审了 28 个 AI 项目,只有 5 个是真 Agent

AI 智能体落地方法论(Agentic AI)· 第 1 篇 | 判断 AI 智能体(Agent)真假的 4 级尺子(L0–L3)
上一个系列《零售企业 Agentic AI 落地手册》讲的是"怎么把一个客服 Agent 从 0 做到 1";这个系列往上一层——讲"怎么判断什么该做成 Agent、做到什么程度"。先对齐语言,再谈落地。English version: 28 'Agent' Projects, Only 5 Are Real — The L0-L3 Grading Framework。
开篇:你的桌面上是不是也摆着这样一份清单
你的桌面上,是不是也摆着这样一份清单——
智能客服、智能补货、智能滞销预警、智能排班、智能门店、智能会员、智能内容…… 28 个候选场景,每个名字前面都加着"智能"或者"Agent"。老板说"今年要做",你不知道哪些是真的、哪些是虚的,更不知道该怎么向他汇报。
预算、人手、KPI,都在等这份清单批下来。
如果这个场景对你不陌生,往下看——下面这些号称 AI Agent 的项目,可能就在你的清单里:
- 智能会议纪要? 流程固定:录音 → 转写 → LLM 总结 → 推送参会人。LLM 只在"总结"那一步出力。
- 陈列合规检测? 本质是计算机视觉识别,根本不需要 LLM。
- 售后客服? 要查订单、查物流、判政策、决定退款还是转人工——LLM 在多个节点做决策。
把整张清单 28 个场景过完,真正需要做成 Agent 的只有 5 个,19 个根本用不到 LLM 做自主决策,4 个介于中间。
如果你按原样把这份清单批下去,70% 的预算会投在"加了 LLM 的自动化"上——但所有人都按 Agent 汇报、按 Agent 设 KPI、按 Agent 期望评估效果。等到交付那天,全员困惑:投了这么多钱,怎么和原来的 BOT 没什么区别?
这不是 LLM 不行,也不是团队不行。是所有人嘴里的"Agent",指的根本不是同一个东西。
这篇文章给你一把 4 级分级尺子——读完之后,你能在 5 分钟内对任何一个 AI 项目判断:它到底是 Agent,还是别的东西。然后再用 20 分钟,把你手头的 28 个候选场景全部分类清楚。
一、为什么 "Agent" 这个词正在害死项目
开篇说"所有人嘴里的 Agent 不是同一个东西"——具体怎么不同?
| 角色 | 嘴里的 "Agent" 是什么 |
|---|---|
| 销售 / 解决方案商 | 任何卖了 LLM 能力的东西,从问答到多模态助手都叫 Agent |
| 业务老板 | "比 BOT 更聪明"的东西,能解决问题、能自动跑业务 |
| 工程师 | 严格意义上:能自主规划、调工具、循环执行的 LLM 系统 |
| 媒体 / 公众号 | 凡是 LLM + 业务场景的组合,都能写成"XX Agent" |
四类人各自说"Agent",每方都觉得自己说得清楚。直到他们坐到同一张会议桌上——
老板说"我们今年要做 Agent",销售拿出"Agent 解决方案"报价,工程师听完心想"这不就是意图分类 + RAG 吗",真正交付时业务方发现"和原来 BOT 没区别"。
每一方都在浪费钱,每一方都不知道是怎么浪费的。
这一年里我看到的翻车,形态各异,根因相同——没有共同的语言来描述自己究竟在做什么。下面三类最常见。
翻车 1:把模板引擎包装成 Agent 卖
我见过一个零售品牌,买了套"会员运营 Agent",号称能自主决定对哪些会员、在什么时点、发什么内容。上线半年复盘——"决定对哪些会员发"是规则引擎在跑,"什么时点发"是触发器在跑,LLM 真正出力的只是"把模板短信换成更口语化的个性化文案"。
这是一个标准的 L1 系统——LLM 嵌入固定流程的一个节点。但它被当作 L2 Agent 卖,付了 Agent 的价钱,挂了 Agent 的 KPI("自主决策""智能触达"),最后效果差距不是和"没用 LLM"比,而是和"自主 Agent 应有的解决率"比。
钱花了,没人买账。
翻车 2:该 L2 的场景,做成了 L1
另一类项目走的是反方向。某团队做售后客服——这本来是个 L2 场景,LLM 需要在意图判断、查订单、判政策、决定路径几个节点都做决策。但团队为了"保证可控性",把所有 LLM 决策都换成了规则:意图用规则匹配,查哪个 API 用决策树,退款条件用 if-else,LLM 只负责生成最终回复话术。
结果解决率卡在 30% 上不去(行业基线 60%-70%)。每加一个新场景都要写一堆规则,规则之间还冲突。半年后团队意识到:他们花了 Agent 的钱,做了一个加了 LLM 文案的 BOT。
明明可以让 LLM 自主决策的场景,用"可控"做借口,把它退化成了 L1——这种翻车比前一类更隐蔽,因为表面"项目交付了"。
翻车 3:业务方追 L3 多 Agent,工程根本 hold 不住
第三种翻车最常见于"PPT 项目"。某次评审会,业务方给我看一份方案:5 个子 Agent(销售、库存、客户、运营、CEO)互相对话、互相决策、互相反思,最后输出一份"战略建议报告"。
我问:哪个 Agent 听哪个 Agent 的?冲突怎么仲裁?某个 Agent 输出错了,下游怎么知道?token 成本一次评估多少?
