自动化率 70% 的 Critic 比 95% 的更值钱——fail-closed 设计深挖|Agentic AI 落地方法论(三)

《Agentic AI 落地方法论》系列第三篇。 第二篇《5 个架构决策,决定你的客服 Agent 能不能上线》提出了 L2 设计的 5 个关键岔路口,其中决策 3:Critic 必须 fail-closed——是「整个系列最反直觉的一篇」。这一篇兑现深挖:Critic 怎么写、阈值怎么定、人工队列怎么管、什么时候用规则 Critic、Critic 自己怎么 eval。English version: Why a 70% Critic Beats a 95% Critic — A Fail-Closed Design Deep Dive.
一笔多发了一个零的退款
某个零售客服 Agent 上线第 14 天。供应商 demo 时承诺过自动化率 95%,团队拍板上线。
试点第 14 天晚 8 点。一笔 980 元的退款发到一位老客户卡上。流程很正常——查订单(成功)→ 命中政策(成功)→ Critic 二次审核(启动)→ Critic 超时(接 LLM 服务降级)→ 放行 → 财务 API 调用(成功)。
唯一问题:这一单订单总额 980 元(一组配件),其中只有一个单价 98 元的小件因质量问题需要退——应退金额是 98 元,不是 980 元。但 LLM 把「退款金额」参数错填成了订单总额 980 元——多了一个零。Critic 本该在二次审核时拦住——但 Critic 超时了,方案选了「超时即放行」,钱发出去了。
复盘会上技术负责人说:「Critic 失败时还是放行了,不是 Critic 没起作用。」CEO 不太接受:「Critic 是兜底的,超时不就该升级人工吗?为什么是放行?」技术负责人答:「因为升级人工会让自动化率从 95% 跌到 70%。」
这场对话里有一个没说出口的赌——团队赌「Critic 大多数时候不会超时」;CEO 赌「Critic 失败时要保险」。哪一个对?
答案是 fail-closed:Critic 失败就升级人工,不放行。但它有一笔现实代价 —— 起步阶段升级率会从 5% 跳到 30%,需要算明白才能跟 CEO 谈。这篇文章就把这笔账算清楚,从 3 类失败场景的处理、prompt 怎么写、阈值怎么定、规则 vs LLM Critic、人工队列怎么管,到 Critic 自己怎么 eval。读完你能回到 CEO 面前,拿出一份能签字的方案。
Critic 失败的 3 类场景:超时、错误、低置信度——每一类 fail-open 都会出事
写操作的 Critic 会在三种场景下失败:超时(timeout)、错误(error)、置信度低(low-confidence)。这三类看起来都是"少数情况",但每一种发生时,正是系统最不应该放过的时刻。Fail-open 把它们当成"通过"——这是这篇文章要拆掉的赌局。下面逐个看。
超时。LLM 超时通常意味着模型负载在高峰——晚 8 点电商大促、供应商被多个企业客户挤兑、网络抖动。这种时刻 LLM 自身的判断质量本来就在退化(高负载 = 限流 + 降级 + tail-latency),Critic 的二次审核更难做对。Fail-open 在这里说「超时算通过」——质量最不靠谱的时刻反而被放过去。开篇那笔 980 元退款就是这个场景:晚 8 点平台 LLM 服务降级,第一个 LLM 在边缘判断错了"多一个零的金额",Critic 本该拦住,结果因同一波降级超时了。
