——结果用户更不满意,但 KPI 数字好看。
接住率到解决率的完整迁移路径——子指标怎么拆、怎么算、怎么给老板汇报、过渡期"双指标并存"怎么处理、解决率怎么和现有 BOT 数据对照看——会单独写一篇深挖。
5 决策对照表:5 分钟看清一份方案
整件事可以装进一页纸。下次评审供应商方案、内部立项 review、汇报老板,一边听一边打勾,5 分钟知道这个方案能不能上线。
| # | 决策 | 偷懒方案 | L2 推荐方案 | 不能上线方案 |
|---|---|---|---|---|
| 1 | Workflow | 全规则 / 决策树 | Deterministic + LLM 填参 | LLM 自主规划路径 |
| 2 | 意图分类 | 纯规则 | 3 级 fallback | 纯 LLM |
| 3 | 写操作兜底 | 直接执行 | Fail-closed Critic | LLM 自主执行 |
| 4 | API 集成 | 全 routing 规则 | Tool Layer 业务封装 | 全部 API 平铺给 LLM |
| 5 | 评估指标 | 接住率 | 解决率 + 子指标 | 自动化率 / 机器人占比 |
这一年我看到的,规律很稳。做对 1-2 个:整体效果差距很大,老板看不到明显改善。做对 4-5 个:能上线见效,解决率上 60%+。5 个全做错:要么把 L2 退化成 L1("加了 LLM 文案的 BOT"),要么吹成 L3 但根本上不去。Agent 落地的差距,不在模型选型上,在这 5 个决策上。
把这张表打印出来(或者保存到手机),下次评审供应商方案、内部立项 review——一边听对方介绍架构、一边在表上打勾。5 分钟,你就能给出一个明确的判断:这个方案上线后能不能跑、解决率天花板大概在哪、需不需要返工。比"看完整套 PPT 还要回去消化两周"高效一万倍。
领取这篇文章的工具包
如果你想把这篇里的 5 决策对照表立刻用到下次评审会——不用每次开会都翻这篇文章——我整理了一个 PDF 工具包给读到这里的读者。回复关键词「L2 客服 Agent」,我把工具包发给你:5 决策对照表 · 卡片版(5 张方形卡,团队群里一发就懂)、15 个红旗信号自查清单(评审供应商方案专用)、L2 vs L3 选型决策树(一页 A3 印刷版)。两年客服 Agent 项目沉淀下来的判断工具。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
这个系列接下来要写什么
A4 是这个系列的锚点文——5 个决策的每一个都值得单独深挖。
已发布的后续深挖:
- 第三篇:自动化率 70% 的 Critic 比 95% 的更值钱——fail-closed 设计深挖(决策 3 深挖)
- 第四篇:上线即放养:AI Agent 项目最贵的认知陷阱(上线之后的 6 个运维环节)
接下来的排期:AI 系统怎么测(双轨架构 + 7 质量维度,不属于 5 决策但同等重要);3 级 intent 级联调参(决策 2);LLM 接入企业 SaaS 生态(决策 4);接住率 vs 解决率深挖(决策 5)。如果你的团队正在做客服 Agent,这 3-4 篇接下来 2 周内会一篇一篇出。
如果这篇对你有用,也欢迎转给团队里需要看的人——尤其是正在评审客服 Agent 供应商方案的同事。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.