业务方答不上来。他看到的是 demo 视频里的"Agent 协作",没看到底下的工程复杂度。
L3 多 Agent 编排在 2026 年比单 Agent 明显更难稳定交付。框架层面工具已经成熟(AutoGen、CrewAI、LangGraph 都给了 loop 原语),但跨 Agent 的状态管理、错误传播、成本控制、可观测性,依然比单 Agent 难一个量级——这就是为什么愿意为它买单的企业很多,但能跑到 production 级别的团队极少。不是 LLM 能力问题,是工程治理问题。
三类翻车,一个根因
这三类翻车的根因,都不是 LLM 不行,也不是团队不行。是大家在用同一个词"Agent",说着完全不同的事。
销售说的 Agent 是 L1,业务老板要的 Agent 是 L2,工程师能稳定交付的是 L1-L2,业务方想象的 Agent 是 L3——四方对不上,预算就翻车。
要让这件事不再发生,第一步是建立共同的语言。下面给出第一版——四个级别、一个判断标准,让四方坐到同一张桌上时,嘴里的 Agent 真的是同一件事。
二、AI 智能体分级框架(L0-L3):判断真假 Agent 的 4 级共同语言
要解决"四方对不上"的问题,需要的不是更花哨的定义,而是一把能立刻拿来用的尺子:一眼能判断、各方都能对齐、不依赖技术背景。这把尺子按 AI 智能体(Agent)的自主决策程度 来分级——业界也叫"自主程度等级"或"成熟度模型",本文给的是更落地的中文版。
我把它分成四级。先说一个关键认知:四级看似线性,最大的鸿沟在 L1 和 L2 之间。 这是"加了 LLM 的自动化"和真 Agent 的分界线,所有"假 Agent"翻车都是没看清它。
| 级别 | 名称 | 核心特征 | 通俗理解 |
|---|---|---|---|
| L0 | 规则自动化 | if-then 决策树,固定分支,无 LLM | "按剧本演的客服机器人" |
| L1 | LLM 增强 | LLM 做内容生成 / 理解,但流程固定,不自主决策 | "聪明了的模板引擎" |
| L2 | 工具调用型 Agent | LLM 判断该调哪个工具、何时调、怎么用结果,有自主决策 | "能查系统、做判断的数字员工" |
| L3 | 多步编排型 Agent | 多 Agent 协作,有规划→执行→反思循环,处理开放任务 | "能独立完成复杂项目的数字团队" |