错误。Critic 报错(HTTP 5xx / JSON 解析失败 / prompt-injection 被识别)通常意味着输入不在已知模式里:数据脏、上下文有没见过的字符、用户在对话里塞了奇怪的 token、外部 API 返回格式变了。这恰好是最需要 Critic 看一眼的时刻。「反正报错是少数」——但报错那一笔单子,往往就是异常 + 风险最高的那一笔。
置信度低。这是最隐蔽的一类。Critic 返回了"通过",但带着 0.55 的低置信度——LLM 在说"我不太确定"。Fail-open 把这种返回当通过处理,因为它在协议上确实是"通过"。但低置信度本身就是信号:LLM 知道自己拿不准。把 0.55 的"通过"当作 0.95 的"通过"用,是把 Critic 的诚实变成了系统的盲点。
三类异常场景下 fail-open 和 fail-closed 的处理分歧,在系列第二篇的这张图里已经画过——同一张拿过来用:
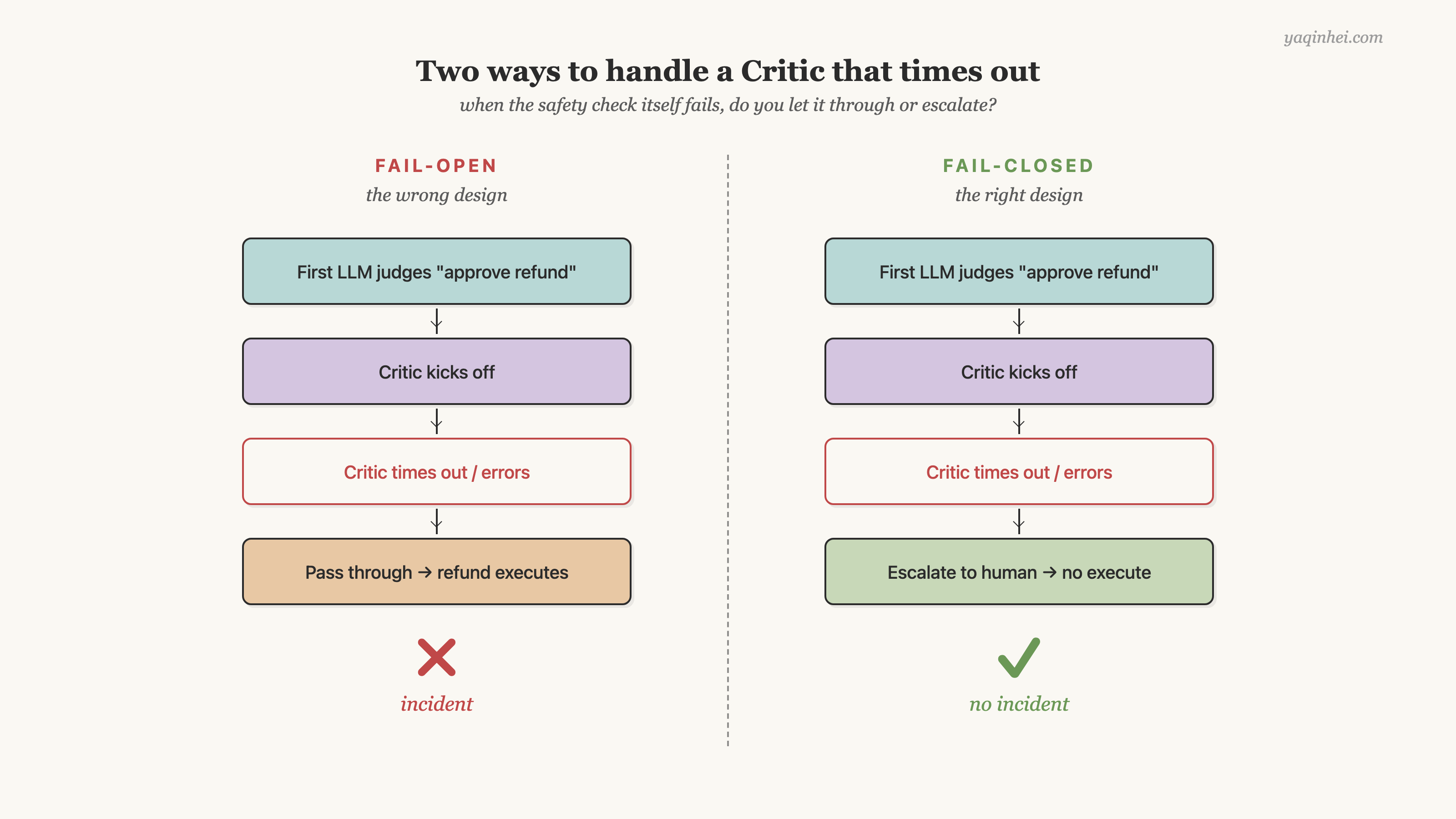
汇总成一张行动表——
| 失败场景 | Fail-open 的处理 | Fail-closed 的处理 | 为什么 |
|---|---|---|---|
| 超时 | 放行 | 升级人工 | 超时通常意味着服务降级;质量最差时反而被放过 |
| 错误 | 放行 | 升级人工 | 报错往往因输入异常;正是最需要审查 |
| 低置信度(0.7 以下) | 当通过处理 | 升级人工 | LLM 自己在说"不确定";把诚实当盲点 |
| Critic 明确"否" | 升级人工 | 升级人工 | 唯一两种设计都同意的场景 |
| Critic 明确"通过" + 高置信度 | 执行 | 执行 | 唯一两种设计都同意的另一种场景 |
5 种返回里,4 种 fail-open 和 fail-closed 处理一样——分歧只在前 3 种异常场景。fail-open 把异常当通过,fail-closed 把异常一律升级。代价是 30% 的人工升级率——开篇那笔 980 元事故告诉你,这笔代价是值钱的。
供应商常常反驳:「我们 Critic 失败率只有 3%,对系统影响不大」。这个反驳错在哪?失败率不是随机分布的。失败的那 3%,恰好是高风险的那 3%——所有事故都集中在这 3% 里。
客服 Agent 的写操作和银行交易系统是同一类问题——这就是 fail-closed 的由来
很多 LLM 工程师做 Critic 设计时觉得自己在开拓未知领域。其实不是。客服 Agent 的写操作和银行交易、医院医嘱、航空检查清单是同一类问题——所有这一类系统过去几十年都收敛到了同一个答案:fail-closed。
把这一类问题的特征拆出来,是 4 条——
- 写操作不可逆。退款发出去 = 钱到用户卡上;工单创出去 = 门店收到通知;短信发出去 = 用户已经形成预期。撤销要走单独流程,有时间窗口外的不可逆性。
- 责任要落地。客服项目上线之后,会被监管 / 合规 / 内部审计 / 客诉四类人追问「这一笔为什么这么走」,每一步都需要审计链路可查。
- 兜底机制本身会失败。Critic 会超时、报错、置信度低——上一节的 3 类场景。兜底失败本身需要再一层兜底,这一层就是"失败了走哪里"。
- 决策的边际成本远低于事故的成本。多发一笔人工审批 vs 多发一笔错误退款——后者的代价高一两个数量级。这种不对称决定了"宁可错升 10 笔,不能错放 1 笔"。
这 4 条叠加在一起,结论是兜底机制必须 fail-closed——失败时升级,不放行。这不是 LLM 系统独有的难题,是所有"高代价不可逆写操作"系统都要处理的。看几个跨行业的例子——
