意图分类(intent classification)怎么做:规则 / Embedding / LLM 三级级联怎么定阈值

《Agentic AI 落地方法论》系列第八篇。 前 7 篇拆「方案能不能上线 + 上线后怎么不放养 + 北极星 + 脑手分离 + 怎么测」——L0-L3 定级、L2 vs L3 的 5 个架构决策、Critic fail-closed、上线即放养、接住率 vs 解决率、Skills vs 知识库、双轨测试。这一篇兑现系列二决策 2 的深挖预告——意图分类的 3 级 fallback,阈值到底怎么定。English version: Tuning the Cost / Precision / Latency Triangle for the 3-Tier Intent Cascade.
1102 条样本里的一句"加点 LLM 兜底就行"
某个零售客服 Agent 项目跑了三个月,运营在 dashboard 上看到一组数字:1,102 条用户消息,意图分类准确率 59.44%,unknown 占比 40%。
业务方提了个看起来很合理的要求:「这 40% 的 unknown,加点 LLM 兜底不就好了?」
乙方加完了。一周后第一次月度账单出来——意图分类这一节的 API 成本是之前的 12 倍,准确率上去了 8 个百分点。老板看着账单坐了半个小时没说话。
这件事我在过去一年的项目里看过不下三次,换汤不换药——
- 第一种走法:纯规则。意图体系从 15 个长到 30 个,规则之间开始打架,三个月后没人愿意维护,整个工程团队反弹。
- 第二种走法:纯 LLM。「现在大模型这么便宜,不就调个 API 嘛」——高并发场景每天 60 万次调用,月成本拉到六位数,延迟撑不住 SSE 流式。
- 第三种走法:3 级 fallback。规则 60% + embedding 30% + LLM 10%,成本是纯 LLM 方案的 1/10,准确率反而更高。
第三种是这一年我看到所有能稳定上线的客服 Agent 共同的选择。但 3 级 fallback 真正难的不是架构,是阈值怎么调——置信度多少直返、ambiguity gap 多少触发反问、LLM unknown 多少算正常、cache 怎么做、限流怎么走。
这一篇拆开这套调参手册。下次评审会再有人说「加点 LLM 兜底就行」,你能把这张表拍他脸上。
文章后半还会讲一件事:3 级 fallback 跑稳之后,下一步该往哪走——v1 调到顶(意图体系超过 40 个 + policy 边界反复改 + anchor tuning 边际收益跌到 +2pp 以下),自然演进到 v2 LLM Router——LLM 综合 context + query + 多轮历史直接路由到 ACTION / POLICY / CLARIFY 几条主路径,多轮澄清天然支持。两套架构不是替代,是演进,第 8 节专门讲。
两个极端方案为什么都是死路
先把结论摆桌面上:纯规则、纯 LLM、3 级 fallback 是三种架构选择,前两个上线都翻车。
| 方案 | 成本 | 延迟 | 准确率天花板 | 维护成本 | 上线后死法 |
|---|---|---|---|---|---|
| 纯规则 | ~0 | 1ms 以内 | 70-75% | 极高 | 意图过 30 个之后规则打架,工程半年内反弹 |
| 纯 LLM | 高 10x | 200-500ms | 85% | 低 | 月账单 6 位数 + 高并发撑不住 + 输出不稳定 |
| 3 级 fallback | 合理 | 混合 | 90%+ | 中 | 能上线 |
纯规则的死法有两种。意图体系小(10 个以下)时跑得飞快,准确率不高但凑合用;一旦扩到 30+,规则之间互相吞——"退鞋" 命中 product_inquiry 还是 return_request?同一句话两条规则都匹配,先后顺序里藏的判断没人讲得清。半年后规则总数破 100,工程团队接手新人看到 rules.py 直接申请离职。
