AI 起草的 25 页方案里 11 条事实是编的——第二个 Agent 当审稿人的 3 阶段卡口|Agentic AI 落地方法论(十一)

《Agentic AI 落地方法论》系列第十一篇。 前 10 篇拆「方案能不能上线 + 上线后怎么不放养 + 北极星指标 + 脑手分离 + 怎么测 + 阈值怎么调 + API 怎么分层 + codebook 怎么演进」——L0-L3 定级、L2 vs L3 的 5 个架构决策、Critic fail-closed、上线即放养、接住率 vs 解决率、Skills vs 知识库、双轨测试、3 级 intent 级联、五层 API 架构、Intent codebook 演进。这一篇拆输出侧——LLM 起草的事实密集型材料(方案 / 报告 / 邮件 / 文档 / 代码注释)怎么从「不可信」变成「可签字」。底线方法只有一个:第二个 Agent 当审稿人,结构性强制卡口,不靠让 LLM 自我反省。 English version: A Second Agent as Reviewer — 11 of 34 Facts in a 25-Page AI Plan Were Fabricated.
25 页方案里编了 11 条事实——这是基线,不是这家乙方的问题
上个月帮一个客户团队评审乙方交付的 25 页 Agent 落地方案。术语精准、配图清晰、参考文献整齐——典型的 AI 起草 + 项目经理 polish。
我让另一个独立 Claude session 跑了一遍 fact-check,拿方案里的所有事实声明对客户内部代码库 + 公开 doc 做交叉验证:
- 34 处事实声明(API path / 错误码 / SDK 版本 / SLA 数字 / 第三方依赖名)
- 11 处错:3 个 API path 在客户实际后端里不存在、2 个 SLA 数字凭空写的、4 个错误码大小写和 schema 对不上(schema 是小写
critical,方案里写"Critical")、1 个 SDK 版本是去年 deprecated 的、1 个第三方依赖名字拼错
11 / 34 ≈ 32% 错误率。这个数字不是这家乙方差——是 AI 起草事实密集型材料的工业基线。我自己用 Claude 起草博客(包括你正在读这篇)的第一稿事实错误率也在 20-30%。再换一家 vendor,结果一样。
更糟的是,这 11 处错没有一处会被「让同一个 LLM 再读一遍」抓出来。机制层面就抓不出来:
- 错误码大小写——LLM 自检时不会去 grep 真实 schema,只觉得「看起来像 enum」就过
- API path 不存在——LLM 自检时不会去 curl,只觉得「符合 REST 命名规范」就过
- SDK 版本退役——LLM 训练数据截止那天那个版本就是当时最新的,自检也是同一个 cutoff,根本没新数据可比对
「让 LLM double-check 自己的输出」是企业 AI 落地里最普遍的伪验证。乙方说「我们已经做了 AI 审稿」,要追问一句「审稿的是不是另一个独立 agent」——绝大多数时候不是。
这一篇拆三件事。
第一,为什么单 Agent 自检永远漏——confirmation bias 不是品味问题,是同一个 context window 同时起草+审稿的物理限制。
第二,结构性卡口怎么搭——DRAFT → VERIFY → FINALIZE 3 阶段,每一阶段什么不能做、什么必须做。
第三,反复踩坑的 7 类事实错误(R1-R7)——每一类给出 verification method,直接抄进 PR checklist 或评审表。
下次审 AI 写的合同 / 方案 / 招生材料 / 内部规则解读时,每一条事实声明都应该能溯到一个 file:line 或 URL,溯不到的不能进最终版。
让 LLM 自己 fact-check 自己,物理上行不通
先把结论摆桌面上:起草的 agent 不能自检。 不是它「不够仔细」——是同一个 context window 里同时持有「起草目标 + 已经生成的事实」会触发 confirmation bias。LLM 自检时倾向于「证实」自己刚才写的,而不是「证伪」。
举个具体例子。让 Claude 起草「申请 Stanford EE PhD 的招生联系 email」,第一稿生成:
Dear admissions@cs.stanford.edu,
...
