After Launch Is Where Agent Architecture Is Decided — Start With How You Sample Your Eval Set

Post #1 of the After Launch series. Agentic AI in Practice is about building an agent and shipping it; this new series is about what comes after — sampling, labeling, evaluation, and the feedback loop that keeps an agent right. It is the biggest blind spot in today's enterprise agent market, and the hardest thing to paper over with a demo. This first post starts with the least glamorous step, the one where the gap shows first: sampling. 中文版:上线之后,才是 agent 架构的分水岭。
You think the stronger AI gets, the fewer people you need? The opposite is true.
Where agents are being built with real money, labeling and evaluation teams are growing, not shrinking. China's AI foundational-data-service market grew at roughly 47% CAGR from 2019 to 2025, reaching 95,000 professional annotators by end of 2025 — and demand is moving fast from assembly-line tagging up to high-end evaluation roles like "AI question-setting expert" and "vertical-domain data specialist," with Alibaba, ByteDance, and DeepSeek paying a premium for them. In late 2025, VentureBeat put a name on the trend: evaluation is replacing traditional labeling as the critical path to production.
Top labs are growing thousand-person eval teams against the tide — because launch is where labeling actually begins.
And most enterprise projects? They ship and abandon.
What sits in between is a full generation of missing sense. It shows up most starkly in the most ordinary thing: how companies "improve" an agent that's already live.
Across the customer-service agent projects I've worked on this year, the default move — whether from a vendor or an enterprise's own architects — is nearly identical: there's a backend page showing production conversation logs; every so often you scroll through, spot an answer that's off, decide the wording could be better, and edit it. Add user thumbs-up / thumbs-down as the signal for whether the agent is good. Intuitive, agile, feels like continuous iteration.
But nothing in that loop is evaluation.
"Read the logs, edit the wording" feels like progress — it's whack-a-mole
Andrew Ng has taught error analysis for over a decade, and its core is one line: don't tune by feel — take a sample of the errors, categorize the failure modes, and rank which class to fix first by its share. None of that exists in the "read logs, edit wording" loop.
No sampling, so which rows you happen to read is down to luck and mood — a good day, twenty more; a busy week, none; where the sample came from and what it represents, nobody can say. No failure-mode grouping, so you fix one line of wording, not a class of error — how many of the same root cause are still wrong under other intents, you don't know. Thumbs-up/down is worse still: the users who bother to rate aren't random (the angry and the fully-satisfied rate), and out of a thousand conversations you might get a few dozen ratings — biased and sparse.
Stack those three together and you get this: you think you're iterating, but you're playing whack-a-mole — you fix the one in front of you, with no idea how many of the same class are still out there, and no idea whether the change made the whole thing better or worse. Without a fixed eval set as a baseline, you don't even have standing to say "this improved" — you've just made the current log stop stinging.
And the deficit isn't only after launch. Look upstream: the same people build intent recognition by wiring an LLM straight in as the router, rather than a layered intent architecture (rule → embedding → LLM → unknown). The "build it" half and the "keep it right" half share one underlying flaw:
treating the agent as an LLM you can poke and patch, rather than an architecture you can measure and systematically improve.
That is the real gap between agent architecture and today's enterprise agent market — not how strong the model is, but whether you have a mechanism that measures the agent honestly. And the first brick of that mechanism is the step almost nobody takes seriously: sampling.
The first step isn't reading logs — it's sampling. But random sampling is trap #2
Going from "read logs" to "sample" is going from 0 to 1. Most teams are still at 0: they look at conversations they happened to scroll past, or ones a thumbs-down pushed to the top — not a defined sample. As long as your eval sample is "found" rather than "drawn," you're forever measuring the part that drew attention, not the part that actually happened.
But even if you're already ahead of the market and sampling at random, random sampling is itself a trap.