纯 LLM 的死法有三种。成本:高并发场景每天 60 万次调用,按 qwen-turbo 单价 ¥0.002/1k token 算,月成本到六位数。延迟:意图分类是用户每发一句话都要跑的第一步,LLM 200-500ms 起步,加上后续 RAG 检索 + workflow 执行 + 生成,首字延迟到 2 秒以上,用户 SSE 流式那边看着就是「卡住」。稳定性:温度不为 0 时同一句话每次返回的意图不一样;温度为 0 时遇到 corner case 还是会幻觉(编个体系外的新 intent label)。
3 级 fallback 是工程上 only viable 路径——用最便宜的解决 60%、用稍贵的解决 30%、用最贵的兜底 10%,剩下的转人工。任何把这个比例做反的方案,要么成本失控、要么延迟撑不住高并发、要么准确率上不去。
成本-精度-延迟三角的一张表
下面这张表是接下来所有阈值调参的基准。打印贴墙上。
| 层 | 单次成本 | 单次延迟 | 准确率提升 | 覆盖率目标 | 失败模式 |
|---|---|---|---|---|---|
| Level 1 规则 | ≈ ¥0 | 1ms 以内 | baseline 70% | 60-70% | 规则之间互相吞 / 太宽误匹配 |
| Level 2 Embedding | ~¥0.0001 | 20-50ms | +10-15pp | 20-30% | 阈值低误匹配 / 阈值高漏召回 |
| Level 3 LLM | ~¥0.001 | 200-500ms | +5-10pp | 5-10% | 硬选 / 幻觉新 intent / 超时 |
| unknown 兜底 | n/a | n/a | n/a | 3-5% | 比例过低=硬猜,过高=体系缺失 |
3 个数字记住——60 / 30 / 10。这是 3 级 fallback 各层的目标覆盖率。
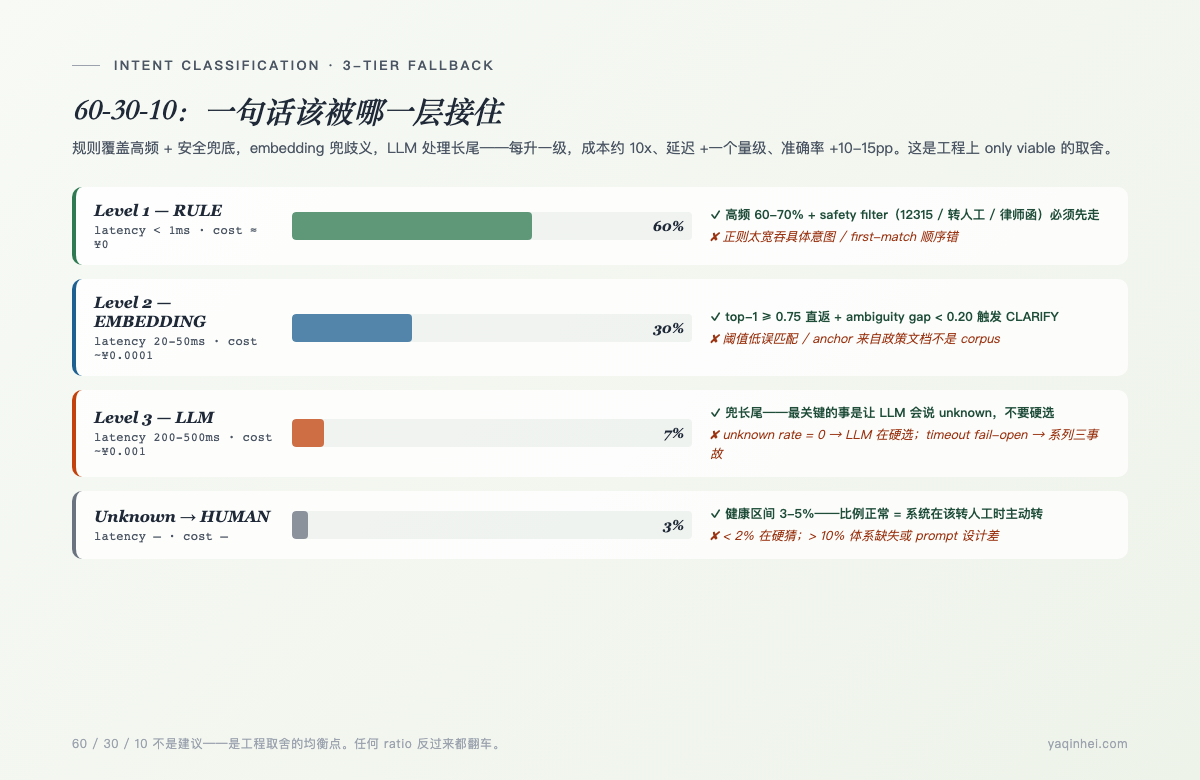
数字本身没什么神奇,神奇的是当你的实际分布偏离这个比例时,对应一定有一处工程问题——
- 规则覆盖低于 50%:意图体系扩张了但规则没补,要不要拆几个高频意图出来加规则
- 规则覆盖高于 80%:规则可能吞了具体意图("退鞋" 命中了泛 "鞋" 规则),要排查
- Embedding 覆盖低于 15%:阈值定得太高,或者高频用户表达跟 anchor sentence 差距太远
- Embedding 覆盖高于 40%:阈值定得太低,准确率会塌方
- LLM 覆盖高于 15%:embedding 没填好,把本该 embedding 解决的甩给了 LLM
- LLM 覆盖低于 3%:可能 LLM 阈值定得太严,或者 embedding 阈值太宽吞了 LLM 该处理的长尾
- unknown 高于 10%:意图体系里有空白,或者用户表达多样性远超你的标注集
这套监控信号是调参的方向盘。线上跑两周看分布,对照表往回调。
Level 1 — 规则层不是 low-tech,是工程上唯一保 "12315" 的兜底
规则层在评审会上最容易被嫌弃——「我们都 2026 年了还写正则?」——但规则层是整个 3 级 fallback 里唯一能给「合规高优先级意图」做硬兜底的层。
举个例子。用户说「再不解决我打 12315 投诉」「我要找消协」「这事我准备发抖音曝光」——这一类舆情高风险信号,绝对不能让它经过 embedding 或 LLM。原因有三:
- Embedding 召回不稳定——"12315" 的语义跟"消协"、"工商局"、"市场监管" 不近,向量空间里散得开
- LLM 偶尔会"理解错"——LLM 把"打 12315"理解成"打 12315 块钱",看过这种 bug
- 这一类必须毫秒级响应——延迟 200ms 给客户反应时间,舆情可能已经发出去
所以规则层的第一职责不是覆盖 60% 高频意图,是优先匹配 8-16 个 safety filter——
INTENT_RULES = [
# 第一组:safety filter(高优先级,永远先匹配,0.5ms 内返回)
("escalate_complaint", [