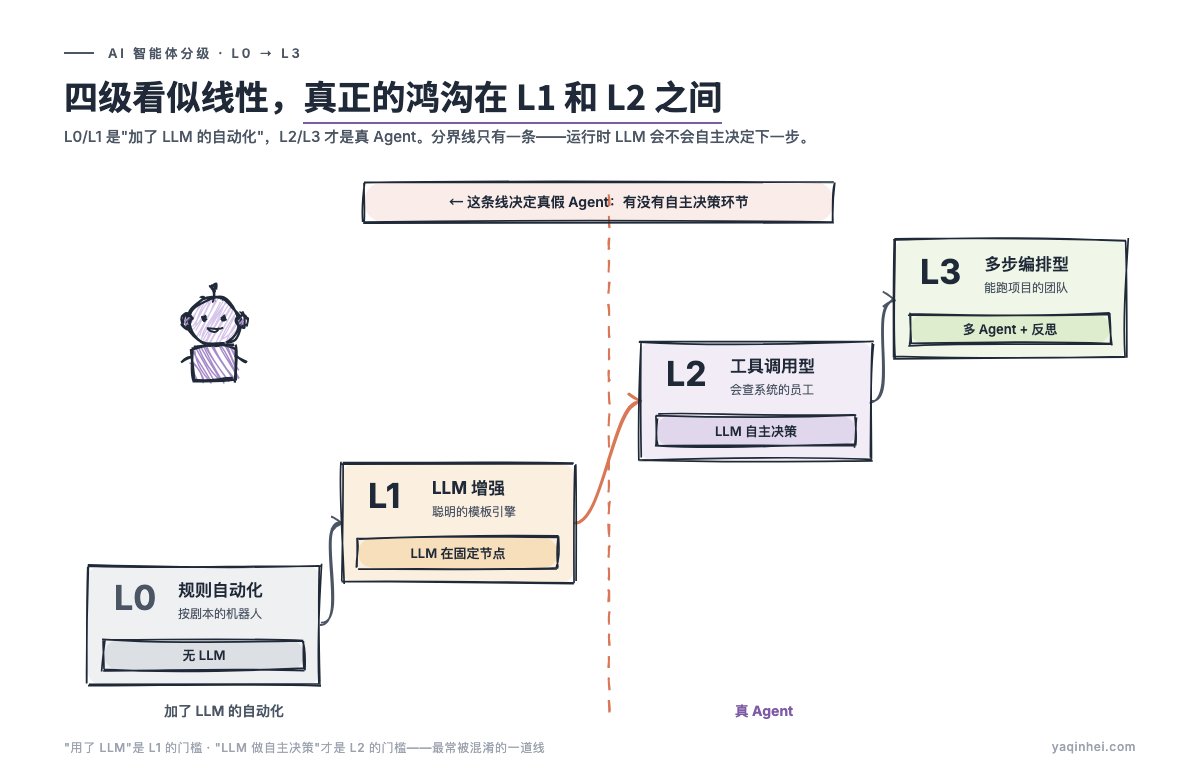
唯一判断标准:有没有自主决策环节
判断一个系统在哪一级,只需要回答一个问题——
运行时,LLM 是否根据上下文动态选择下一步行动?
- 答"否":流程是预设的,LLM 不出现或只在固定节点工作 → L0(无 LLM)或 L1(有 LLM)
- 答"是,一个节点":LLM 在一个关键节点做决策("该不该转人工")→ L2 入门
- 答"是,多个节点":LLM 在多个节点都做决策("先查什么、查到的怎么用、下一步去哪")→ 典型 L2
- 答"是,而且决策之间有反思循环":LLM 自己评估上一步对不对、要不要重做 → L3
"用了 LLM"和"LLM 做自主决策"是两件事。前者是 L1 的门槛,后者是 L2 的门槛。这是最常被混淆的一道线。
三个对照例子
光说定义还是抽象。把三个场景拆给你看——形态差异一目了然。
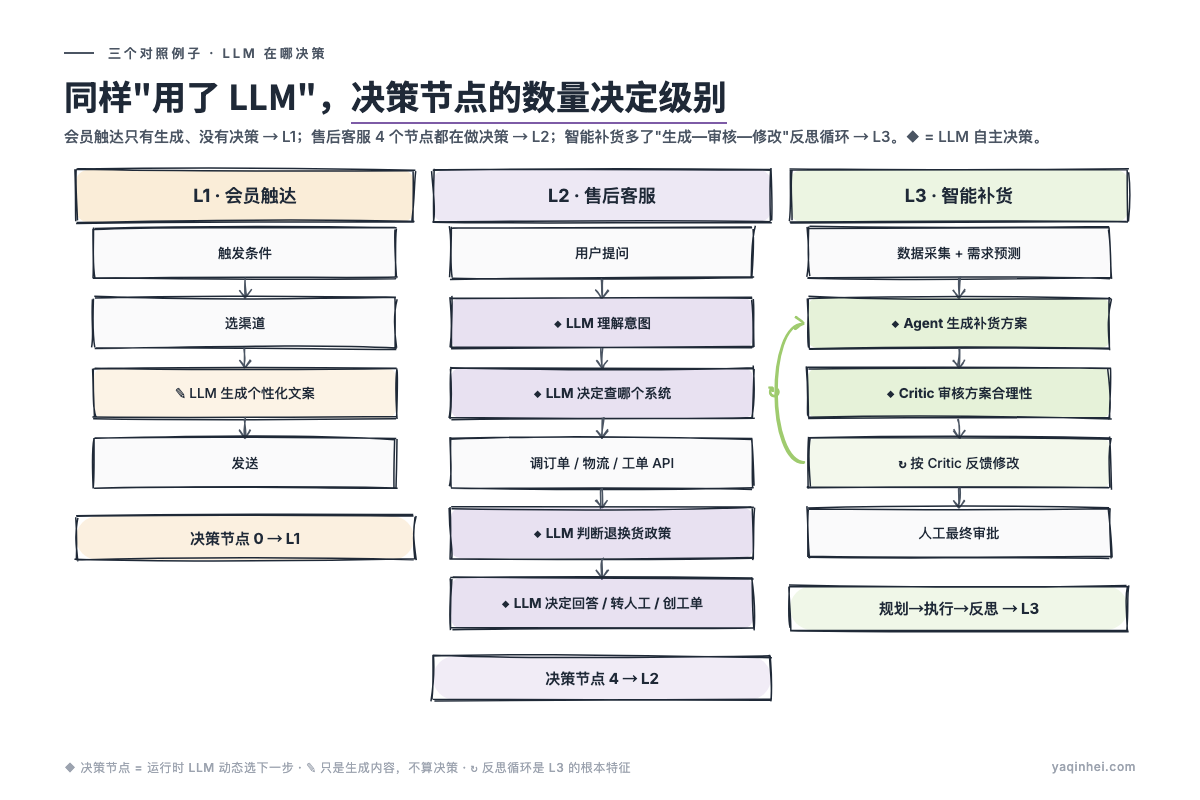
例子 A:会员触达(L1)
为什么是 L1:LLM 只在"生成文案"这一个节点出力,整个流程是预设的,没有"LLM 决定下一步去哪"的环节。
触发条件 → 选渠道 → [LLM 生成个性化文案] → 发送
↑ 流程全是预设的,LLM 只在"生成文案"这个节点出力
↑ 典型 L1
LLM 让短信变得更口语化、更个性化,体感是"有 AI 的味道"——但本质是模板引擎。把 LLM 换成一个调好的模板引擎 + 一个意图分类器,系统架构是同型的——L1,无论生成的内容多漂亮。这就是 L1 的边界。我自己做的公众号自动化工具就是个典型 L1:LLM 负责选题和初稿,但 14 阶段 pipeline 的流程是写死的,没有"LLM 决定下一步去哪"的环节——够用,但别误当成 Agent。
例子 B:售后客服(L2)
为什么是 L2:LLM 在 4 个节点做自主决策(理解意图 → 决定查哪个系统 → 判断政策 → 决定回答/转人工/创工单),流程不是预设的,每次对话路径都不一样。
用户提问 → [LLM 理解意图] → [LLM 决定查哪个系统]
→ 调订单 API / 物流 API / 工单 API
→ [LLM 判断是否符合退换货政策]
→ [LLM 决定: 直接回答 / 转人工 / 创建工单]
↑ LLM 在 4 个节点做自主决策
