How Much to Label: Not a Percentage of Traffic, but "Label Until You Can Conclude"

Post #2 of the After Launch series. The previous post, After Launch Is Where Agent Architecture Is Decided, covered which rows to draw — stratified sampling, over-sampling the risk layer past 30%. This one answers the other half: for each cell, how many rows is enough. 中文版:标多少条才够?不是流量的百分之几。
Given your live traffic, how many rows does an agent need labeled to be enough?
Most people's first instinct is a proportion — "5% of traffic," "200 a day." That answer is wrong from step one.
The scene. In a review meeting, someone reports: we labeled 50 rows on this intent, 96% correct, ready to ship? The number looks great; no one in the room objects.
But 96% out of 50 has a statistical lower bound of only about 86%. In other words, you have no confidence it actually hit 90% — it just looks like it did. A small sample's point estimate lies: the fewer the rows, the wider the gap between that pretty percentage and the true level behind it — and that gap sits exactly in the rows you didn't label.
The right question isn't "how many did you label, what's the accuracy," but "have you labeled enough to draw a conclusion against the launch threshold." And what decides that volume isn't traffic — it's three other things: how good the agent truly is, how many intents you have, and how many channels it runs on. Get those three straight and you reach a counterintuitive conclusion: double the traffic, and the amount you need to label barely moves.
50 rows at 96% can't ship — a small sample's point estimate lies
An accuracy number has two readings: the point estimate (that 96%) and the confidence-interval lower bound (the line you're confident you're not below). What you ship on is the lower bound, not the point estimate.
Why? Because the point estimate is a function of luck. 48 right out of 50 is 96%; but if two of those were right by chance, the true level might sit around 86%. The smaller the sample, the more room for that "by chance." Reading the lower bound strips the luck out — it answers "in the worst case, am I still at 90%," not "what score did this particular batch happen to get."

Same 96% point estimate: at 50 rows the lower bound is ~86%; to push it past 90% you'd label ~140. Whether you're above the threshold depends not on your score, but on how many questions you sat.
That gives you a this-week move: whenever someone brings an accuracy number to request launch, ask one thing — is this a point estimate, or a confidence-interval lower bound? "It's just what we got from labeling N rows" means the number has no standing in a launch decision; someone who can't say the word "lower bound" tells you the team doesn't yet have the "small samples lie" concept.
How much to label depends on how good the agent truly is — a table that "explodes"
Put the conclusion on the table first: how much to label isn't a fixed number you pick — it depends on how well the agent actually does on that intent, and the closer to the threshold, the more the required sample size explodes.
Across the customer-service agent projects I've run this year, the table I keep reaching for (threshold = "accuracy lower bound clears 90%"):
| Agent's true accuracy on the intent | Rows to label / intent | Read |
|---|---|---|
| 100% | ~35 | very cheap |
| 98% | ~53 | cheap |
| 96% | ~84 | acceptable |
| 94% | ~204 | expensive |
| 92% or below | 700+, or never passes | stop labeling — fix the agent |
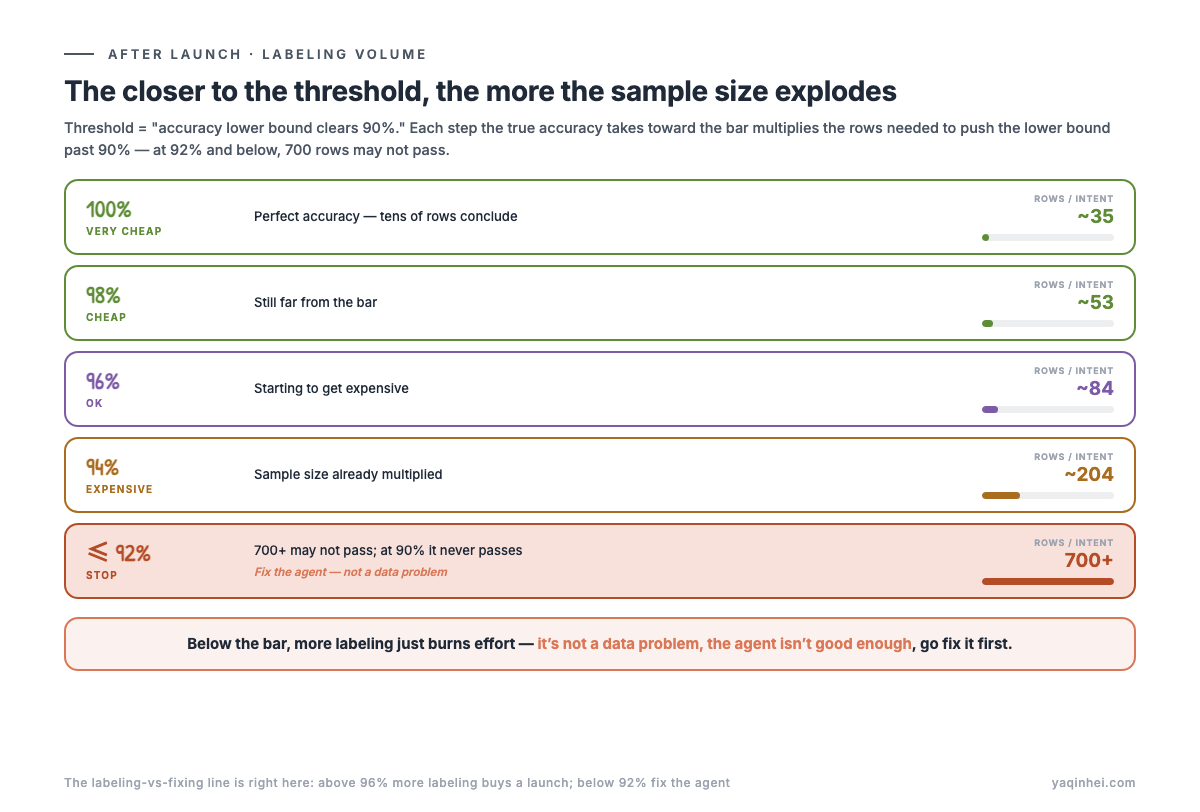
The key insight is in the last row. At a true accuracy of 92%, 700 rows might not push the lower bound past 90%; at exactly 90%, it mathematically never passes. Here the confidence interval isn't being difficult — it's honestly telling you one thing: it's not that you lack data, it's that the agent isn't good enough; labeling more is wasted, go fix the agent first.