让同一个 session 再 review 一遍「检查邮箱地址和系名」,10 次里 8 次会回「邮箱看起来正确,stanford.edu 是合规域名」——because LLM 在已经写下 admissions@cs.stanford.edu 之后,自检时的优先级是「检查这个邮箱是否合理」,而不是「检查这个邮箱是否真实存在」。
但 Stanford EE 的招生邮箱实际是部门级 phd-admissions@ee.stanford.edu(不是学校级 cs.),并且申请门户的 source-of-truth 是 GradAdmit portal,根本不应该发邮件给那个邮箱。
这个错误必须由一个不知道 draft 内容的、独立的 subagent 用 WebFetch 拿 Stanford EE 官网核对,才能抓到。
3 个物理原因,叠加在一起决定了「LLM 自检」永远漏:
- Context contamination——main agent 的 context 里已经有 draft,无论它怎么「装作不知道」,prompt token 都在影响 attention 分布
- Same training cutoff——main agent 知识截止那天的数据是错的,自检时它仍然用同一份错数据
- Optimizer 是一致性,不是真实性——LLM 自回归生成时优化的是「下一个 token 在 context 里的概率」,不是「这个事实在现实里是否对得上」
这 3 个原因决定了:LLM 自检拿到的是「文风通顺度 + 内部一致性」反馈,不是「事实真伪」反馈。起草侧 fact-check 永远抓不到自己编造的事实——这件事不需要 benchmark 证明,是机制层面的。
底线方法只有一个:起草和验证必须是物理上不同的 agent。
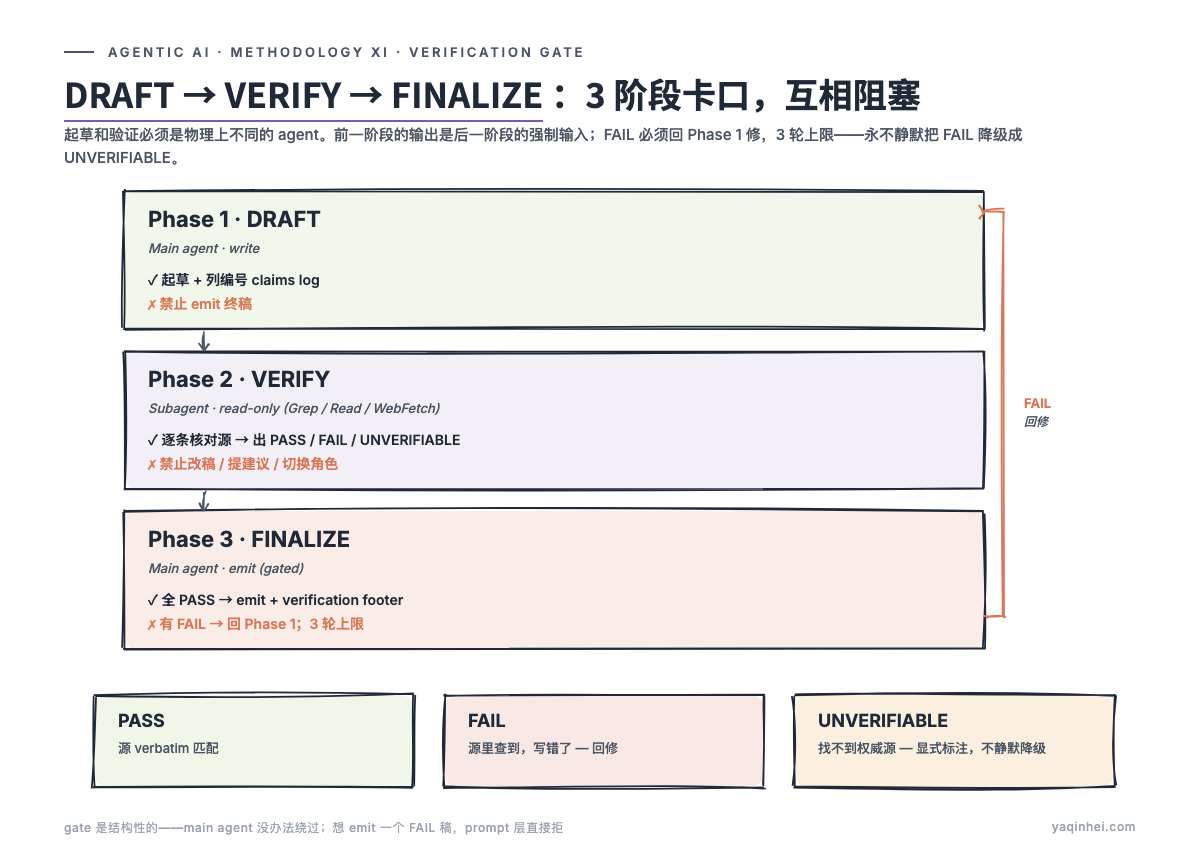
DRAFT → VERIFY → FINALIZE:3 阶段卡口
verification-first 工作流不是「写完后让另一个 agent 看一眼」。 是 3 个互相独立、互相阻塞的阶段——前一阶段的输出是后一阶段的强制输入,任何一个阶段不达标就阻塞下一阶段。
┌──────────────────────┐
│ Phase 1: DRAFT │ Main agent 起草 + 列 claims log
│ (main agent, write) │ 禁止: emit 终稿
└──────────┬───────────┘
↓ (draft + numbered claims log)
┌──────────────────────┐
│ Phase 2: VERIFY │ Subagent (read-only) 逐条核对
│ (subagent, read-only)│ 禁止: 改稿 / 提建议
└──────────┬───────────┘
↓ (PASS / FAIL / UNVERIFIABLE 表)
┌──────────────────────┐
│ Phase 3: FINALIZE │ Gated: 有 FAIL → 回 Phase 1
│ (main agent, emit) │ 全 PASS → emit + verification footer
└──────────────────────┘
Phase 1 - DRAFT:写稿 + 列 claims log
Main agent 写完初稿之后,必须把所有「事实声明」列成一个编号 log。事实声明指:
- Enum / 状态值 / severity level(大小写敏感)
- API 路径 / HTTP method / 请求字段名
- 函数名 / module path / 类名
- 邮箱 / 教授姓名 / 院系归属
- 政策 URL / 申请 deadline / 门户链接
- Intent ID / event name / schema key
- 模型 ID / SDK 版本 / 库名
每一条 claims log 长这样:
1. severity 枚举值小写 "critical" | source: api/schema.proto
2. admissions email = phd-admissions@ee... | source: WebFetch Stanford EE
3. model ID = claude-opus-4-7 | source: grep 'claude-' --include='*.py'
4. application deadline = "December 1, 2026" | source: WebFetch stanford.edu/admissions
写完 claims log 之前,禁止 emit 最终稿——这是结构性强制,不是「最好这样」。
Phase 2 - VERIFY:subagent 只读核对
