源文件改了,线上没变——一次 KB 静默失同步的 9 天

KB-OPS DEEP DIVE。 这是一篇工程深挖,不是方法论概述——讲一个企业级客服 Agent 的知识库流水线里,源文件和线上搜索索引怎么静默失同步了 9 天,以及我怎么把它挖出来、堵回去。上层方法论——该追哪个指标、上线前卡哪几道闸、AI 系统怎么测——在《Agentic AI 落地方法论》系列里。English version: Your KB Changed. The Search Index Didn't.
开场:同一条话术,本地是新的,线上是旧的
那天我在排查一批测试反馈,手里有一条很具体的线索:客户问「退款什么时候到账」,线上的 Agent 回了一句听着就让人皱眉的话——「目前还不如淘宝或者京东这类大型平台成熟」。
这句话我有印象。它早就被改掉了——9 天前的一次话术清理里,它被换成了中性的「请耐心等待,原路返回」。git log 里改动清清楚楚,diff 我自己看过。
所以我做了最朴素的一件事:本地起服务,curl 同一条 query。
# 本地——刚改过的 KB 源文件
$ curl -s http://127.0.0.1:8000/api/ask -d '{"q":"退款什么时候到账"}' | jq -r '.answer'
退款将原路返回,到账时间 3-15 个工作日,银行卡与支付宝时效略有差异……
# 线上——同一条 query
$ curl -s https://<prod>/api/ask -d '{"q":"退款什么时候到账"}' | jq -r '.answer'
……目前还不如淘宝或者京东这类大型平台成熟,请您耐心等待。
本地是新的。线上是旧的。源文件改了,线上没变。
那一刻我盯着这两段输出,心里冒出来的第一个念头是错的——「是不是这台机器没拉到最新代码」。但代码是同一份,git 里那条改动两边都在。问题不在源文件,问题在源文件和线上之间,隔着一个我一直以为是自动、其实是手动的步骤。
这一篇就是那次排查的复盘。它不是一个孤立的 bug,是一类系统——任何「人改源文件、机器读派生索引」的架构——都会埋的洞。33 条测试反馈里,有 16 条是这同一个根因的不同表象。

为什么「源 + 派生索引」这类系统,最容易静默失同步
任何把一份数据写进 source of truth、又派生出一个索引/缓存来读的系统,都自带一个失同步面——而它最阴险的地方是:失同步的时候,什么都不报错。
这套客服 Agent 的检索是典型的两段式:知识库(KB)是一堆 markdown 源文件,人来维护、git 来管版本;线上召回不读这些文件,读的是灌进 Elasticsearch 的索引。源文件是真相,索引是为了 BM25 检索性能而存在的派生副本。
这个形状你大概率也有一份——只是叫法不同:源数据 + 一个 embedding 向量库、数据库表 + 一个物化视图、对象存储 + 一个 CDN 缓存、配置中心 + 各服务的本地副本。只要「写的地方」和「读的地方」是两个存储,中间就有一条必须有人/有机器去走的同步链路。这一篇讲的是这条链路断了、而且断得无声无息时会发生什么。
这种架构有三个属性,凑在一起就是静默失同步的温床:
第一,写真相 ≠ 写索引。改 markdown、commit、push、部署——这条链路顺畅得让人产生错觉,以为「改了就生效了」。但索引是另一个存储,它不会因为源文件变了就自己跟着变。
第二,reload 看起来成功。系统有个 /api/kb/reload 端点,名字和返回值都在暗示「我把知识库重新加载了」。它返回 200,返回一个条目数。每个用过它的人都默认它把改动 propagate 到了线上。
第三,失同步不抛异常。索引旧不旧,对系统来说不是错误状态——它照常召回、照常返回一个答案,只不过那个答案来自 9 天前的旧 chunk。没有 500,没有报警,看板上一切正常。错误的答案和正确的答案,长得一模一样——都是 200。