- 银行交易:风控引擎失败 → 拒绝交易 + 升级人工。监管框架(PCI-DSS、SOX、各国央行清结算条例)写得很清楚,任何一道审核失败,交易必须 hold,不能 pass-through。金融行业磨了 30 年。
- 医院医嘱:药品 / 剂量交叉检查失败 → 暂停医嘱 + 升级药剂师复核。HIPAA + JCI 标准里这是 hard requirement。
- 航空检查清单:起飞前任何一项「unverified」→ 不放行起飞。NTSB 数据库里因「跳过 checklist」导致的事故占所有航空事故的 20%。
这三类系统有一句共同的设计哲学——"safety is what happens when nothing happens"。系统按预期工作时没人注意到 fail-closed,但一旦兜底失效,fail-closed 是唯一让你在事故后能在董事会 / 监管 / 法庭上拿出来交代的设计。
客服 Agent 在这 4 条上对得很整齐,所以同一个结论:Critic 失败 → 升级人工 + hold,不能 pass-through。
这一段值得在 CEO 面前讲。CEO 一旦听懂"这是高代价系统几十年的工程共识,不是 LLM 团队的洁癖",对 fail-closed 的抵抗会消失大半——把 fail-closed 从"工程师的设计偏好"翻译成"行业的最佳实践",是给团队争取设计权最有效的话术。
反过来,如果供应商说「我们的 Critic 是 fail-open,因为 LLM 系统不一样」——你可以反问:「fail-open 的风控引擎你愿意接入你的网银吗?fail-open 的医嘱核对你愿意用在你家人身上吗?」LLM 系统不会因为是 LLM 就脱离这 4 条特性。一个供应商用"LLM 不一样"为 fail-open 辩护,等价于跟银行说"我们的风控不一样所以可以放行"——没人会信。
Critic prompt 怎么写:从"审核一下"到"逐项核对 N 种已知错误"
很多团队上来就写出这样的 Critic prompt:
你是一个客服 Agent 的二次审核员。请审核下面这个退款决策是否合理:
[退款决策内容]
请回答:通过 / 不通过 + 理由。
跑两天就会发现问题——LLM 会自信地"通过"绝大多数决策。不是因为决策真的对,而是因为"审核"是个抽象任务,LLM 没有具体的 hook 去触发"不通过"。Critic 变成了一个橡皮章。
可上线的写法是把"审核"换成"逐项核对 N 种已知错误模式"——任务从开放性判断变成枚举性核对。看一个示例:
你是一个客服 Agent 的二次审核员。下面是第一个 LLM 的退款决策,
你需要逐项核对**这 8 种已知错误模式**,任何一项命中 → 输出"不通过"+
具体命中的模式编号。
## 已知错误模式
1. 退款金额与子项实际金额的位数不匹配(如应退 98 元的小件,LLM 填了 980 元订单总额——多一个零)
2. 订单归属为"品牌寄售" 但走了"平台直营"的退款路径
3. 商品状态为"已使用"但走了"7 天无理由退货"路径
4. 物流状态为"已签收 30 天以上"但走了"未签收"退款路径
5. 用户身份核验缺失(订单非本人下单 + 未提供身份证明)
6. 退款金额超过单笔授权额度(超过 5000 元需走人工审批)
7. 同一订单 30 天内已退款过(重复退款风险)
8. 退款理由文本里含敏感关键词(涉嫌欺诈 / 系统漏洞 / 价格异常)
## 第一个 LLM 的退款决策
[决策内容]