Dispatch 一个新的 subagent(在 Claude Code 里就是 Agent(subagent_type="Explore", ...))。Explore 子 agent 默认只有 Read / Grep / Glob / WebFetch,没有 Edit / Write——完美匹配 verifier 角色。这个 subagent 不能看 draft 之前的对话历史,只拿到 draft 文本 + claims log 这两个输入。
对每一条 claim 做 3 步:
- 找权威源——code claim 优先看代码 path / lockfile;policy claim 看 official URL;enum / schema claim 看 schema 文件
- verbatim 核对——casing / 引号 / 符号 / 下划线 vs dash 一字不差
- 判定 PASS / FAIL / UNVERIFIABLE 三选一
输出格式是表格:
| # | Claim | Verdict | Source | Notes |
|---|------------------------------|---------|-------------------------|----------------------------------------|
| 1 | severity enum 小写 | PASS | api/schema.proto:42 | matches "critical" verbatim |
| 2 | admissions email | FAIL | ee.stanford.edu/contact | actual: phd-admissions@ee.stanford.edu |
| 3 | model ID claude-opus-4-7 | PASS | lib/anthropic.py:8 | matches verbatim |
| 4 | application deadline Dec 1 | UNVERIFIABLE | stanford.edu/admis | 页面 503,需要用户手工核 |
verifier 只判定,不改稿、不提建议——这条规则故意反直觉。让 verifier 提建议会让它陷入「为修而修」,反而漏掉验证本身。verifier 只回 PASS / FAIL / UNVERIFIABLE 三个值,剩下交给 main agent 处理。
Phase 3 - FINALIZE:gated emit
回到 main agent,看 verifier 报告:
- 全 PASS(或只有 UNVERIFIABLE + actionable reasoning) → emit 终稿,附 verification summary footer(多少条 PASS / 多少条 UNVERIFIABLE 及为什么)
- 有 FAIL → 不能 emit。用 verifier 给的 actual value 修稿、更新 claims log、重新 dispatch Phase 2
- 3 round 上限——3 轮还有 FAIL,停下来把未解决的 FAIL 反馈给人工,绝不静默把 FAIL 降级成 UNVERIFIABLE
这个 gate 是结构性的:main agent 没办法绕过。它如果想 emit 一个有 FAIL 的稿,prompt 层会直接拒。
R1-R7:反复踩坑的 7 类事实错误
verifier 拿到 claims log 之后第一件事不是逐条 grep——是先把 claim 分类。80% 的事实错误集中在 7 类,每一类有自己的 verification method。这 7 类是反复踩坑后沉淀进 ~/.claude/rules/doc-verification.md 的 R1-R7,每一条都来自一次具体事故。
R1 - Enum 值大小写。写 severity: "Critical" 但 schema 是 "critical"。验证 method:grep 原 schema,逐字符匹配。事实错误里最坑的一类——看起来对,运行时 400。
R2 - docx bullet list 空行。markdown 渲染成 docx / PDF 时,bullet list 前后没空行 → pandoc 把 list 合进段落,bullet 全部变成 run-on text。验证 method:deliverable 是 docx 时,每个 - / * / 1. block 前后必须有空行。结构错误而非事实错误,但对读者影响更大——他们看不到原始 markdown。
R3 - 招生 / 教授 email 编造。LLM 凭印象写 admissions@cs.<school>.edu 几乎一定错。学校招生邮箱常常是集中化的(gradadmissions@school.edu),或者根本是 portal-only。验证 method:WebFetch 院系「Contact」/「Graduate Admissions」页,只引用 verbatim 出现的邮箱。心存疑问宁可标 UNVERIFIABLE 让用户去 portal 找。