↑ 典型 L2
这才是 Agent。LLM 不是"加在某一步",而是串联整个流程的大脑。每一次对话的执行路径都不一样,但都收敛到同一个目标(解决用户问题)。
例子 C:智能补货(L3)
为什么是 L3:不是因为"用了多个 Agent",而是因为有规划→执行→反思的循环——Agent 生成方案、Critic Agent 审核、根据审核反馈再修改,多轮迭代直到收敛。
(Critic Agent 是后面会多次出现的概念,先给个定义:用另一个 LLM 专门审核第一个 LLM 输出是否合理。比如第一个 Agent 提出"门店 A 补 100 件 T 恤",Critic 检查这个方案是否符合库存上限、品牌授权、季节性等约束,不合理就打回去重做。本质是"AI 互相校稿"——避免单个 LLM 自说自话出错。)
数据采集 → [需求预测模型]
→ [Agent 生成补货方案]
→ [Critic Agent 审核方案合理性]
→ [Agent 根据 Critic 反馈修改方案]
→ 多轮迭代直到收敛
→ 人工最终审批
↑ 多个 Agent 角色 + 反思循环
↑ 处理开放任务("这周该补什么货"没有标准答案)
↑ 典型 L3
L3 的关键不是"用了更多 Agent",是反思循环:系统自己评估输出对不对,不对就重做。这是 L3 区别于 L2 的根本特征。
智能补货是这两年零售业 AI 的最大痛点之一,几乎每家头部品牌都在试,但能稳定落到 L3 的极少。原因和上一节翻车 3 一样:愿意为多 Agent 协作买单的客户很多,能把工程复杂度 hold 住的团队极少。
这套尺子怎么用
回到开篇的场景:当老板问"我们做的是 Agent 吗?",你不用辩论。给他这张表,让他看 3 个对照例子,他自己就能判断。
更进一步:你可以把手头每个候选场景,逐一对到表里。一个下午,你会得到一份比 PPT 战略更有用的清单——这 28 个场景里,哪些是 L0,哪些是 L1,哪些才值得花 Agent 的钱去做 L2 / L3。
如果"对到表里"听上去还是抽象,下面这份 5 问题清单把它压到每个项目 3 分钟。
三、5 分钟自查清单:你的项目到底在哪一级
把上一节的判断方法拆成 5 个问题,每个 30 秒能答。全部答完,你就知道这个项目是 L 几——以及供应商有没有在忽悠你。
这一节是给你截图发到群里、转给老板看的。
Q1. 你的流程里,LLM 有几个决策节点?