The reason is that production traffic is extremely long-tailed. A customer-service agent handles tens of thousands of conversations a day; ~90% are read-only queries like "where's my order" and "how do I return this." The ones that get someone out of bed at 2 a.m. are the few money-moving writes — refund, cancel order, change shipping address, intercept a shipment. Those high-risk requests are often just a fraction of one percent of daily traffic.
In a random sample of 200, the expected number of such cases is 0 to 1.

So you compute a respectable number — say 96%. But it measures almost entirely the part the agent is least likely to get wrong: the common, read-only, money-free conversations. And the risk that actually keeps you up — one wrong refund, one mishandled compliance case — its true error rate sits, whole and untouched, in the hundred-plus rows you never sampled.
An eval metric's credibility is capped not by the model, but by the sampling frame. Skew the sampling and every downstream number — accuracy, satisfaction, automation rate — is a pretty figure computed over a quietly hand-picked, safest subset. Random sampling looks the "fairest," and it's precisely that fairness that dilutes the rarest, highest-stakes events into statistical noise.
Good sampling is a layered frame, not one scoop of random
Put the conclusion on the table first: don't sample the eval set by traffic share — reweight it by the cost of getting it wrong. Common, low-risk intents get a token slice; rare, money-moving intents get deliberately over-sampled, so their share in the eval set is far higher than their share of live traffic.
A workable stratified frame cuts at least these layers:
- Risk layer (must over-sample) — pull out the money-moving, compliance-touching, irreversible writes. On my projects I reused the "asset-impacting action intents" list directly: refund, cancel order, after-sales cancellation, change shipping address, edit return number, nudge shipment, intercept logistics — seven writes. They're a fraction of a percent of live traffic, but I give them 30%+ of the eval set. The reason is simple: one wrong refund does not cost the same as one wrong "where's my order," so why would evaluation be split evenly by traffic.
- Uncertainty layer — where the agent's own confidence is low, the Critic flagged it, or it hit fallback. These are the spots the model itself raised its hand on; error density is highest here.
- Disagreement layer — if you have dual agents or a Critic, the samples where the two verdicts conflict are nearly all worth a human look.
- New / OOD layer — landed in unknown, phrasing never seen before. These signal that the intent taxonomy should evolve, and they're the easiest future risk for "random sampling" to miss.
- Routine layer (random) — the big remainder; a small random slice as a baseline, just to prove the common scenarios haven't regressed.
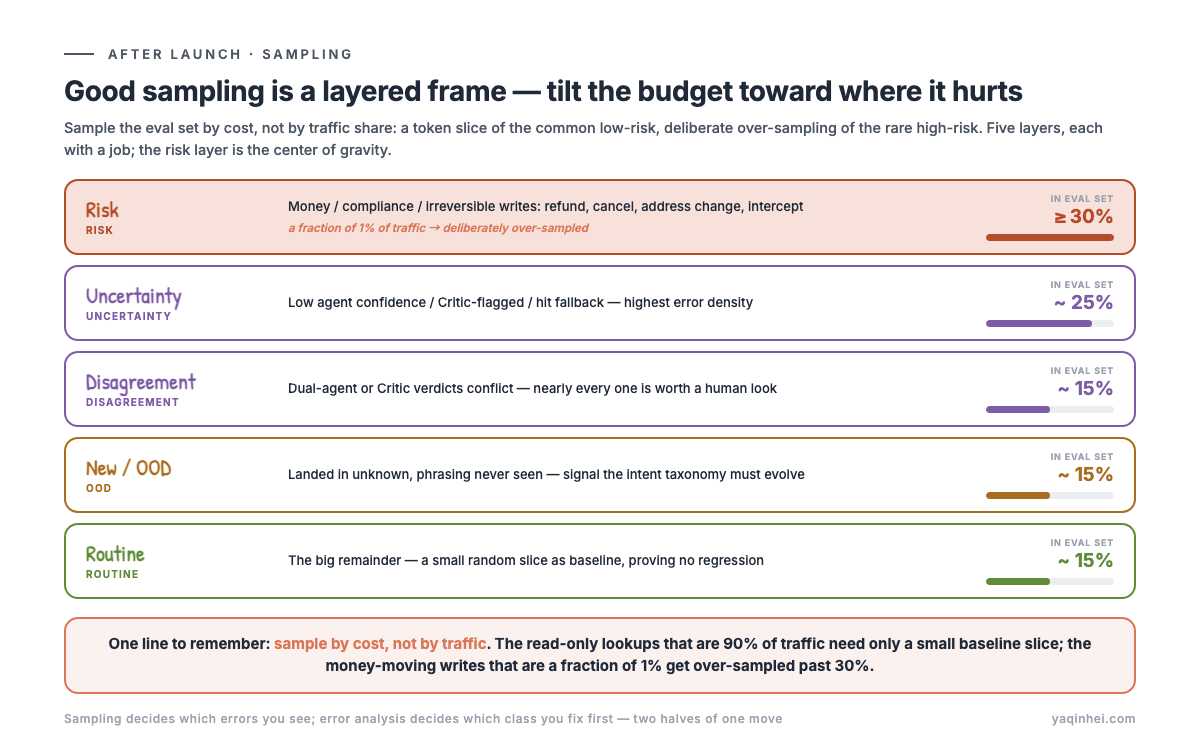
The essence of this frame is shifting a finite labeling budget from "spread it evenly" to "tilt it toward where things break." It and error analysis are two halves of one move: sampling decides which errors you see; error analysis decides which classes of root cause you distill from them and which to fix first.