## 输出格式(JSON)
{
"verdict": "通过" 或 "不通过",
"matched_pattern_ids": [],
"confidence": 0.0-1.0,
"reasoning": "一句话"
}
差别在三处。第一,Critic 不再被问"对不对",而是被问"是否命中以下任何一种已知错误"——LLM 的执行质量稳定一个数量级。第二,每种错误模式都是具体的、可命中的,Critic 不需要"理解"业务,只需要"匹配"模式。第三,结构化 JSON 输出让下游可以根据 matched_pattern_ids 自动 routing 升级到不同的人工队列:金额异常 → 财务审批,归属错误 → 业务专家,身份核验缺失 → 风控。
这 8 种模式从哪来?从你过去 3-6 个月的事故复盘里。每次复盘的产出应该包括"这类错误的特征是什么"——这些特征就是 Critic prompt 里的模式。开篇那笔 980 元事故复盘后,模式 1(位数不匹配)就是从这一笔事故抽出来的。
Critic prompt 不是一次写完的,是「事故复盘 → 模式抽取 → prompt 更新」的循环。我跟过的客服 Agent 项目里,3-6 个月后 Critic prompt 的模式列表通常从起步的 6-8 条扩到 18-25 条——这个增长是健康的,意味着团队在系统化地学习生产环境。
供应商如果给你的 Critic prompt 没有具体的模式列表,只有"审核 / 二次核查 / 检查合理性"这种空泛描述,等于没有 Critic。如果 prompt 半年没更新,意味着团队没从事故里抽模式,Critic 在静态化,覆盖率会被新场景甩开。
阈值怎么定:置信度 × 业务关键度的二维表
最常见的设计是「置信度低于 0.7 升级人工」——一刀切。问题在这个 0.7 在不同业务关键度下意义完全不同:内容推荐错了一条没人在意,退款金额错了一笔就是事故。同一个数字两件事。
升级阈值应该是一张二维表——置信度高低 × 业务关键度,四种组合对应四种动作:
| 置信度 \ 业务关键度 | 低关键度(如内容推荐) | 中关键度(如查物流) | 高关键度(如退款 / 改单) |
|---|---|---|---|
| 高(0.85 以上) | 直接执行 | 直接执行 | 直接执行 |
| 中(0.65-0.85) | 直接执行 | 直接执行 | 升级人工 |
| 低(0.65 以下) | 直接执行 + 留痕 | 升级人工 | 升级人工 |
| Critic 失败 | 直接执行 + 留痕 | 升级人工 | 升级人工 |
业务关键度怎么定?三个维度:可逆性(不可逆 = 高)、金额 / 影响范围(高 = 高)、合规要求(涉资 / 涉客户隐私 = 高)。客服 Agent 的写操作大致分布如下:
- 高关键度:退款、改单、创工单(涉门店物流)、扣库存、给用户发推送——不可逆 / 涉资 / 影响外部系统的动作
- 中关键度:查物流、查订单、查会员积分——只读但用户能看到结果
- 低关键度:对话上下文 summarize、内容推荐排序、FAQ 二选一——对话内的轻量动作
阈值 0.65 / 0.85 是经验起点,跑 1-2 周后看数据调。调整方向看升人工率:某一档升人工率超过 40% → 阈值放宽(0.65 → 0.55);低于 5% 但事故率上升 → 阈值收紧(0.65 → 0.75)。阈值不是一次定下,是一个 closed-loop 的过程。