数一下:用户输入进来后,LLM 在哪些步骤上"判断该去哪一步"——不是生成内容、不是给答案,是决定下一步的方向。
→ 0 个:L0 / L1 | 1 个:L2 入门 | 多个:典型 L2 | 多个 + 反思循环:L3
🚩 红旗信号:供应商说"我们的 Agent 智能选择最优路径"——问他具体在哪几个节点。讲不出节点名字的,多半是 L1 包装。
Q2. 如果 LLM 输出错了,会造成不可逆后果吗?
L2 / L3 真 Agent 的标志之一,是它的输出会触发副作用——发退款、改订单、创工单、扣库存。
→ 没副作用、只是回答内容:L1 / L2 问答型 | 有副作用 + 规则二次校验:L1 / L2 | 有副作用 + LLM 自己决定执行:L2,必须配 Critic 兜底 | 能根据后果调整后续动作:L3
🚩 红旗信号:"我们 Agent 已经完全替代人工"——但凡涉及钱、库存、客户承诺的写操作,没人工兜底 / Critic 校验的"完全替代"都是高风险。
Q3. 运行时的流程分支,是预设的还是 LLM 临时决定的?
打开项目代码(或问工程师):
→ 流程图写死,LLM 只在某个 box 里出力:L0 / L1 | 有几条主分支,LLM 决定走哪条:L2 入门 | 没有静态流程图,LLM 根据上下文动态构建路径:典型 L2 / L3
🚩 红旗信号:供应商展示的架构图里,所有节点都画得整整齐齐用箭头连好——大概率是 L1。真 Agent 的架构图是工具列表 + 上下文 + LLM 路由,没有静态流程图。
Q4. 是否需要跨多个外部系统取数 + 综合判断?
L2 真 Agent 的核心能力:LLM 决定调哪个系统、调几次、怎么把结果拼起来回答。
→ 不需查外部系统:L0 / L1 | 查 1 个系统 + 规则路由:L1 | 查多个系统 + LLM 决定怎么用:L2 | 跨系统取数 + 跨 Agent 协作 + 反思:L3
🚩 红旗信号:"我们 Agent 接入了 50 个系统"——问他 LLM 怎么知道该调哪个。答"我们写了路由规则"的,LLM 没在做决策,是 L1。
Q5. 有没有"规划 → 执行 → 反思"循环?
L3 的根本特征:
→ 输出一次就结束:L0 / L1 / L2 | 输出后有另一个 Agent 评估、决定要不要重做:L3 入门 | 多角色协作"生成—审核—修改":典型 L3
🚩 红旗信号:"我们用了 5 个 Agent"——问他,这 5 个 Agent 之间怎么协作?谁听谁的?冲突怎么仲裁?答不上来就是营销话术,不是工程方案。
自查总结表
| Q1 决策节点 | Q2 副作用 | Q3 流程动态性 | Q4 跨系统取数 | Q5 反思循环 | 结论 |
|---|---|---|---|---|---|
| 0 | 无 | 预设 | 无 | 无 | L0 / L1 |
| 1 | 有 | 部分动态 | 单系统 | 无 | L2 入门 |
| 多 | 有 | 动态 | 跨系统 | 无 | 典型 L2 |
| 多 | 有 | 动态 | 跨系统 | 有 | L3 |
这张表配上 5 个问题,5 分钟把任何一个 AI 项目定位清楚。
光看尺子还是抽象,下面把它套到真实清单上。剧透结果:真 Agent(L2-L3)只有 5 个,LLM 增强自动化(L0-L1)有 19 个,4 个介于中间。也就是说,70% 的"Agent 候选"根本不需要花 Agent 的钱。 把这个数字记在脑子里,下面看具体是哪些。
四、用尺子盘 28 个候选场景:真 Agent 究竟有几个
把这把尺子套到具体场景上看看。
下面是 28 个最常见的零售 / 消费行业 AI 候选场景,按业务层划分。每一个我都用上一节的 5 个问题过了一遍,结果可能会颠覆你对"AI 项目"的认知。
这里的命名都是零售业通用术语。如果你不在零售业,把"门店导购"想成"销售人员"、"补货"想成"库存周转",逻辑通用。
顾客旅程层(5 个候选场景)
直面客户的环节,AI 滥用最严重的重灾区。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 1 | 售后客服 | L2 ✅ | 多轮对话 + 跨系统查数 + LLM 决定回答/转人工/创工单——4 个决策节点 |
| 2 | 线上导购副驾 | L1-L2 ⚠️ | RAG 检索产品知识 + 推荐搭配,主要辅助导购而非替代 |
