Your Labels Are Your Ceiling — One "Swap Half a Size Up" Gets Three Answers From Two Agents
Post #3 of the After Launch series. The first two covered which rows to draw and how many to label. This one digs a layer under both — whether the "right / wrong" you labeled is even reliable. 中文版:标注是 ground truth——「换个大半码」这一句,两个客服能标出三个答案。
The first two posts taught you to draw the eval set right and label each cell deeply enough. But all of it rests on one premise: that the "right / wrong" you labeled is itself reliable.
What if it isn't?
This year, running a customer-service agent project for a footwear-and-apparel retailer, I ran a very plain experiment: I took 50 conversations from one intent, already labeled "right / wrong," and had another equally skilled agent re-label them back-to-back. The two agreed on only 35 — on the other 15, one said right, the other said wrong. And those 15 clustered on one kind of conversation: returns labeled cleanly, but the moment it was an exchange or a price-difference refund, the two split.
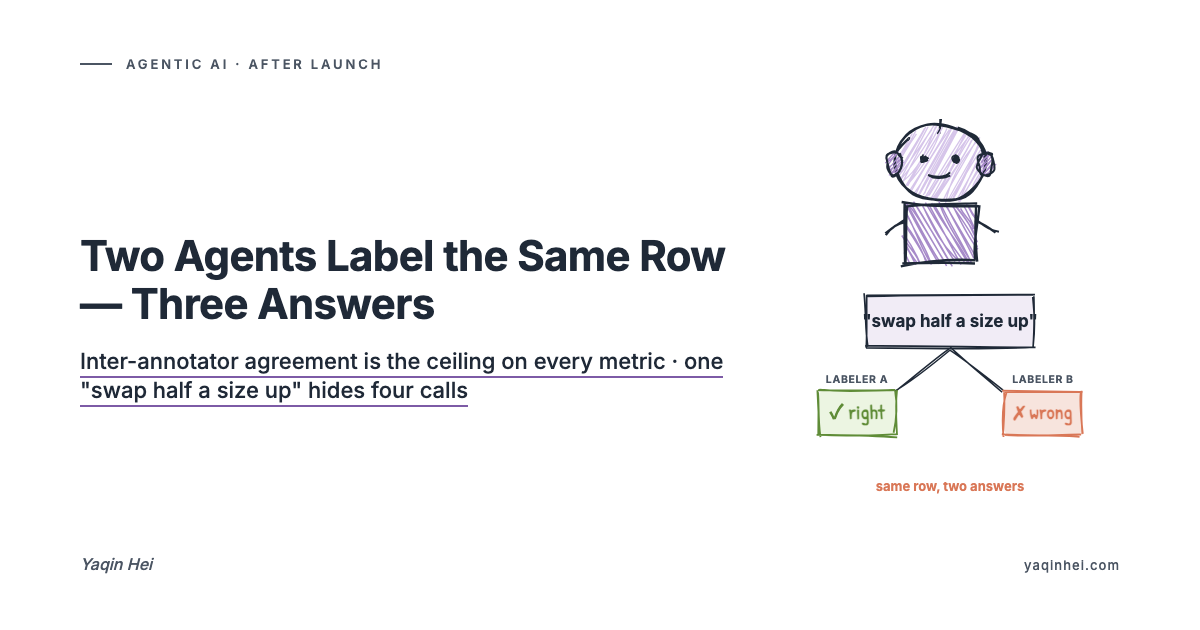
Here's the most telling one. The customer says: "I bought these running shoes last week, I want to swap half a size up." The agent replies cleanly: "Sure, I can swap it — please share your order number."
That one exchange produced three answers from the labelers:
- A marked "right" — the customer wants a size swap, the agent caught it, flow correct.
- B marked "wrong" — the customer bought at a 599 promo price last week; that size's promo has ended, it's 799 at list now, so the swap costs the customer 200 more. The agent said nothing about the difference; when the customer gets a payment-top-up link, they'll complain.
- C marked "unsure" — you'd have to know whether it's shipped first: if shipped, it should be a return-and-rebuy; if not, a shipment interception plus cancel. The "swap" the customer said might be the wrong path entirely.
One sentence, three answers, and not one is the labeler's fault. What's wrong is that this conversation's "answer key" depends on three things the labeler can't even see in the conversation: shipment status, the customer's paid price, and whether this channel has price protection.
Labeling is the ground truth of your whole evaluation system. Once it's unreliable, everything above it — accuracy, satisfaction, automation rate, the confidence-interval lower bound you sweated over last post — collapses. And this foundation is precisely the link most treated as grunt work, most easily outsourced to "whoever's free."
Two people disagree 30% of the time — you have no answer key
Measure inter-annotator agreement before you talk about accuracy — agreement is the ceiling on every metric you have.
The agent's "accuracy" is measured against labels as the answer key. On "swap half a size up," two skilled people can't align, which means a whole block of the "answer key" is ambiguous — whatever the agent answers on those cases, you can't judge it right or wrong. So the ceiling on your measured accuracy is the agreement rate itself. Measure "180" with a ruler whose marks wobble and the number is meaningless — not because no one measured, but because the ruler isn't fit for it.

A this-week move: before any accuracy number goes anywhere, have two people label the same 50 rows back-to-back and compute agreement. Below ~85%, that number has no standing in a launch decision — fix the ruler first. Most teams have never done this step — they assume "labeling = objective fact," grab whatever one person labeled as ground truth.
Those 15 disagreements: half rubric debt, half genuinely hard cases
30% disagreement isn't noise, it's a diagnosis — it tells you where the split comes from, and the two sources need completely different handling.