这三条加起来,意味着失同步可以存活很久,直到有人——通常是 QA 或者一个较真的用户——拿一条具体 query 把它戳穿。这次戳穿它的是一批测试反馈。
第一波调查:33 行红,怎么聚成 16 行同一个根因
QA 那天交了一张表,33 条 case,每条是一个 query + 当前响应 + 期望要点。33 行飘红,看着像 33 个独立的 bug。
如果把它们当 33 个 bug 一条条修,会修到天荒地老,而且修不对——因为大部分根本不是各自的 bug。第一件该做的事不是修,是聚类:把 33 条按根因分组,看有没有共享的上游。
我顺着时间线对:
- 第 0 天,一次话术清理,把「不如淘宝京东」改成了中性措辞。
- 第 5 天,QA 跑测试,记录 33 条——其中「退款到账」那条仍然命中旧话术。
- 第 7 天,一次知识库业务审核,删掉了 61 条「不入库」的条目。
- 第 9 天,我开始排查。
第 5 天那条最刺眼:源文件第 0 天就改了,第 5 天测试却还命中旧的。我的第一直觉是「话术没改干净」——所以先去翻 git:
# 改动到底在不在?在。第 0 天就改了。
$ git log --oneline -S "不如淘宝" -- knowledge-base/
<commit> 第 0 天 · 退款话术中性化:删除「不如淘宝京东」表述
# 那本地读到的是新的吗?是。
$ curl -s http://127.0.0.1:8000/api/kb/stats | jq '.layer1.refund.entries[] | select(.id|test("到账"))'
{ "id": "l1_refund_退款到账时间", "text": "原路返回,3-15 个工作日……" }
源文件改了、parser 本地也读到了新条目——那「话术没改干净」这个直觉就被否了。链路上游全对,问题只可能在下游:从源文件到线上之间。于是有了开场那个本地 vs 线上的对照,把范围锁死到「线上索引从没跟着重建」。
排查这类问题,最省时间的不是猜哪里坏了,是沿着数据流一段段确认哪里还是对的——源文件对、本地 parser 对、本地召回对,剩下唯一没确认的那一段,就是答案。
一旦锁定「索引失同步」,33 条里哪些会被它解释,就清楚了。我把 33 条分成四类:

- A 类 · 失同步直接受害(16 条):意图分类大多是对的,KB 里也有正确答案,但线上索引是旧的——要么命中旧 chunk(「不如淘宝京东」),要么因为某个文件的可用条目被删空而 fallback。这 16 条是同一个根因。
- B 类 · 前端流式渲染(9 条):返回格式问题,ndjson 的 SSE delta 没合并显示。跟 KB 无关,另开 issue。
- C 类 · 内容尚可待复测(3 条):reindex 后重新验。
- D 类 · 本来就正常(4 条):留作 happy-path 回归 fixture。
33 条里真正需要我现在动手的,是 A 类那 16 条——而它们不是 16 个问题,是 1 个问题的 16 个投影。 这一步聚类,把工作量从「修 33 个 bug」压成了「修 1 个根因 + 收尾几个零散的」。
但当我去修这「1 个根因」时,它裂成了两段。
第一段根因:reload 端点对 Elasticsearch 是个 no-op
定位到「索引没重建」,下一个问题是:为什么没重建?流程里明明有 reload。
我去读 reload 背后的实现。检索层是可插拔的,有个内存后端、有个 Elasticsearch 后端。reload 端点会调用当前后端的 ingest()。Elasticsearch 后端的 ingest() 长这样:
# app/retrieval/elasticsearch.py
async def ingest(self, documents: list[Document]) -> int:
"""No-op for ES — use scripts/index_to_es.py for bulk indexing."""