r"12315", r"消协", r"消费者协会", r"工商",
r"市场监管", r"投诉.*抖音", r"曝光", r"315",
]),
("human_transfer", [
r"^转人工$", r"^人工$", r"真人", r"客服小姐姐",
]),
("legal_threat", [
r"起诉", r"律师函", r"法院", r"违法",
]),
# 第二组:高频业务意图(覆盖 60-70% 日常对话)
("return_request", [
r"退货", r"退换", r"七天无理由",
r"我要退", r"怎么退", r"申请退",
]),
("refund_status", [
r"退款", r"退款.*多久", r"退款.*进度",
]),
# ... 8-12 个高频业务意图
]
规则设计有 3 条铁律,每一条都是踩坑换回来的——
铁律 1:first match wins,所以顺序决定一切。 safety filter 必须在最前面(哪怕你 99% 的对话用不上)。高频意图按"具体优先于宽泛"排:「退鞋」放在 return_request 里,再单独加一条 product_inquiry 兜底"鞋"——反过来 "鞋" 会吞掉「退鞋」。
铁律 2:正则不能太宽不能太窄。 太宽:r"退" 会命中"退伍"、"退烧药"、"打折促销退场"。太窄:r"我想申请退货" 只能匹配完整句子。合适的颗粒度:3-5 个高频表达 + 1-2 个变体——r"退货", r"退换", r"我要退", r"怎么退"。
铁律 3:短句要锚定。 r"^你好$" 匹配纯打招呼,r"你好" 会命中"你好吗我想退货" 然后被错路由到 greeting。锚定符 ^ $ 是这层的灵魂。
规则层做到这个程度,覆盖 60-70% 日常意图 + 100% 高风险舆情——是 3 级 fallback 整套架构的地基。
Level 2 — Embedding 层是 ambiguity 的安全网,阈值要分两个
规则 miss 的句子落到 embedding。这一层的核心不是 confidence 阈值,是 ambiguity gap。
什么是 ambiguity gap——同一句话跟 top-1 意图的向量相似度 0.78,跟 top-2 意图相似度 0.72。差距 0.06,你根本不应该返回 top-1,应该走澄清流程。
两个阈值要分开调:
def embedding_classify(query):
candidates = vector_search(query, k=3) # 返回 top-3
top1, top2 = candidates[0], candidates[1]
# 阈值 1: 绝对置信度
if top1.score < 0.70:
return None # 落到 LLM 层
# 阈值 2: ambiguity gap
if top1.score - top2.score < 0.20:
return IntentResult(
intent="needs_clarification",
candidates=[top1, top2],
ask_user=True,
)
return top1.intent
阈值 1,top-1 confidence,起步值 0.75。
- 0.75 以下基本是误召回,往 LLM 层推
- 0.75-0.85 是 embedding 这一层的甜区
- 0.85+ 几乎一定对,直接返回
调参方向:线上 embedding 直返的准确率低于 90% → 把阈值升到 0.80;太多句子被推到 LLM 层(LLM 覆盖率高于 15%)→ 降到 0.70。
阈值 2,ambiguity gap,起步值 0.20。
- gap < 0.20 → 反问用户(多候选 clarification flow)
- gap >= 0.20 → 直接返回 top-1
ambiguity gap 这件事很多团队不做,这是 embedding 层最大的隐藏 bug。看一个真实场景:
用户: "鞋子有问题"