This line divides labor between "labeling" and "fixing the model": near the threshold (96% up), more labeling buys you a shippable conclusion — worth it; below it (92% down), more labeling just burns effort on an intent that will never pass. A healthy admission process should call a stop right here, not let the labeling team grind forever.
Labeling volume grows with "intents × channels," not with traffic
This is the most counterintuitive — and most money-saving — point.
In the proportional mindset, double the traffic and you double the labeling — 1,500 for 3,000 conversations, 3,000 for 6,000. But that's not the right way: you label each intent until you can conclude, and the volume needed to conclude (tens to a bit over a hundred rows) is almost independent of that intent's total traffic. Whether an intent gets 100 or 10,000 conversations a week, pushing its lower bound past 90% needs the same ~70 to 150 rows.
So the real formula is: total labeling ≈ number of intents × number of effective channels × rows-per-cell to conclusion. Double the traffic and each cell still needs the same rows; total barely moves. What actually raises the labeling load is opening a new intent, or launching a new channel — that means a fresh batch of cells, each needing its own sample.
Why does the channel count as a dimension? Because the channel is a real variable in accuracy — different channels have different KB sources, policy definitions (exchanges, shipping insurance, small refunds), and retrieval quality, so the same intent can have different correct answers across channels. Report two channels merged into one number and the high-traffic channel dilutes the low-traffic one's problems by weight — the total looks past 90% while one channel is quietly crashing. So each channel must be framed and judged on its own.
The budgeting implication for leadership is direct: don't estimate from "DAU doubled, do we add labelers." Ask instead — how many intents did this version add, how many new channels? A new channel is roughly a fresh batch of cells to fill from scratch, not the existing labeling load spread thinner over more traffic.
Two tracks: full-census the risk layer, label the consult layer to conclusion
Down at the track level, the discipline differs:
- Risk track (refund, cancel, address change, intercept…): full census, no sampling, cap 150 per cell. These move real money, zero tolerance — one wrong call is a loss; luckily their volume is small, so full labeling is cheap. Trade "zero sampling error" for "not one missed" — worth it. This is the risk layer from the previous post, expressed as labeling volume.
- Consult track (sizing, logistics, invoices, promotions…): label until the Wilson lower bound clears 90%, then stop; at 150 rows still not clearing, stop and report "agent needs work." High volume, but tens of rows per cell represent the whole; stop once you can conclude, don't waste.
Plus three rules you don't break:
- The unit is "intent × channel," not "intent." Sizing on channel A and sizing on channel B are two cells, counted and gated separately.
- A floor of 30 rows — a cell under 30 rows shows no metric, marked "accumulating"; wait a few weeks. Below that, any percentage is noise.
- A cell whose weekly traffic is below the rows it needs can only full-census what it has, no forcing it; a small new channel needs an upstream per-channel quota, not a hope that total traffic trickles down to it.
Three things you can do this week
- Kick "point estimate" out of launch decisions. Next time someone requests launch with an accuracy figure, ask "is this a point estimate or a confidence-interval lower bound?" — accept only the lower bound; ready means the lower bound clears the threshold.
- Change the admission unit from "intent" to "intent × channel," set a 30-row floor. Don't change definitions, just the counting: each intent×channel counted and gated on its own, cells under 30 shown as "accumulating," never a merged number papering over the gate.
- Bring the "true accuracy → rows to label" table into the review meeting. Make "how much to label" a data-driven process that calls a stop near the threshold — not a fixed number pulled from the air, or labeling until no one has energy left.
Back to the opening question. "How many rows is enough" stumps people because most treat it as a traffic problem, when it's really a "how confident are you" problem. Tie labeling volume to "label until you can conclude against the threshold" and you get three things at once: saved effort, an honest launch gate, and a signal that proactively tells you "stop labeling — go fix the agent."
The next post covers the link in this mechanism most easily dismissed as grunt work, and yet is the ground truth — labeling itself: who labels, how, and when two people disagree on the same row 30% of the time, whether your "answer key" still counts at all.
If this turned "how much to label" from a gut call into a table that calls a stop, send me the keyword "VOLUME KIT" and I'll share the "true accuracy → rows to label" table plus the two-track sizing template.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.