return 0
它什么都不做,直接返回 0。
这不是 bug——它是个有意的设计决定,只是没人把它写进流程。批量灌索引走的是另一条路:一个独立脚本 scripts/index_to_es.py --recreate,会删掉旧索引、从源文件重建。ingest() 之所以是 no-op,是因为作者不想让一个 HTTP 请求触发全量重建(几秒内索引不可查)。逻辑上完全合理。
问题在于,reload 端点的名字和返回值,撒了个善意的谎。它返回 200、返回一个看起来正常的条目数(来自内存层的统计),让每个调它的人都以为索引更新了。真正更新索引的那条命令,藏在一个脚本里,而「改完 KB 要手动跑这个脚本」这条规约——文档里没写,QA 的流程里没有,KB 维护的 checklist 里也没有。
于是第 0 天和第 7 天两次 KB 改动,都顺顺当当地 commit、部署、reload 成功——然后一条都没进线上索引。
一个返回 200 的 no-op,比一个抛异常的 bug 危险得多。 异常会有人去看,200 没人会去查。
第二段根因:parser 只读半个文件
如果只有第一段根因,修起来很干脆:跑一次 reindex 就行。但当我本地重建索引、重新统计每个分类的可用条目时,发现有个文件的条目数是 0——积分优惠类(coupon-points),「积分怎么用」这种高频问题,可用答案一条都没有。
这引出了第二段、更隐蔽的根因。
KB 的每个 markdown 文件有两段结构:前面是 ## xxx 政策规则,一段编号的规则列表;后面是 ## AI 回答模板,给检索用的问答条目。parser 抽条目时只认后面那段:
# app/retrieval/parser.py _parse_layer1
m = re.search(r"## AI 回答模板\s*\n(.+?)(?=\n## |\Z)", text, re.S)
if not m:
return [] # 没有「AI 回答模板」段 = 这个文件 0 条目
entries = _split_entries(m.group(1))
前面那段 ## 政策规则 里其实躺着 20 多条很好的答案——「退款到账 2」「退款到账 3」「待退款 2」之类——但因为不在 ## AI 回答模板 段里,parser 完全看不见它们。
平时这不致命,因为每个文件的 ## AI 回答模板 段里多少有几条。但第 7 天那次审核删掉 61 条「不入库」条目时,是按条目删的,没人意识到某些文件的 ## AI 回答模板 段会被删空。删完之后的可用条目存量长这样:
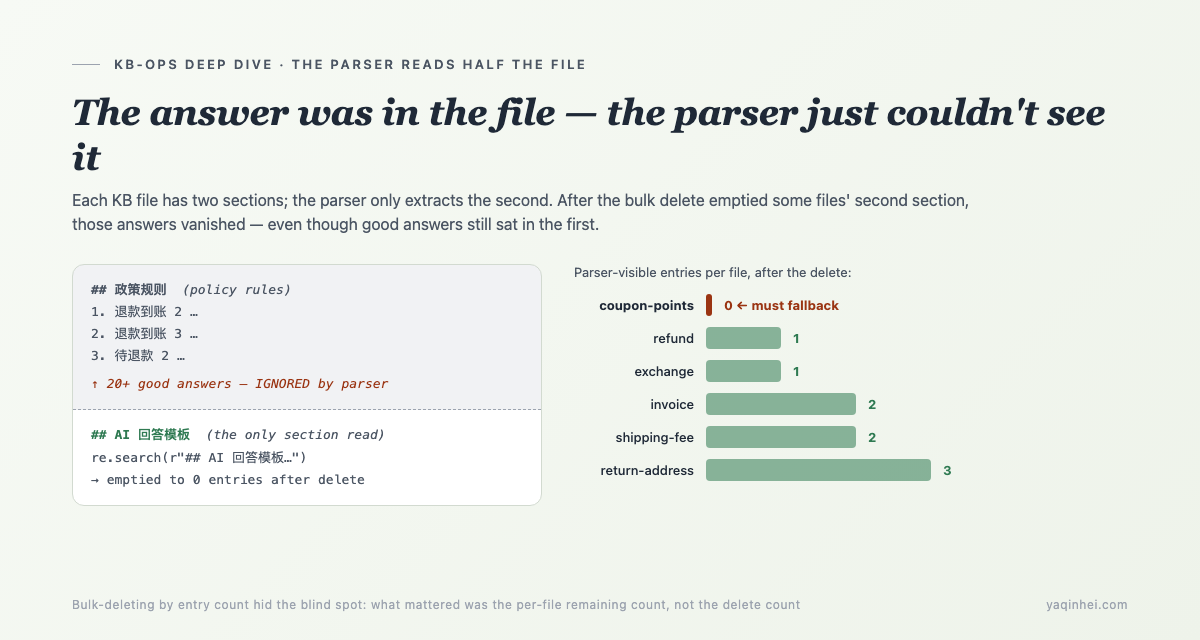
| KB 文件 | parser 可见条目 | 后果 |
|---|---|---|
| coupon-points | 0 | 「积分怎么用」必定 fallback |
| refund | 1 | 「退款到账」系列 → 命中旧索引的丢人话术 |
| exchange | 1 | 「鞋子小能换吗」错配 |
| invoice | 2 | 「我要开发票」错配到优惠券模板 |
| shipping-fee | 2 | 「退货运费谁出」错配到无理由退货 |
| return-address | 3 | 「退货地址」只答了片面情况 |
coupon-points 那个 0 尤其要命:它前面的 ## 政策规则 段里明明有积分使用、优惠券查看的好答案,但 parser 读不到,于是「积分怎么用」直接掉进 fallback。答案就在文件里,系统却说不知道。
两段叠加:为什么是「静默 9 天」而不是「当场报错」
单独看,这两段根因都不致命;是它们叠在一起,才造出了 9 天的静默窗口。
把时间线摊开看就清楚了:

- 第 0 天改了话术 → 因为根因一(reload 是 no-op),没进索引,但没人知道,因为不报错。
- 第 7 天删了 61 条 → 因为根因二(parser 只读半个文件),某些文件被删空,但也没进索引,还是因为根因一。
- 第 0 到第 9 天,线上一直在用第 0 天之前的旧索引——旧话术、旧 chunk,原封不动地服务着真实用户。
如果只有根因一,迟早有人跑一次 reindex,旧话术就没了。如果只有根因二,至少删空的文件还能从旧索引召回点东西。但两个一叠:源文件在变、索引在冻结、而冻结这件事本身不可见。你以为你发布了,其实你没有——而且没有任何信号告诉你这个区别。
这就是这类 bug 最该被记住的形状:它不是「一个东西坏了」,是「一个本该发生的更新,没发生,而且没发生这件事不产生任何痕迹」。
修复:把条目搬回来 + 重建索引 + 实测
修复路径分两层,都不复杂,但顺序不能错。
第一层,把藏在 ## 政策规则 段里仍然适用的条目,搬到 ## AI 回答模板 段,让 parser 看得见。 优先补 coupon-points(从 0 补起)、refund(把「退款到账」系列提上去)、invoice、shipping-fee。注意一个坑:第 0 天被改掉的那条旧话术,第 7 天已经删了——搬条目的时候别把它复活,保持中性措辞,绝不让「不如淘宝京东」回来。
搬完先在本地验 parser 真的读到了:
$ curl -s http://127.0.0.1:8000/api/kb/stats | jq '.by_subcategory'
{
"layer1/coupon_points": 7, # 0 → 7
"layer1/refund": 8, # 1 → 8
"layer1/return": 4, # 1 → 4
"layer1/invoice": 5 # 2 → 5
}
第二层,重建索引——这一步才是把改动真正推上线的那一步:
$ uv run python scripts/index_to_es.py --recreate
这条命令有副作用:重建期间几秒内 cs_knowledge_base 索引不可查。生产 ES 上跑,要先跟人确认、挑低峰。这正是当初 ingest() 设计成 no-op 的原因——只是那个权衡从没被写下来、被流程承接。
然后把 33 条做成 yaml fixture,逐条打 /api/ask,diff 期望要点。A 类 16 条的实测结果是:
- 4 条完全修复(命中新模板,含「退款到账时间」不再有丢人话术)
- 4 条部分修复(答案内容对,但跨层命中,措辞不够准)
- 2 条意图错配但答案尚可
- 6 条仍有问题——而这 6 条的根因,已经不是失同步了
上线可感知改善 10/16。这个数字本身就是一个诚实信号:reindex 修好的,是「失同步」这一个根因能解释的部分;剩下的,是被失同步盖住的、另一批本来就存在的问题。
修完一个洞,露出下一个:剩下 6 条的真根因
堵住失同步这个大洞之后,水位下去了,露出了底下一直都在、只是被淹着的几块石头。 这是排查这类系统时反复出现的剧情:你修好最上游的那个原因,下游就暴露出它自己的、更细的原因。
剩下 6 条,根因各不相同,没一个还是 KB×索引失同步:

第一类,意图规则的匹配顺序错。「我的退货审到哪一步了」应该是 return_status,但规则表里 return_request 在前,一条 退货 的宽匹配把它抢走了。「退货运费谁出」同理,被 return_request 抢走,没到 shipping_fee。修法是给 return_status 加口语 pattern(覆盖「审到哪/到哪一步」,不强求「审核」二字),并把 shipping_fee 移到 return_request 之前:
# app/intent/rules.py
"return_status": [r"退.*审.*到哪", r"退.*审.*哪一?步", r"退.*审.*几天"],
# 顺序调整:shipping_fee 必须在 return_request 之前,
# 否则 r"退货" 会抢走「退货运费」这种组合词
改完,「退货运费谁出」不光意图对了,答案也完全命中了新写的「退货运费谁承担」模板。
第二类,意图没有 KB,却被跨层 BM25 误命中。「支付失败怎么办」「怎么取消订单」这两个意图压根没有 layer1 知识库,检索时 BM25 在别的层里乱抓一个最近邻——「支付失败」抓到了「退款凭证查询」,「取消订单」抓到了「自助开票」。答非所问,但因为有答案,照样返回 200。修法是给这类意图一个白名单,在检索之前短路到 fallback,不让它进 BM25 的轮盘赌:
# app/dialog/router.py
INTENTS_WITHOUT_KB = frozenset({"payment", "order_cancel"})
if intent in INTENTS_WITHOUT_KB:
return _fallback_events() # 跳过检索,直接给安全兜底话术
改完,这两条不再误命中,干净地走 fallback。
第三类,layer3 该接住的情绪没接住。「我要投诉到经理」应该升级到 layer3,但意图分类没把它分过去。给 escalation 加了 投诉.*经理/投诉.*领导/投诉到 这些 pattern 后意图对了——但这条暴露了一个更深的、独立的环境问题:所有 layer3 意图当时都返回 500,根因在 LLM 生成路径的网关连接,跟我这次的 KB 修复无关,单独追。
注意第三类这个细节——它是这次排查里我最满意的一步,不是因为修好了,恰恰因为没修好。 我加完规则发现 /api/ask 还是 500,但我没有当场去改我的规则,而是先确认了「是不是所有 layer3 都 500」。一确认,发现 complaint_quality、complaint_service 全 500——那就说明问题不在我的改动,在共用的 LLM 网关。如果当时急着「让这条过」,很可能去乱动规则,把一个环境问题伪装成代码问题埋得更深。
把两波修复的账摊在一起看,剩余 case 的演进很说明问题——第一波(reindex)解决的是「失同步」,第二波(意图路由)解决的是被它盖住的下游问题:
| Case | 第一波(reindex)后 | 第二波(意图路由)后 |
|---|---|---|
| 退货审进度 | 意图错(被 return_request 抢) | 意图对(return_status),答案待补专属模板 |
| 退货运费 | 意图错(被 return_request 抢) | 完全修复(意图 + 答案都对) |
| 支付失败 | 误命中「退款凭证查询」 | 正确走 fallback |
| 取消订单 | 误命中「自助开票」 | 正确走 fallback |
| 投诉到经理 | unknown,没接住 | 意图对(escalation),layer3 网关 500 独立追 |
A 类 16 条累计:4 条完全修复 + 3 条部分 + 5 条意图对但受 KB/环境限制 + 4 条待 follow-up = 14 条用户可感知改善,其中 10 条当期可上线。没有一个数字是「全绿」——而这恰恰是这次复盘最该留下的诚实:一个根因堵住,露出的是分层的下一批根因,不是终点。
为什么看板全绿,这事却烂了 9 天
这类失同步,所有标准监控都抓不到——因为它的每一个环节,单看都是「正常」。
reload 端点返回 200,不是错误。索引召回返回一个答案,不是错误。延迟正常、错误率为零、服务健康检查全绿。能反映出问题的,是「这个答案对不对」——而对不对,是一个语义判断,不是任何系统指标。这正是上线前卡哪几道闸那篇里反复讲的:approved(系统层面没出错)不等于做对(答案真的对)。