top-1: complaint_quality, score=0.78
top-2: sizing, score=0.74 ← gap 只有 0.04
top-3: return_request, score=0.71
不做 gap 检查 → 强行返回 complaint_quality → workflow 路由到投诉处理 → 用户其实想说尺码不对 → 路错了,用户骂街转人工。
做 gap 检查 → 触发 clarification → 反问:"请问您是想反馈商品质量 / 尺码不合适 / 申请退货?" → 用户选了"尺码不合适" → 准确路由。
clarification 不是用户体验损失,clarification 是把用户体验从"被错路由然后骂街"换成"被反问一句然后顺畅完成"。线上 clarify-rate 调到 5-10% 是健康区间——低于 2% 多半是吞了歧义,高于 15% 说明意图体系本身边界不清。

Embedding 层另一件事:anchor sentence 的质量决定向量空间。每个意图准备 5-10 句"标准表达"(不是 SOP 文档,是真实用户说过的话),embed 后做 average pooling 作为 intent anchor。anchor 质量差,整层 embedding 准确率上不去——之前那个 1102 样本准确率 59.44% 的项目,就是因为 anchor 是从政策文档里挑的,不是从对话 corpus 里捞的。
Level 3 — LLM 层兜底,最关键的一件事是让它会说 unknown
规则没命中、embedding 也不确定,落到 LLM。这一层最关键的事情不是 prompt 写得多漂亮,是让 LLM 在不确定时返回 unknown,而不是硬选。
90% 的 LLM 意图分类 prompt 是这么写的:
你是意图分类器。可选意图:A, B, C, D。
用户消息:{message}
返回 JSON: {"intent": "X"}
这个 prompt 有个致命默认——它没给 LLM "我不确定" 的出口。LLM 收到一句它没法判断的话(比如「上周买的那个能不能那个」),它会硬选一个最像的返回。这种"硬选"的输出在监控里看不出来——log 里就是 {"intent": "return_request", "confidence": 0.6}——但实际上 LLM 是在猜。
正确的 prompt 必须包含三件事:
你是意图分类器。根据用户消息判断意图类别。
可选意图:
- return_request: 申请退货退换
- refund_status: 查询退款进度
- shipping_inquiry: 查询物流
- product_inquiry: 商品咨询
- complaint_quality: 投诉商品质量
- unknown: 无法判断 / 不在以上类别
规则:
1. 只返回 JSON: {"intent": "xxx", "confidence": 0.0-1.0}
2. 不确定时 confidence < 0.7
3. **完全不确定或不在意图列表里 → 返回 {"intent": "unknown", "confidence": 低于 0.5}**
4. 不要创造新的 intent 名
用户消息:{message}
关键设计:
unknown是一个 first-class intent——明确告诉 LLM "不确定时这是合法答案"- enum 严格约束——用 Pydantic / function calling / JSON schema 强制 LLM 只能返回列表内的 intent,否则解析失败重试
- confidence 分级——LLM 返回 0.7 以下的输出当 unknown 处理,不要相信"硬选"
线上 LLM 层 unknown rate 应该在 20-30%。低于 10% 说明 LLM 在硬选(你看的是假准确率);高于 50% 说明 prompt 设计差或意图体系本身有空白。
另外两件 LLM 层必须做的事——