In "swap half a size up," "which price the difference is refunded against" is rubric debt — not mysticism, a rule that should have been pinned down and wasn't. Paid price, current price, list price, member price — which is the baseline? Should it be refunded, how much? Pin this down and B's kind of disagreement vanishes on the spot.
But "did that sentence catch the customer or just push them away" is genuinely on the boundary — it straddles both "containment rate" and "resolution rate" (the architecture argument from post #5 of this series). This kind resists even a clear rubric; it needs an adjudication process, not more rubric-polishing.

The most common anti-pattern is averaging the two answers, or "majority rules," to paper it over. That uses statistics to hide "you haven't yet defined what counts as right." Disagreement is killed either in the rubric or in adjudication — never in an average.
The rubric is code: pin down "which price the difference is against"
The answer key isn't "self-evident" — it's a written, versionable rubric. Labeling by feel means everyone carries a different ruler in their head.
For the price difference, a usable rubric rule looks like this:
Price-difference baseline = the customer's order paid price, compared to the same SKU's current purchasable price; refund only when the delta is positive. When an exchange involves a different SKU, compute against the new SKU's current price minus the original paid price; the customer tops up / is refunded that delta. Private-domain members within the price-protection window are protected at paid price; public-domain platforms without a price-protection policy transact at current price, no difference refund applies.
Pin this down and B's kind of disagreement goes to zero. "Everyone knows what counts as right" is the costliest illusion — three people label, three rulers in three heads, agreement never rises, and you can't even locate why. The rubric is writing "what counts as right, where the boundary is, what the unit of judgment is" as explicit rules — code that can be read, reviewed, changed.
Even the unit of judgment has to be pinned: is one whole conversation a decision, or a single message (Andrew Ng's line — the unit of evaluation should equal the decision unit you actually care about; a customer's one conversation is one business decision, and "let me take a photo for you" mid-way doesn't spawn a new judgment point).
And the rubric evolves: hit a new case, add a rule. But — change the rubric and old labels may become invalid. The moment you add "exchanges compute the delta against the new SKU's current price," the batch of exchange conversations previously labeled "right" under the old rule has to be re-judged against the new version. So the rubric must be versioned; each change flags clearly which old labels need re-labeling (the flip side of last post's "per-scenario version cut" — a scenario whose standard changed can't keep its old data in the denominator).
Detection move: ask "which document, which version, is our labeling rubric?" An answer of "not written, the veteran agents just know" means your ground truth lives in individual memory — one person leaves and the standard scatters.
"How much" — the labeler has no standing to define "right"
Not every intent's "right" can be handed to a labeler — for money-touching and compliance intents, the rubric's author must be the business owner.
One project retrospective stuck with me: the business owner glanced at that "swap half a size up" conversation and the first thing said was — "Has this shipped? Bought at promo, swapping to a list-price size, they owe 200 and the agent said nothing — of course the customer blows up when the top-up link arrives." Only then did the room realize: the labeler, start to finish, didn't know the shipment status, didn't know what the customer paid, didn't know whether this channel had price protection. They didn't mislabel — we asked them to judge something they held no cards for.
The answer to "how much is right" sits in a table the labeler can't see: paid price, SKU current price, price-protection window, channel policy. Handing a generic labeler the job of defining a price-difference's right/wrong hands the most expensive judgment to the person least equipped for it — and you can't even catch the error, because the ruler is as clueless as the thing it measures. Price differences, whether an exchange keeps the coupon, at what state a shipment interception fires, whether this compliance line can be said to a customer — the answer keys all live in business policy. This is exactly why data-labeling roles are moving upmarket ("AI question-setting expert," "vertical-domain data specialist"): defining ground truth needs domain authority, not assembly-line labor.
Adjudication is the same: when two split on an exchange / price-difference case, the call belongs to the business owner, and the ruling is written back into the rubric as precedent. Adjudication isn't "who's right on this one," it's "here's how this whole class gets judged from now on."
Detection move: have the business owner sign off on the rubric for money-touching intents. A money-touching "answer key" without the business owner's signature doesn't count.
Three things you can do this week
- Label 50 rows back-to-back, measure agreement. Pick the most-argued intents — exchange / price difference — have two people label the same 50 independently, compute agreement; below ~85%, fix the ruler before talking about the agent.
- Write the most-argued cases into the rubric. At minimum pin down: which price a difference is against, whether an exchange is a return-and-rebuy or a shipment interception (by shipment status), whether tossing a self-service link counts as catching the customer. Version it on change, flag which old labels need re-labeling.
- Get the business owner to sign the rubric for money-touching intents. Price difference, exchange, shipment interception, compliance lines — "right" is defined by the business owner; disagreements are adjudicated by them and written back as precedent.
Back to that 96%. It's untrustworthy not because the agent is bad, but because the ruler measuring it was never calibrated. The model decides how well the agent can do; the labels decide whether you can even know how well it's doing. An evaluation system with no reliable ground truth — however pretty the accuracy, however rigorous the confidence interval — is a tower on quicksand.
Which rows, how many, how reliably labeled — these three posts together are the foundation for honestly measuring an agent. The next post returns to the hook from last time: with reliable labels in hand, which line does launch actually gate on — why it's the confidence-interval lower bound, not that pretty point estimate.
If this made you decide to go measure inter-annotator agreement first, send me the keyword "GROUND TRUTH KIT" and I'll share the back-to-back agreement method plus that "price difference / exchange / shipment interception" rubric template.
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.