注意一个反直觉的设计——低关键度的"低置信度"也允许直接执行 + 留痕,不升级。低关键度即使错了代价也低(推荐错一条内容、summarize 不准),但升级人工的代价是固定的(占用人工坐席、增加用户等待)。在低关键度上 fail-closed 是过度设计。fail-closed 的精髓不是"任何失败都升级",是「高代价场景失败必须升级」。
供应商如果只给你单一阈值("置信度低于 0.7 升级"),没区分业务关键度,意味着设计没考虑过代价分配——要么把人工坐席压垮(一刀切收紧),要么在高关键度场景埋雷(一刀切放宽)。
规则 Critic vs LLM Critic:什么时候用哪个
很多团队的 Critic 是纯 LLM 串联:第一个 LLM 出方案、第二个 LLM 审稿。跑起来你会发现三个问题——LLM Critic 慢(+1-2s 延迟)、贵(+50% LLM 成本),而且有些检查 LLM 还不如规则准(数值比较、格式校验,LLM 没规则稳)。
更扛得住生产环境的设计是双层:规则 Critic 先跑(毫秒级),命中任何一条 → 直接升级 + 跳过 LLM Critic;规则全过 → 才轮到 LLM Critic 二次审核。
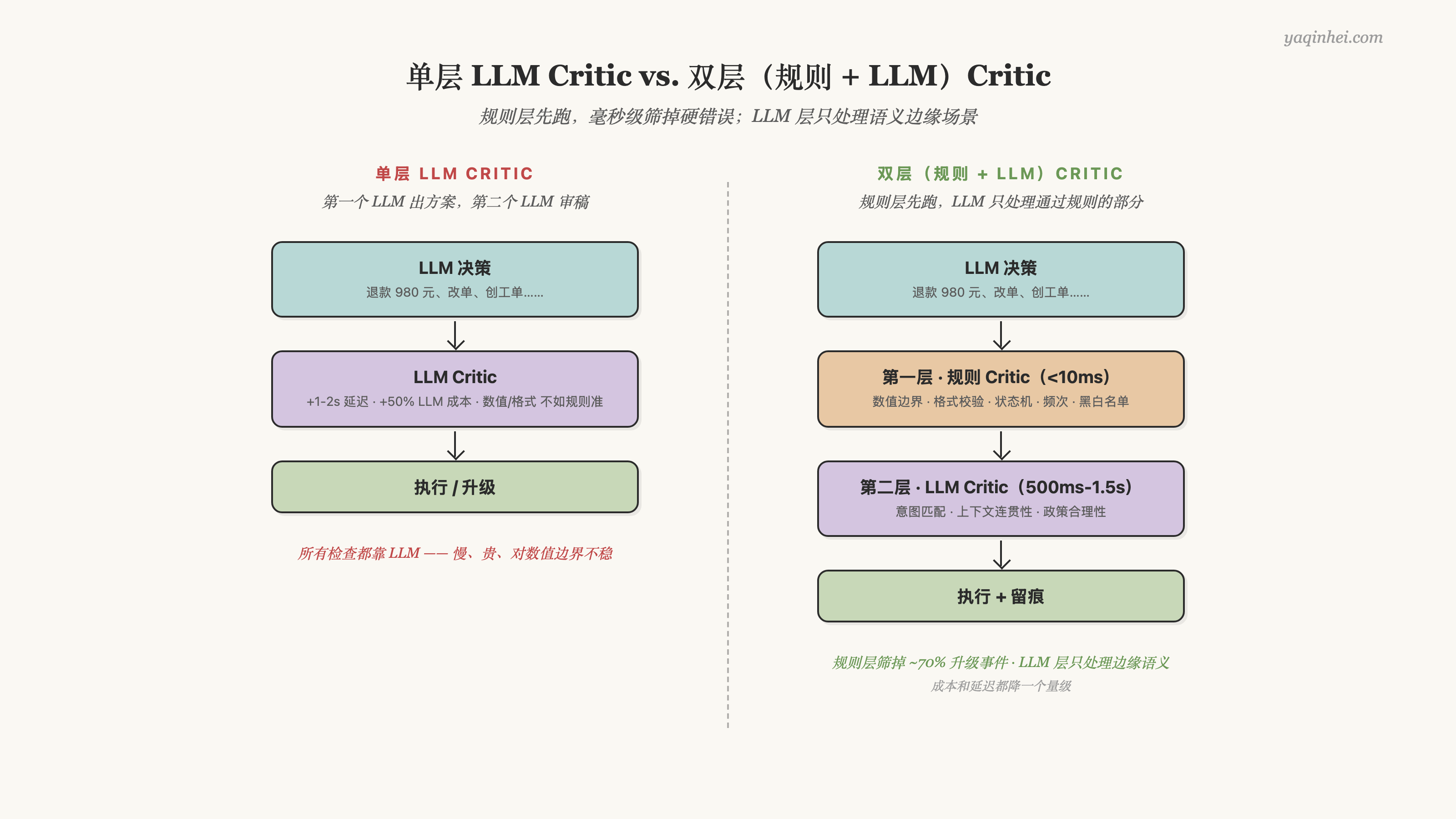
规则 Critic 适合所有可以精确表达的检查:
- 数值边界:退款金额超过单笔授权额(超过 5000 元)→ hard stop
- 格式校验:JSON schema、字段必填、枚举值合法
- 状态机约束:订单状态 ≠ "已完成" 不能退款;用户身份未核验不能改单
- 频次 / 速率:同一用户 5 分钟内退款次数 > 3 → flag
- 黑名单 / 白名单:高风险用户、特定 SKU 例外
LLM Critic 适合所有需要语义判断的检查:
- 意图与动作匹配性:用户说「这个东西不太好用」,LLM 解读成"退货意图"——这种解读对不对,规则写不出
- 上下文连贯性:对话历史里用户表态"先不退",新 LLM 却输出了"已为你处理退款"——这种矛盾规则识别不了
- 政策应用的合理性:商品状态 + 物流状态 + 用户身份 + 时效 + 类目政策,5 个变量交叉判断——规则写出来会爆炸,LLM 反而擅长
一张对比表:
| 维度 | 规则 Critic | LLM Critic |
|---|---|---|
| 延迟 | 10ms 以下 | 500-1500ms |
| 成本 | ≈ 0 | 几分到几毛/次 |
| 精度(适用场景内) | 99%+ | 85-95% |
| 维护成本 | 加规则 = 加代码 | 加模式 = 改 prompt |
| 适合场景 | 可精确表达的检查 | 需要语义判断的检查 |
| Critic 自身失败率 | 0.1% 以下 | 3-10% |
最后一行值得多看一眼——规则 Critic 几乎不会失败(除非代码 bug)。规则先跑 = 大部分写操作在规则层就被筛过了,LLM Critic 只需要处理剩下的边缘场景。这一层架构能把 LLM Critic 的调用量降一个量级,对成本和延迟都是大幅改善。
如果供应商说「我们 Critic 是纯 LLM 设计,没有规则层」——大概率上线之后成本和延迟都会失控,因为 LLM Critic 在做规则该做的事(金额检查、格式校验、状态机判断)。这种设计在 demo 视频里看不出问题,在生产环境的高并发下会翻。
人工兜底队列怎么管:30% → 5% 的下降曲线,别在起步阶段把它做反
先把结论摆桌面上——fail-closed 起步阶段会把 30% 的写操作升级到人工,这是宝贵反馈,不是失败信号。3-6 个月后会自然降到 5% 以下,自动化率反而高于 fail-open 设计。