Temperature = 0:意图分类是确定性任务,不需要创造力。temperature 0.5 下同一句话每次返回的 intent 都不一样,监控的统计意义就没了。
Timeout 必须 fail-closed:LLM 300ms 没回 → 走澄清流程或转人工,不要默认放行。原理跟 系列三 Critic fail-closed 一样——超时通常意味着服务降级,正是质量没保障的时刻,硬给一个 intent 比走 clarification 危险得多。
起步阈值一张表——下次评审会拍这张
把上面 4 节压成一张表。第一次上线 / 下次评审 / 内部 review,拿这张对一遍:
| 层 | 参数 | 起步值 | 调参方向 |
|---|---|---|---|
| L1 规则 | safety filter 数量 | 8-16 条 | 漏掉舆情/转人工类 → 加规则;维护到 30+ 条要警惕 |
| L1 规则 | 高频意图规则数 | 8-12 个意图,每个 3-5 条 pattern | 覆盖低于 60% → 看哪个高频意图没规则;高于 80% → 排查吞具体意图 |
| L2 Embedding | top-1 confidence | ≥ 0.75 直返 | 准确率掉 → 0.80;漏召回多 → 0.70 |
| L2 Embedding | ambiguity gap | < 0.20 → clarify | clarify-rate < 2% 太低(藏歧义);> 15% 太高(用户烦) |
| L2 Embedding | anchor 数 / intent | 5-10 句真实用户表达 | 从对话 corpus 捞,不是从政策文档 |
| L3 LLM | confidence 阈值 | ≥ 0.7 接受 | < 0.7 当 unknown 处理 |
| L3 LLM | temperature | 0 | 不需要创造力 |
| L3 LLM | timeout | 300ms | 超时 → fail-closed 走澄清 |
| L3 LLM | unknown rate 目标 | 20-30% | < 10% 在硬选;> 50% prompt 或体系问题 |
| 系统 | LLM coverage 目标 | 5-10% | > 15% 说明 embedding 没填好 |
| 系统 | overall unknown rate | 3-5% | < 2% 在硬猜;> 10% 体系缺失 |
11 个参数。这就是一份 3 级 fallback 上线前的全部调参点。
3 级 fallback 调到顶——下一步是 LLM Router,不是再调阈值
3 级 fallback 是起步架构。跑稳之后,有三个信号说明你已经撞到 v1 天花板:
- 意图体系扩张到 40+,policy 类("什么时候退款" vs "退款多久" vs "退款流程")占多数,每周都在改边界
- Embedding anchor tuning 跑了一轮又一轮,准确率边际收益跌到 +2pp 以下就不动了
- 用户多轮澄清需求越来越高——一句话不完整、需要反问"您说的是哪笔订单",但 v1 框架下没有自然的"反问入口"
这三件事任何一件单独存在还能调,三件同时出现 → v1 调参已经到顶,问题在意图模型本身,不在阈值。
这一年我跟过的一个项目走过这条路。v1 是经典 3 级 fallback:48 个互斥 intent + 31 个 policy intent + 17 个 action intent + safety filter。1102 样本准确率 59.44%。anchor tuning 跑了 4 轮,从 56.5% 提到 58.66%,再到 59.44% 就再也上不去。本质问题:「什么时候退款」和「退款多久」在用户语言里就是同一类问题,强行做成两个互斥 intent 是工程便利,不是用户视角。
v2 改成 LLM Router——LLM 把消息路由到 6 条主路径:
ACTION → 17 个 workflow intent 之一(退款/改单/查询/...)