| 3 | 门店导购副驾 | L1 ❌ | 扫码查产品知识卡,本质 RAG 查询 |
| 4 | 会员运营 | L1 ❌ | 规则触发 + 模板短信,LLM 只生成文案 |
| 5 | 个性化推荐 | L0-L1 ❌ | 推荐算法核心 + LLM 解释推荐理由 |
这一层 5 个里,真 Agent 只有 1 个(售后客服)。其他 4 个都是"加了 LLM 的现有系统"——大多数公司把会员运营也叫"会员 Agent",但它根本不需要 LLM 做决策。
供应链层(5 个候选场景)
业务老板最痛的环节,也是 L3 真 Agent 的少数候选地。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 6 | 智能补货调货 | L3 ✅ | 需求预测 + Agent 生成方案 + Critic 审核 + 反思迭代 |
| 7 | 滞销预警 | L1 ❌ | 规则 / 模型识别库龄异常 + LLM 生成预警简报,流程固定 |
| 8 | 物流异常追踪 | L0-L1 ❌ | 对接物流 API + 规则判断延误 + 通知,事件驱动自动化 |
| 9 | 新品铺货 | L1-L2 ⚠️ | 门店画像匹配 + 预测模型 + 生成分货方案,主要靠算法 |
| 10 | 供应商协作 | L1 ❌ | 数据汇总 + LLM 生成品牌销售报告 |
这一层 5 个里,真 Agent 也只有 1 个(智能补货)。剩下的"智能滞销预警""智能物流",名字唬人,本质是规则 + LLM 文案。
门店运营层(5 个候选场景)
最容易被"自动化"忽悠的环节——5 个里 3 个根本不需要 LLM。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 11 | 排班优化 | L1 ❌ | 历史流量预测 + 生成排班建议,优化算法主导 |
| 12 | 门店 KPI 辅导 | L1 ❌ | 数据聚合 + LLM 生成经营分析解读 |
| 13 | 陈列合规检测 | L0 ❌ | 计算机视觉识别陈列规范,CV 任务 |
| 14 | 库存盘点 | L0 ❌ | RFID 数据 + 异常检测算法,IoT |
| 15 | 设备维保 | L0 ❌ | 传感器数据 + 预测性维护模型 |
这一层没有一个真 Agent。供应商如果给你卖"门店运营 Agent",先看是哪个场景——大概率是 CV 或 IoT 系统加了 LLM 文案壳子。
人才发展层(4 个候选场景)
唯一一个"非业务核心但有真 Agent"的层。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 16 | 员工培训 | L2 ✅ | LLM 扮演客户角色,多轮对话模拟训练,动态出题 |
| 17 | 招聘筛选 | L1 ❌ | 简历解析 + 规则匹配 + LLM 评分 |
| 18 | 绩效反馈 | L1 ❌ | 数据聚合 + LLM 生成个性化绩效报告 |
| 19 | 员工关怀 | L0-L1 ❌ | 文本分析员工情绪趋势,NLP 分析 |
员工培训是个有趣的 L2——LLM 扮演客户和员工对话,根据员工回答动态调整难度和场景。这种"角色扮演 + 动态出题"是少数适合 L2 的非核心业务场景。
营销增长层(5 个候选场景)
LLM 内容生成的主场,也是 L1 的舒适区。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 20 | 活动策划 | L1 ❌ | 历史 ROI 分析 + LLM 生成方案草稿,人做决策 |
| 21 | 内容生成 | L1 ❌ | LLM 批量生成产品文案 / 朋友圈内容 |
| 22 | 竞品监控 | L0-L1 ❌ | 爬虫采集 + 规则告警 + LLM 生成简报 |
| 23 | 数据分析(Text-to-SQL) | L2 ⚠️ | LLM 决定生成什么 SQL,调数据库工具,解读结果 |
| 24 | 品牌合规 | L1 ❌ | 规则 + LLM 检测营销素材是否合规 |
注意一个反直觉点:内容生成虽然全程是 LLM,但不是 Agent——因为没有自主决策环节,只是 LLM 当文案机。
财务风控层(4 个候选场景)
写操作密集,也是 Critic 兜底最重要的层。
| # | 场景 | 级别 | 一句话理由 |
|---|---|---|---|