One kind of sampling must stay hidden from the agent
Almost no one thinks of this layer, but it's what separates evaluation from gaming the score.
The moment the agent — or the vendor — knows which samples get audited and scored, evaluation gets optimized to please the audit set rather than to do the job right. This isn't conspiracy; any measured system drifts toward what's measured. If every evaluation pulls the same intents and the same channels, over time the optimization presses exactly where it's watched, while the unwatched corners keep rotting.
This is reward hacking in the evaluation stage: you think you're testing capability, but you're testing "exam performance against a known question bank."
So two operating disciplines: the specific samples must rotate and carry randomness — don't let them be predictable; and the risk layer must be injected unannounced into live traffic as a blind test. The eval set can be a public method, but not a public question bank.
Three things you can do this week
No project charter, no budget needed — usable at your next review meeting:
- Ask one question that exposes the eval set. "Is our production eval set drawn or found? For high-risk intents like refunds, is it sampled by real proportion, or over-sampled?" An answer of "we read the logs" or "we grab a random batch" means evaluation is still at the whack-a-mole stage; no answer at all means the number has no sampling frame behind it and shouldn't enter a decision.
- Add a risk layer to the eval set. List the money-moving, compliance-touching write intents in your project and over-sample them to 30%+ of the eval set on their own. No new tooling required — just change "sample by traffic" to "sample by cost."
- Build a fixed baseline set before you talk about improvement. Before editing any wording, freeze a risk-layer-inclusive eval set as the baseline. Re-test every future change on the same set — it's the only way to honestly answer "did this actually improve anything." Replace "fixed the one in front of me" with "did the baseline go up overall."
Back to the gap we opened with. Why do top labs grow thousand-person eval teams as AI gets stronger? Not because they have money to burn, but because they figured out one thing long ago: the model only sets the agent's ceiling; sampling, labeling, evaluation, and feedback are the mechanism that decides whether it slides downhill after launch. Launch isn't the finish line — it's where labeling begins.
Sampling is the first brick. The next post covers the second — labeling itself: who labels, how, and when two people disagree on the same row 30% of the time, what your ground truth even is.
This "after launch" architecture is the biggest blank in today's enterprise agent market — and the hardest thing to paper over with a demo.
If this turned your eval set from "scroll the logs" into a stratified sampling frame, send me the keyword "SAMPLING KIT" and I'll share the stratified-frame template plus the 3-question review-meeting checklist.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.