POLICY → 直接进 RAG(不再用 intent label 过滤 KB)
SYS → 系统类(在吗/转人工话术/重启对话)
CLARIFY → LLM 反问澄清(一句话不完整)
UNKNOWN → 兜底(不在以上类别)
ESCALATE → 升级人工(舆情/合规/律师函)
ACTION 路径里 LLM 再选 17 个 workflow 之一,POLICY 路径完全不做 intent 分类——把消息直接丢给 RAG 检索 KB,相当于把 31 个人为的 policy intent 边界一笔勾销。这一步是关键,原因:policy 类用户问题边界本来就模糊,强行分类带来的不准确远多于带来的工程便利。
3 级 fallback 没有被废,只是各层职责重组:
| 层 | v1 HybridClassifier 里干什么 | v2 LLM Router 里干什么 |
|---|---|---|
| Rule | ~150 条规则(policy + action 都覆盖) | 收缩到 ~16 条,只做高频/资损 action 的 fast-path safety filter |
| Embedding | top-1 ≥0.75 直返 intent | 退出 policy 分类,仅在 ACTION 路径下做 workflow 内细分(可选) |
| LLM | 5-10% 兜底覆盖 | 主力,所有非 fast-path 走 LLM Router |
两套架构横着对比一遍:

| v1 HybridClassifier(3 级 fallback) | v2 LLM Router | |
|---|---|---|
| 意图模型 | 48 个互斥 intent | 6 条主路径 + ACTION 下 17 个 workflow |
| Policy 处理 | 31 个 policy intent + KB sub_topic 过滤 | POLICY 路径直接 RAG,不用 intent label |
| 模棱两可 | 硬选 top-1 → 路错 | CLARIFY 路径 → LLM 反问 |
| Rule 层 | ~150 条规则 | ~16 条 safety filter |
| LLM 角色 | 兜底(5-10% 覆盖) | 主力(所有非 fast-path) |
| 多轮澄清 | 不天然支持 | 天然支持 |
| p95 延迟 | 200-300ms | +200ms vs v1(关键路径多 1 个 LLM 调用) |
| 单 turn LLM 成本 | ~¥0.001 | ~¥0.005(5x) |
| 适用阶段 | 意图 30 个以内,corpus 还在演进 | 意图 40+,corpus 稳定,需要多轮澄清 |
升级到 v2 的代价:每个 turn 多 1 个 LLM 调用(qwen-turbo 这种轻量级模型 ~200ms),首字延迟从 ~600ms 升到 ~800ms(仍在 1 秒用户感知阈值内)。单 turn LLM 成本到 ~$0.0007——日均 1000 turn 的项目大约 $2/day,可忽略。
升级到 v2 的收获:
- policy intent 边界消失——31 个人为边界一次性删掉,让 RAG 自然检索
- 模棱两可可以由 LLM 反问澄清——不再硬选,UX 体感「更像在跟人聊天」
- Rule 维护面从 ~150 条收缩到 ~16 条——工程负担骤降
- 多轮上下文 + 用户历史 + 当前 query 综合判断——而不是单 utterance 硬分类
最关键的工程纪律:v2 不能直接切。新 router 必须跟旧 classifier 并行跑 shadow 部署——shadow router 写到独立的 Langfuse trace(按 session_id 与主 trace join),不影响产品输出。
为什么 shadow 用独立 trace 而不是主 trace metadata:handler.py finally 块 trace.end() 之后 OTel exporter 不接受写入;shadow LLM 调用 200-2000ms 跑得慢时 fire-and-forget task 写入会落空,而且偏向掩盖快路径的数据——这种偏差在统计上是致命的,会让你得出"v2 跟 v1 差不多"的错误结论。独立 trace 自管 end() + flush(),时序解耦。
Shadow 跑一周,按三个 UX 信号决定灰度——
- S1:v1 硬选 top-1 但 v2 走了 CLARIFY 的对话占比(v2 兜住了多少 v1 路错的场景)
- S2:v1 路错某个 workflow(用户后续转人工率高)但 v2 路对的对话占比
- S3a:异家族 LLM judge(Kimi / 火山等)对 v1 / v2 输出的偏好率,需要 30 条 calibration 集校准到 ≥70% 一致率
如果团队的客服 Agent 还在 v1,先把这一篇的 3 级 fallback 调参做扎实——意图 30 个以内 v1 完全够用,过早跳 v2 是钱白花。意图体系超过 40 + anchor tuning 收益跌到 +2pp 以下 + 多轮澄清需求强,三个信号同时出现,再考虑 v2。