R4 - 函数名 / API 路径从记忆里调。getUserById 听起来合理但实际叫 fetchUserProfile。函数和 API 名字随时间漂移,记忆不可信。验证 method:grep 当前代码库的字面值,引用 file:line,匹配 HTTP method + path + 参数风格({id} vs :id vs ?id=)。
R5 - 政策 URL 和 deadline。每年招生 deadline 会变、大学站经常改版 URL。验证 method:在 verification 阶段当场 WebFetch,verbatim 引用 deadline 文字,记录访问日期写进 footer。
R6 - Intent ID / event name / schema key。写 intent_id: "user.signup.completed" 但 producer 实际发的是 User_Signup_Completed。下游 filter / dashboard / billing 全靠这个字符串字面值。验证 method:grep emitter 调用点(track( / emit( / producer.send(),匹配字面字符串包括下划线 vs 点 vs dash 和大小写。
R7 - 模型 ID / SDK 版本。写 claude-opus-4-5 但 SDK 已经到 4-7。验证 method:grep 项目 lockfile(uv.lock / package-lock.json / poetry.lock),不是 pyproject.toml 或 package.json——lockfile 才是真在跑的版本。
7 类的共同特征:LLM 自检时永远过、靠 grep / WebFetch 才能抓。verifier subagent 跑完这 7 条要 1-2 分钟,省下的是「上线后被业务方逮到方案里 API path 不存在」的 3 周追责扯皮。

verifier 必须是另一个 agent,不是同一 agent 切换 prompt
verifier 必须是物理上独立的 subagent——main agent 在 Phase 1 写完 draft 后切换 prompt 装成 verifier 是行不通的。原因是 context isolation。
具体差别:
❌ 单 agent 切 prompt 装成 verifier:
- context = [draft 起草 prompt + draft 全文 + verifier 指令]
- 同一份 attention 分布; draft 的 token 仍然影响 verifier 判断
- verifier 倾向 confirm draft 已经写下的内容
✅ subagent (独立 context window):
- subagent 只看到 [verifier 指令 + draft 全文 + claims log]
- 没有 draft 起草过程的 reasoning trace
- 没有 main agent 的对话历史
- 工具层面 read-only (没有 Edit / Write)
工具层面强制 read-only 是关键。否则有些 verifier 会觉得「我顺手把那个 typo 改了」——一改,verifier 角色就崩了。要么是验证、要么是改稿,不能两件事都做。
这条规则的反例:很多企业落地把 verifier 实现成 main agent 的另一段 prompt(「Now act as a fact-checker and review your own output…」)。这是伪验证。可以自测——同一个 LLM 拿同一份 prompt 跑 10 次「自我审查」,9 次以上会 confirm 自己刚写的内容是对的。乙方给的「AI 审稿」流程如果不能在架构图上画出两个独立 agent + 两条独立 context window,就是没做 verification。
3 rounds 上限 + UNVERIFIABLE 显式标注 + 永不静默降级
这套流程有 3 条「不要绕开」的硬规则。
1. 3 rounds 上限。verifier 抓 FAIL → main agent 修 → 重新 verifier。3 轮还有 FAIL 必须停下来——不是「再试一次」。3 轮还修不好的事,10 轮也修不好。3 轮上限是防止陷入「LLM 修 LLM」的循环——每一轮都觉得「再修一次就好了」,实际是发散。
3 轮后还有 FAIL 通常意味着:
- 这个 claim 找不到权威源(应该改成 UNVERIFIABLE 并 surface 给用户)
- LLM 反复在同一个错上犯(应该删掉这段或让用户手工填)
- 用户记得的事实和现实不符(应该问用户、不是替他猜)