这一段是给 CEO 看的,不是给工程师看的。工程师都懂;CEO 在自动化率压力下会要求"先用 fail-open,等稳定了再切 fail-closed"——这是 fail-closed 项目最常见的死法。
下降曲线的三个动力学:
第一,起步阶段 Critic prompt 不完善,模式列表只有 6-8 条,遇到没覆盖到的边缘场景一定误升级。这 30% 升人工里,大约 20% 是误升级(真没问题但被升) + 10% 是 Critic 正确识别的风险。那 20% 误升级是产品迭代的金矿——每一个误升级的 case 复盘出来都能成为新的 prompt 模式或阈值调整,3 个月内 Critic 的精度能提升 2-3 倍。
第二,起步阶段第一道 LLM 决策的质量也在迭代。第一个 LLM 的 prompt 在持续优化(结合人工反馈),输出质量在提升——Critic 升级的比例自然下降。
第三,业务团队会逐步识别"哪些场景根本不该让 Agent 做"——这些场景从 Agent 里剥离出去(直接走规则或人工),剩下的场景 Agent 处理得更好。
三个动力学叠加起来,3-6 个月后升人工率从 30% 降到 5% 以下。我跟过的 fail-closed 项目都是这条曲线,没遇到过例外。
反过来,fail-open 的轨迹长这样:起步自动化率 95%(看着漂亮)→ 第 3-6 周出第一笔事故(钱发错 / 工单创错 / 短信发错)→ 复盘 → 整体下线整改 1-2 周 → 二次上线后小心翼翼 + 加大量 hard-stop 规则(实质退化为 fail-closed)→ 自动化率掉到 50% 以下且再也起不来。长期看 fail-closed 跑赢 fail-open 不是悬念。
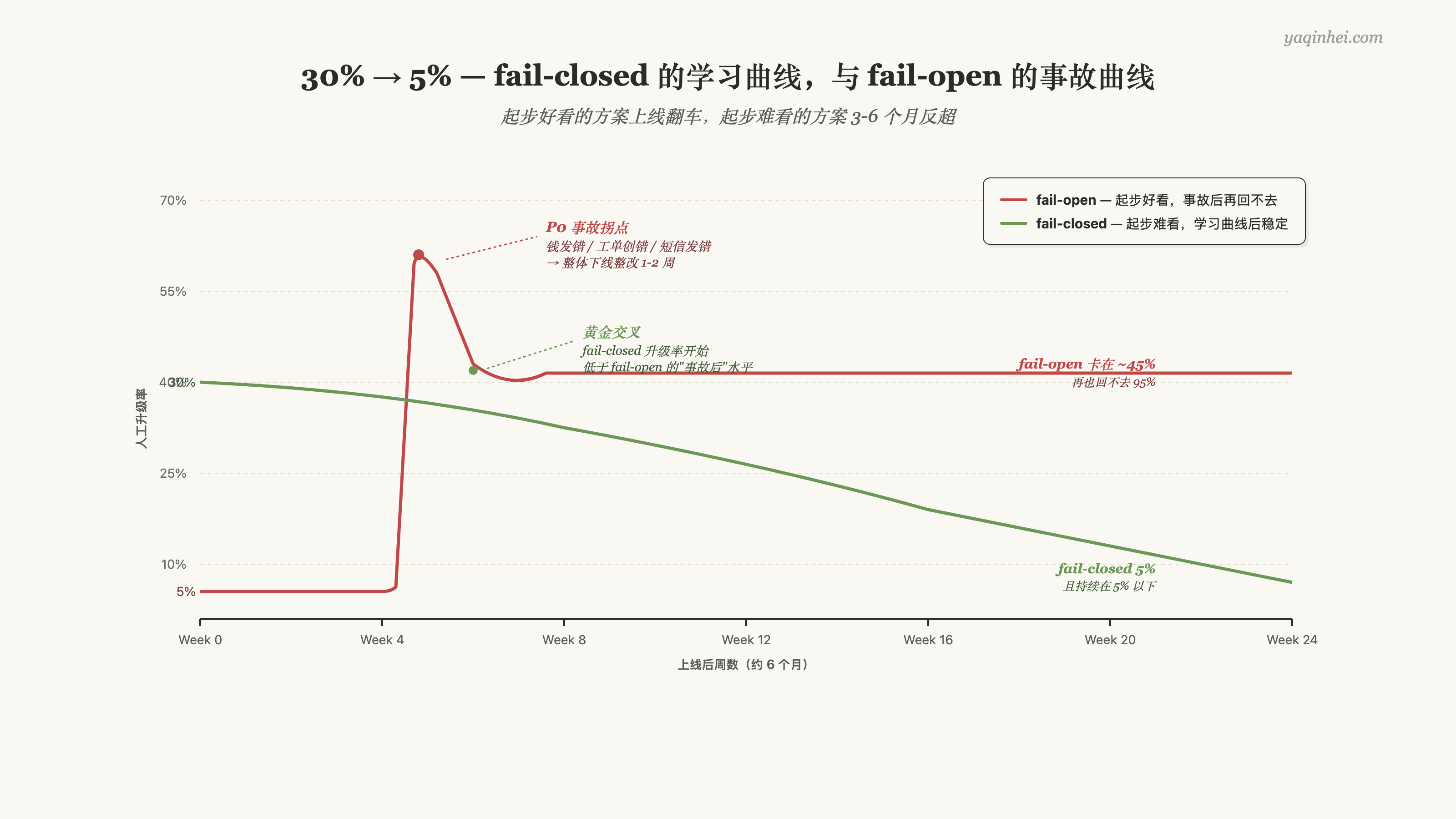
把上面那张曲线图放在 CEO 面前。第一眼是反直觉的——一个起步 30%、一个起步 5%;第二眼之后才明白要看 6 个月的整条曲线,不是看第一周的截面。
那这 30% 升人工的队列怎么管?三个关键点:
队列要分类。按 Critic 输出的 matched_pattern_ids routing 到不同人工组(金额异常 → 财务、归属错误 → 业务专家、身份核验缺失 → 风控)。每组的 SLA 不同(金额异常优先级最高,5 分钟内必须有人处理),不能一锅端给客服。
反馈要回流。每一个升级人工的 case,人工处理后要标两个字段:「Critic 是否升级正确」(true/false)+「如果 false,原因是什么」。这两个字段每周聚合一次,驱动 prompt 和阈值的调整。
KPI 要重设。fail-closed 起步阶段不能用「自动化率」做团队 KPI——会驱动团队偷偷把 fail-closed 改回 fail-open。换成「净自动化率」:(自动化处理 - 事故影响订单 ×100)/ 总单量。一笔事故等于扣 100 笔正常自动化,这个权重让 fail-open 在 KPI 上永远算不过 fail-closed。供应商如果只给你「自动化率」单一指标,要求换成净自动化率或类似复合指标——否则你雇的就是一个推着团队改 fail-open 的 KPI。
Critic 自己怎么 eval:递归审核的元问题
Critic 也是 LLM,本身会出错——必须有 ground-truth eval set 持续跑,盯两个指标:漏放率(false-negative)和误升率(false-positive)。