Cache 是高并发能不能撑住的关键——不是优化项
如果你的客服 Agent 日均对话 > 5000 次,cache 不是优化项,是上线必要条件。
意图分类天生是 cache-friendly——很多用户的开场白和短问句是高度重复的。「在吗」「你好」「我要退货」「物流到哪了」这些表达,一个客服 Agent 一天可能见到上百次。每一次都打一遍 LLM = 烧钱。
# 一个最简 cache 设计
import hashlib
from redis import Redis
def cache_key(message):
# 简单 normalize: lower + strip + 去标点
normalized = message.lower().strip().replace("?", "").replace("?", "")
return f"intent:{hashlib.md5(normalized.encode()).hexdigest()}"
def classify_with_cache(message):
key = cache_key(message)
cached = redis.get(key)
if cached:
return IntentResult.from_json(cached)
result = three_tier_classify(message) # 3 级 fallback
if result.intent != "unknown": # 只 cache 确定结果
redis.setex(key, ttl=86400, value=result.to_json())
return result
Cache 命中率到 30-50% 时,整体成本掉一半,p95 延迟掉 2/3。三件事要注意:
- 只 cache 确定的结果:unknown / clarification 这些不要 cache,否则用户每次都被反问
- TTL 不能太长:意图体系会演进(v1 36 个 → v2 48 个),cache 不能跨版本污染。1 天 TTL + 体系变更时显式 flush 是稳的
- 不能 cache 写操作上下文:cache 只对"判断意图"安全,不能 cache "调用哪个 tool 用什么参数"
实测一个数字:日均 1 万对话的项目接 cache 之前 LLM 月成本 ¥8000,接 cache 之后 ¥3500——命中率 45%。
5 个红灯信号——评审会上一票否决
下次乙方介绍意图分类方案时,5 个红灯——
信号 1:「我们直接用 LLM 分类,简单可靠」。问他高并发月成本 + 有没有 safety filter + 有没有 shadow 验证——三者都答得上来 = 可能在做 v2 LLM Router(合理);只说"调 LLM 就完事"= 上线 1 个月内大概率账单事故 + 舆情 fast-path 漏放。LLM Router 跟"裸奔 LLM 分类"差的就是这三件事。
信号 2:「我们 100% 用规则,绝对可控」。问他意图数现在多少,规则总数多少——意图 > 30 而规则 > 80 = 已经在维护地狱,下一波团队接手会推翻重做。
信号 3:「embedding 阈值我们设 0.5 直接返回」。0.5 在向量空间里几乎是噪声水平——大部分相似度都 > 0.5,等于没设阈值。这种方案准确率比纯规则还差。
信号 4:「LLM unknown rate 是 0」。等于 LLM 在硬选。问他「LLM 怎么处理它不认识的句子」——答「会返回最相近的」就是这个问题。
信号 5:「我们没做 cache」。日均 > 5000 对话的场景一定要做。没做 = 成本是命中率倒数倍数。
5 个里出现 1 个 → 方案有重大返工;出现 2-3 个 → 这个方案上线后跑不久;出现 4+ → 直接拒掉,让乙方拿回去重写。
11 件这周可以做的事
- 把 Agent 现在的意图分类逻辑画出来——是 3 级 fallback 吗?哪一层缺
- 跑一次 baseline——1000 条真实对话上各级 coverage 是多少,对照 60/30/10
- 给 fast-path 加 8-16 条 safety filter(12315 / 转人工 / 消协 / 律师函 / 曝光 必走规则)
- 给 embedding 加 ambiguity gap clarify branch(top-1 与 top-2 差距小于 0.2 → 反问)
- 给 LLM prompt 加
unknown出口和 enum strict(Pydantic / function calling schema) - 把 LLM temperature 设 0,timeout 设 300ms,timeout → 走澄清不要硬选
- 把高频用户原话的分类结果 cache 起来——同句直返
- 把每次分类的 source(rule / embedding / llm / cache)打到日志,每天看分布
- 给每个意图加准确率监控(用 LLM-as-Judge 异家族模型校)