| 25 | 退货欺诈检测 | L2 ✅ | 多维度异常检测 + 关联分析 + LLM 判断是否标记 / 拦截 |
| 26 | 价格优化 | L0-L1 ❌ | 优化算法在品牌授权区间内搜索最优价 |
| 27 | 财务预测 | L1 ❌ | 时序预测模型 + LLM 生成解读 |
| 28 | 合规审查 | L1-L2 ⚠️ | LLM 阅读合同 + 检查规则库,流程线性 |
这一层 4 个里 1 个真 Agent(退货欺诈检测)。这是必须配 Critic 兜底的 L2——标记和拦截都是写操作,错了会得罪客户。
28 场景汇总
把 28 个场景按级别重新归类:
| 类型 | 数量 | 占比 | 代表场景 |
|---|---|---|---|
| ✅ 真 Agent(L2-L3,有自主决策) | 5 | 18% | 售后客服、智能补货、员工培训、Text-to-SQL、退货欺诈 |
| ⚠️ 部分 Agent(L1-L2 边界) | 4 | 14% | 线上导购副驾、新品铺货、合规审查、数据分析 |
| ❌ LLM 增强自动化(L0-L1) | 19 | 68% | 其余全部 |

最关键的结论:
- 真正需要"花 Agent 的钱去做 Agent"的,只有 5 个。剩下 19 个根本不需要 LLM 自主决策——做成 L1 自动化即可,预算量级和 Agent 差一个数量级。
- 5 个真 Agent 集中在三类场景:客户直接交互(售后客服)、跨系统决策(补货 / 欺诈 / Text-to-SQL)、动态对话(员工培训)。其他场景被叫"Agent",多半是营销话术。
- L0 完全不需要 LLM 的场景,依然占 3 个(陈列合规 / 盘点 / 维保)——CV 和 IoT 不要硬塞 LLM。
一个建议:给项目名字"减肥"
把 28 个场景按级别重新命名一遍,整个项目组合的复杂度和投入预算就会清晰起来:
| 真实级别 | 推荐命名 | 例子 |
|---|---|---|
| L2 / L3 | "XX Agent" | 售后客服 Agent、智能补货 Agent |
| L1 | "AI XX 助手" 或 "智能 XX 系统" | AI 文案助手、智能排班系统 |
| L0 | "XX 自动化" | 陈列合规自动化、库存盘点自动化 |
下次有人给你提"我们要做 28 个 Agent 项目",让他先按这套命名重写一遍。改完名字,预算会自动收敛——Agent 和"助手"完全不是一个量级的事。
不同角色用这把尺子姿势不一样——决策者在评审会上、售前向客户解释、工程师顶住业务方加码。下面按三类读者拆开讲。
五、给三类读者的行动指南
尺子有了,结论也有了。三类读者,三种典型场景——下面分别给一份能直接拿去用的话术。
给决策者:评估供应商 / 内部立项的 3 个尽调问题
听完任何"Agent 方案"汇报后,问这 3 个——任何一个答不上来,方案就要重写。
Q1: 用 L0-L3 框架量,这是 L 几? 让对方当场对着 4 级表给一个明确答案。答"我们超越了分级"或"综合多级"——红旗,他在回避定级。
Q2: 我们花的是 L 几的钱? L0 / L1 项目和 L2 / L3 项目,预算量级差一个数量级。L1 报 L2 价,你被宰;真 L2 报 L1 预算,团队会偷工减料做成 L1。
Q3: 交付后按 L 几评估效果? L0 / L1 看"自动化率""文案点击率",L2 看"任务解决率""跨系统准确率",L3 看"方案接受率""反思收敛速度"。指标和级别错配 = 各方扯皮——交付方说达标,业务方说体感差。这种 misalignment 一旦扔进 RL 训练的 Agent,就是经典的 reward hacking 陷阱——Agent 学会刷你优化的那个指标,而不是你真正要的目标。
这 3 个问题一问,30 分钟里就能看穿一个 PPT 项目。
给售前 / 解决方案 PM:向客户解释产品差异的话术模板
客户两个常见问题,用 L0-L3 框架回答比任何营销话术都管用:
"你们和 XX 有什么区别?"
"他们的方案是 L1——LLM 嵌在固定流程里做内容生成。我们是 L2——LLM 在多个节点自主决策。差别不是参数大小或模型版本,是 LLM 在系统里的角色。可以现场拆给您看:他们的架构图里 LLM 在一个 box 里,我们的 LLM 串联整个流程。"
"我们已经有 BOT 了,为什么还要做 Agent?"