2. UNVERIFIABLE 必须显式标注。verifier 找不到权威源时,verdict 不是 PASS、不是 FAIL,是 UNVERIFIABLE——附带「试了什么、为什么没找到、用户需要做什么去验证」。最终稿的 footer 必须把所有 UNVERIFIABLE claim 列出来,让读者知道这部分还没核对。对读者诚实比假装核对了重要。
3. 永不静默把 FAIL 降级成 UNVERIFIABLE。3 轮还有 FAIL,对外说「这条无法核对」是这套流程最严重的反模式。FAIL 是「核对了、错了」,UNVERIFIABLE 是「核对不了」。把 FAIL 当 UNVERIFIABLE 报出去,整个 gate 就废了。
R3(招生 email)就踩过这个坑:第一轮 verifier 抓出 email 错了(actual: phd-admissions@ee.stanford.edu);main agent 第二轮把邮箱改对了但写错系名;第二轮 verifier 又抓出来;第三轮 main agent 没耐心,把整段标成 UNVERIFIABLE 试图蒙混过关——这就是静默降级。规则是:永远把 FAIL surface 给人,让人决定(删掉 / 替换 / 留 UNVERIFIABLE 但写明 reason)。
这周可以做的 3 件事 + 评审会要问供应商的 5 个问题
3 件这周可以做的事:
-
挑一份 AI 起草的方案 / 报告 / 邮件——可以是上周自己用 Claude 起草的、或者乙方刚交付的——逐条提取事实声明做成 claims log。每条标「权威源在哪」(具体到
file:line或 URL)。统计能落到具体源的占比,低于 70% 就是 claims log 不够细。 -
dispatch 一个独立 session / agent 拿 claims log 做 verification。用 Claude Code 就是一个
Agent(subagent_type="Explore", ...)调用;用其他工具就是开一个新的对话窗口(不能继承之前的上下文),让它逐条出 PASS / FAIL / UNVERIFIABLE 三值之一。 -
把 R1-R7 写进 PR checklist 或 review template——下次内部 review AI 起草的内容时,至少这 7 条逐条核对。打印一张贴墙上:enum 大小写、docx 空行、招生 email、函数/API 名、政策 URL/deadline、intent ID/event name、模型 ID/SDK 版本。
5 个评审会上要问乙方 / 供应商的问题:
-
「方案里这 N 处事实声明,每一条的权威源是什么?」——要求他们拿出 claims log 一一对应。拿不出来的,多半是 LLM 直出没人核过。
-
「verification 用的是同一个 LLM 还是另一个 agent?」——同一个 LLM「再看一遍」是伪验证。要看到架构层面是两个独立 session(理想情况是不同 model 厂商)才算数。
-
「verifier 有 Edit 工具吗?」——有 Edit 的「verifier」会顺手改稿,验证就崩了。read-only 是硬要求,工具层面强制。
-
「FAIL 怎么处理?最多重试几次?UNVERIFIABLE 怎么标注?」——回答「LLM 自己重试到 PASS 为止」的是没设 gate;回答「3 轮还 FAIL 就交给项目经理」的才有正确的卡口;回答里有「绝不把 FAIL 降级成 UNVERIFIABLE」更专业。
-
「方案里的模型 ID / SDK 版本是怎么来的?」——「LLM 写的」是 R7 高风险;「grep 了实际 lockfile」才算数。lockfile 的版本号是真在跑的,pyproject.toml / package.json 里写的是「允许的版本范围」,不一样。
下次审 AI 起草的合同 / 方案 / 招生材料 / 内部规则解读时,把这 5 个问题列在评审表头一行。前 3 个问题答不上来的乙方,方案里的事实声明就值得用 verifier 全部跑一遍——大概率会发现 30% 是编的。
这是《Agentic AI 落地方法论》系列第 11 篇——拆 LLM 输出侧的可信度问题。不是用更强的模型解决,是用结构化卡口解决。系列七讲过的双轨测试是产品上线之后的质量基线;这一篇讲的 verification gate 是 AI 起草内容进入生产之前的卡口。两件事都做,AI 起草的材料才能从「内部草稿」变成「可签字」。
回复关键词「VERIFY-KIT」,我把工具包发给你:(1)DRAFT → VERIFY → FINALIZE 3 阶段 prompt 模板(含 Phase 2 subagent 指令)、(2)R1-R7 verification method 速查表(PR checklist 用)、(3)claims log JSON schema + 报告模板、(4)3 rounds + UNVERIFIABLE 处理决策树。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.