- 准备好 fallback:LLM 超时 / 错 / 低置信 → 升级人工或反问,不要硬猜
- 评估 v1 → v2:意图数现在多少 / anchor tuning 边际收益 / policy 边界改动频率 / 多轮澄清需求强不强——四项都达 v2 升级门槛 → 启动 shadow 部署评估,否则继续把 v1 调参做扎实
6 个评审问题——下次乙方说"意图准确率 90%"时问回去
问题 1:「3 级各占多少?」 合格答案:60/30/10 左右。答"只有 LLM" / "只有规则" → 红灯。答"我们没分层" → 大红灯。
问题 2:「embedding 阈值多少,ambiguity gap 怎么处理?」 答不出 / < 0.7 / 不做 gap → 准确率不达标。合格答案:top-1 ≥ 0.75 直返 + gap < 0.20 反问。
问题 3:「LLM unknown rate 是多少?」 答 "0" → LLM 在硬选;答 "20-30%" → 正常。这是最简单也最有杀伤力的一问——大部分供应商的 PPT 上甚至没有这个指标。
问题 4:「意图 cache 命中率?」 答"没做" → 月成本会爆。合格答案:30-50% 命中率 + TTL 1 天。
问题 5:「90% 准确率是怎么算的——抽样多少 / 用什么 judge / 包不包含 unknown?」 这一问是从系列五解决率和系列七双轨测试里来的——没有可解释的 90% 等于没有 90%。合格答案:每周抽样 200-500 条 + 异家族 LLM judge + 校准集 + unknown 单独算召回。
问题 6(进阶):「v1 还是 v2 架构 / shadow 怎么跑」。问他用的是 HybridClassifier 还是 LLM Router、shadow 部署用主 trace metadata 还是独立 trace、shadow 跑了多久、用哪些 UX 信号判定灰度。答"我们没 shadow 直接切"= 高风险;答"shadow 写在主 trace metadata 里"= 统计偏差致命,结论不可靠。合格答案:独立 trace + 一周以上 shadow + 至少 2 个 UX 信号 + 异家族 judge 校准。
写在最后:意图分类是地基,地基塌了上层全垮
这一年我见过太多客服 Agent 项目,模型用最贵的、prompt 写得最长、RAG 套了 3 层 rerank——第一步意图分类做错,后面所有努力全白费。
意图分了错,workflow 路由就错,Critic 审查的是错路径上的动作,写操作打到错的 tool,监控指标看上去全是绿的——但用户那头每次都被路错。
意图分类的工程价值不在算法,在工程取舍——用 60% 高频规则省成本、用 30% embedding 兜歧义、用 10% LLM 处理长尾。三个数字、11 个调参点、3 条不该走的死路。
如果团队方案是「直接用 LLM」「100% 规则」「embedding 0.5 直返」「LLM unknown 0%」「没做 cache」这五个里的任何一个——把这一篇拍他脸上,让他重写。
工具包领取
如果你想把这一篇里的工具立刻用到下次评审会 / 团队意图分类调参,我整理了一个 PDF 工具包:
回复关键词「意图三角」,我把工具包发给你:
- 3 级 fallback 调参表(11 个参数 + 起步值 + 调参方向)
- 5 红灯信号 + 6 评审问题(评审供应商方案专用,含 v1/v2 架构评估)
- Safety filter 8-16 条 starter pack(中文客服场景已填好)
- Embedding ambiguity gap clarification flow 模板(含反问话术)
- LLM 意图分类 prompt 模板(含 unknown / enum strict / fail-closed timeout)
- v1 HybridClassifier → v2 LLM Router 升级评估清单(4 个升级信号 + shadow 部署 checklist + UX 信号定义)
这一年跟项目里收敛出来的调参手册,送给读到这里的你。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
系列接下来排期
A4 系列下一篇——
- LLM 接入企业 SaaS 生态:25 API → 5 tool 的契约和幂等性(系列二决策 4 深挖)
- 中文意图体系演进:从客服话术 corpus 到 codebook 的迭代方法论(v1 36 → v2 48 的真实演进,配 v2 LLM Router 上线 shadow 部署的实战)
- 企业 LLM Agent 踩坑合集:async ES 阻塞事件循环 / Critic timeout fallback 误用 / proxy 拦 localhost / intent rename 跨 7+ 文件 / KB-ES 不同步
如果团队正在做 L2 客服 Agent 或别的需要意图分类的写操作类 Agent,这 3 篇接下来一篇一篇出。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.