这一节技术深度比较高,业务老板可以跳过。但项目成败常卡在这一步——Critic 上线后没人 eval,慢慢变成黑盒,等到事故才发现。
eval set 的两个源头:
历史事故 + 反例。把过去 3-6 个月的事故复盘 + 已知边缘 case 整理成 ground-truth 数据集,每条数据包括「输入决策」和「应该升级 / 应该放行」的标注。这组数据是 Critic 必须 100% 正确处理的——漏掉任何一条 = 上线前的 bug。
正常路径的随机采样。从生产环境随机采样 500-1000 个正常通过的决策(人工确认真的"应该通过"),跑 Critic 看它是否把这些都标"通过"。这组测试误升率:Critic 不能把正常 case 错升到人工。
两组合起来形成 eval set,定期跑:
| 指标 | 定义 | 目标 |
|---|---|---|
| 漏放率(False-Negative) | 应该升级但被 Critic 标为"通过"的比例 | 1% 以下(强约束) |
| 误升率(False-Positive) | 应该通过但被 Critic 标为"不通过"的比例 | 20% 以下 起步,3 个月降到 10% 以下 |
| Critic 自身失败率 | timeout / error / 低置信度的总比例 | 10% 以下 起步,跑稳后 5% 以下 |
两个指标的优先级很不一样。漏放率必须接近 0——Critic 是兜底,漏放 = 事故。如果一个版本的 prompt 改动让漏放率从 0.5% 升到 1.5%,这个改动得回滚,不管它在别的维度上看着多好。误升率可以慢慢降,起步 20% 是正常的(Critic 在保守模式下成长),3-6 个月降到 10% 以下。
eval set 每周更新一次:把上周生产环境的事故 + 人工反馈的"Critic 误升级"case 加入 eval set,重新跑全量。eval set 应该长大,不该停留——一个长不大的 eval set,说明团队没从生产环境学到东西。
供应商如果上线后从不更新 Critic eval set,意味着 Critic 在静态化,覆盖率会被新场景甩开。还有一种情况要注意:供应商只给你 Critic 的"精度 / 召回",不给「漏放率 / 误升率」——这两组数字看起来类似但语义完全不同。漏放率是 fail-closed 的命门指标,没有这个数字基本等于没有 eval。
6 个信号:5 分钟看清供应商的 Critic 设计
把上面所有内容压缩成一张对照表——下次会议上拿出来对照——
| # | 信号 | Fail-open 答案 | Fail-closed 答案 |
|---|---|---|---|
| 1 | 「Critic 超时怎么办」 | 自动放行 / 默认通过 | 升级人工 |
| 2 | 「Critic 报错怎么办」 | 跳过 + 留痕 / 默认通过 | 升级人工 |
| 3 | 「Critic prompt 长什么样」 | 「审核合理性」空泛描述 | N 种已知错误模式枚举 |
| 4 | 「升级阈值是怎么定的」 | 单一数字("0.7 以下 升级") | 二维表:置信度 × 业务关键度 |
| 5 | 「Critic 是规则还是 LLM」 | 纯 LLM / 纯规则 | 双层:规则先跑 + LLM 二次审核 |
| 6 | 「Critic 自己怎么 eval」 | 没有 eval / 只看"通过率" | 漏放率 1% 以下 + 误升率 20% 以下,每周 eval |