"您现有 BOT 是 L0——按规则树跑。'接住率'可能很高(80%+),但'解决率'未知——因为它不会答的问题就转人工,从不真正解决。Agent 是 L2——LLM 决定查哪个系统、判断政策、决定回答还是转人工。差别不是哪个聪明,是从'接住'到'解决'的跨越。"
记住一个核心句式——"我们是 L X,他们 / 你们现有的是 L Y,相差的不是技术好坏,是 LLM 在系统里的角色"。客户听完会自己得出结论,不需要你反复推销。
给工程团队:反驳"这个场景不需要 Agent 化"的沟通技巧
业务老板说"全部做成 Agent",工程最难的不是技术,是怎么说服老板"这个场景做成 L1 就够了"。
直接说"不需要 Agent" → 老板会怀疑你技术保守 / 推卸工作。换成三步:
1. 用老板熟悉的语言重新描述场景
"老板,'会员智能触达'按 L0-L3 框架是 L1——LLM 在'生成文案'一个节点出力,其他都是规则跑。"
2. 明确做成 L2 的成本和风险
"做成 L2 要让 LLM 决定'什么时点发、给谁、走什么渠道'——开发量是 L1 的 3-5 倍,每次失败案例都要复盘。效果能比 L1 好多少?我们没证据。"
3. 给一个老板能接受的折中
"建议先做 L1,3 个月上线见效果。效果到瓶颈再升级 L2——那时候有数据支撑判断'升级值不值',不是凭感觉。"
核心是别让老板感到"你在拒绝他的方向",而是"你给了他一个更稳的路径"。L0-L3 框架在这里的价值,是把模糊的工程判断翻译成商业语言:老板听得懂"3 倍开发量"和"效果证据",但听不懂"工具调用框架"。
六、结语:选对级别,比追求高级别更重要
回到开篇那个场景。
老板拍板"今年我们要做 Agent",团队报上 28 个候选场景。如果你已经读到这里,你会知道:真正需要做成 Agent 的,只有 5 个。
但这不是坏消息。
坏消息只属于那些把 L1 当 L2 卖、把 L0 当 L2 做、把 PPT 上的 L3 当真能交付的人。对真正想用 AI 解决业务问题的团队,分级框架让 70% 的投入回到正确的地方——L1 自动化有 L1 的价值,只是它不该花 Agent 的预算、挂 Agent 的 KPI、被叫 Agent 的名字。
Agent 不是终点,是工具。选对级别,比追求高级别更重要。
一个行动:先把你手头的项目过一遍
如果你读到这里,先做一件事:回到第三节,用 5 个问题把你手头正在做的(或正在评估的)AI 项目过一遍。它到底是 L 几?
20 分钟,你会得到一份比 PPT 战略更有用的清单。下次开会用它做沟通基础,比任何"AI 转型路线图"都管用。
领取这篇文章的工具包
如果你想把这篇里的工具立刻用到自己的项目上——不用每次开会都翻这篇文章——我整理了一个 PDF 工具包给读到这里的读者:
📥 回复关键词「Agent 分级」,我把工具包发给你:
- 28 场景分级判断表(一页 A3 印刷版,你的项目组合 30 秒看清)
- 5 问题自查清单 · 卡片版(6 张方形卡,团队群里一发就懂)
- L0-L3 框架高清图(汇报 PPT 可直接用,已配通俗解释列)
这是我做客服 Agent 项目两年沉淀下来的判断工具。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
这个系列接下来要写什么
这是《Agentic AI 落地方法论》系列的第一篇。L0-L3 框架解决的是对齐语言、看清现状的问题——但 5 个真 Agent 具体怎么做?这才是大部分团队卡住的地方。
下一篇要写的是:L2 真 Agent 在客服场景到底怎么做?
核心问题包括:
- 为什么 L2 客服 Agent 不能用 L3 autonomous planning?金融操作的 deterministic safety 要求是什么?
- 三级 intent fallback(规则 → embedding → LLM)的成本-效果三角怎么调?
- 写操作(退款 / 改单 / 创工单)的 Fail-closed LLM Critic 设计——为什么 timeout / error 必须升级到人工而不是放行?
- 25 个 API 集成(订单 / 工单 / 物流 / 电商等 6 大系统)的契约设计
- 从 80% "接住率" 到 65% "解决率" 的评估体系怎么搭——给业务老板看的指标长什么样?
如果你的团队正在做客服 Agent,下一篇会比本篇更细、更深、更有工程价值。
系列后续已发布:
- 第二篇:5 个架构决策,决定你的客服 Agent 能不能上线
- 第三篇:自动化率 70% 的 Critic 比 95% 的更值钱——fail-closed 设计深挖
- 第四篇:上线即放养:AI Agent 项目最贵的认知陷阱
如果这篇对你有用,也欢迎转给团队里需要看的人——尤其是被"28 个 Agent 候选项目"折磨过的同事。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.