5 分钟你就能定级。任何一个供应商的 Critic 设计,6 个问题问完就能看清——是经过生产环境磨过的方案,还是 demo 里好看的伪装。
如果 6 个问题里有 3 个以上是 fail-open 答案,这个方案上线后会出事。要么让供应商按 fail-closed 重做,要么换供应商。
文章发出后的一条补充
X 上有读者(@jsyqrt)指出了一个本文漏掉的上游招——比 fail-closed Critic 更上游的 guardrail,是 typed deliverables。
把所有能塞进 schema 的东西——refund_amount: number ≤ order_amount、policy_clause: enum、customer_id: required——全部从 LLM 判断里拿出来。LLM 还是生成 payload,但类型校验器在 Critic 看到之前就把不符合 schema 的输出打回去。Critic 只剩下类型表达不了的语义和政策判断("每个字段都合法,但这次退款在退货窗口内合不合理")。
Types catch what they can; Critic catches what types can't——类型能管的归类型管,Critic 只管类型管不了的。 两层,不是一层。如果你今天从零开始搭,先做 typed deliverables(Pydantic AI / Instructor / Outlines / OpenAI structured outputs 都能做),本文的 fail-closed Critic 应用在上面那层语义判断——Critic 面对的表面要小得多,也更容易做对。
工具包领取
如果你想把这篇里的工具立刻用到下次评审会——不用每次开会都翻这篇文章——我整理了一个 PDF 工具包给读到这里的读者。回复关键词「Critic 检测包」,我把工具包发给你:
- 6-信号 fail-open vs fail-closed 检测表(名片卡版,评审供应商方案时逐条勾)
- Critic prompt 模板(枚举 N 种已知错误模式的写法骨架,可填空套用)
- 二维升级阈值表(置信度 × 业务关键度,一页 A4 打印版,贴在工位墙上)
两年客服 Critic 设计沉淀下来的判断工具。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
这个系列接下来要写什么
系列第四篇已发布:上线即放养:AI Agent 项目最贵的认知陷阱——拆上线之后的 6 个运维环节,跟本篇 Critic 设计合起来就是「上线 + 上线后」的双层兜底。
A4 系列下一篇排期——
- 3 级 intent 级联调参(决策 2 深挖):规则 + embedding + LLM 三级 fallback 的置信度阈值、cache 策略、新意图上线怎么不影响存量
- LLM 接入企业 SaaS 生态(决策 4 深挖):25 API → 5 tool 的封装契约、幂等性、超时重试、灰度发布
- 接住率 vs 解决率深挖(决策 5 深挖):KPI 迁移路径、双指标并存的过渡期、给老板汇报的话术
- AI 系统怎么测(独立深挖):双轨架构 + 7 质量维度
如果你的团队正在做客服 Agent,这 4 篇接下来 3-4 周内会一篇一篇出。
本文是《Agentic AI 落地方法论》系列第三篇。 前两篇:
系列追踪 Agent 项目从立项到上线的方法论。订阅按钮在文末,发新文章会推送。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.