能抓住这次失同步的,只有一样东西:端到端的内容回归——拿一组「query → 期望要点」的固定 case,定期打线上,diff 答案。这恰恰是 QA 那 33 条干的事,也是为什么这类 case 必须 fixture 化、进 CI,而不是靠人偶尔手测。我在双轨测试那篇里把这条单拎出来讲过:AI 系统的「测对不对」这一轨,和「服务健不健康」那一轨,是两件不同的事,后者全绿挡不住前者全错。
一句话:这次不是监控漏报了,是根本没有一个监控在看「答案对不对」这件事。 失同步只是利用了这个盲区。
本周能给自己 KB 流水线加的 10 道闸
把这次的教训拆成可以直接抄的动作——任何「源文件 + 派生索引」的系统都适用:
- 给「改源 → 重建索引」这条链路一个不可跳过的步骤。 要么 reload 端点真的触发 reindex,要么 CI 在 KB 改动时强制跑重建——别让它停留在「某个脚本,记得手动跑」。
- CI gate:KB 改动时跑
index_to_es.py --dry-run,断言 parser 产出条目数大于 0。 这一条就能在合并前拦住「某文件 AI 模板 = 0」。 - 给每个 KB 分类设一条「可见条目数 ≥ 1」的断言,进健康检查或 CI——把「答案就在文件里、parser 却读不到」变成一个会报警的状态。
- 任何返回 200 的 no-op,要么去掉、要么让它说真话。 reload 如果不 reindex,就别返回一个让人以为 reindex 了的条目数;返回「索引未变更,请跑 X」。
- 端到端内容回归 fixture 化 + 进 CI。 一组「query → 期望要点」定期打线上,diff 答案。这是唯一能抓住语义失同步的网。
- 本地 vs 线上对照,做成一条命令。 排查时我手动 curl 两边——把它脚本化,任何「我改的东西到底上线没有」的怀疑,一条命令出答案。
- 源文件结构如果分段,parser 的覆盖范围要么覆盖全部、要么显式声明只读哪段,并在那段为空时告警,而不是静默返回空列表。
- 批量删条目时,按「删完每个文件还剩几条可见条目」复核,而不是只看「删了多少条」。删除的盲区在存量,不在删量。
- 重建索引这种有副作用的操作,把副作用写进 runbook(重建期间不可查、挑低峰、需确认)——别让一个合理的技术权衡,因为没写下来而变成流程缺口。
- 修完一个根因,假设它盖住了别的。 把残留 case 单独再聚一次类,别假设「大洞堵了就全好了」——水位下去会露出新石头。
想再深一层
这次踩的,是个有名字的老问题。如果你想把它放进更大的脉络:
- Dual-write problem:往两个存储写同一份数据(源 + 索引),没有事务保证两边一致——分布式系统里反复出现的一类坑。
- Cache invalidation:Phil Karlton 那句「计算机科学只有两件难事:缓存失效和命名」不是玩笑。派生索引本质就是一个缓存,失同步就是缓存没失效。
- CQRS / read-model rebuild:把写模型(源)和读模型(索引)分开的架构里,读模型的重建是一等公民,必须有显式、可观测、可重放的重建流程——而不是一个手动脚本。
- Elasticsearch alias 零停机 reindex:用 alias 指向新索引、后台重建完再切,能消掉「重建期间不可查」这个副作用——也就顺手消掉了「因为有副作用所以做成手动」的理由。
这些不是高深理论,是「派生数据」这个模式的标准配套。这次的 bug 之所以能活 9 天,不是因为它新,是因为这套配套没装齐。
下一篇回到方法论主线,拆一个把抽象的「deterministic workflow」落成可读代码骨架的话题:一个真的会动钱的 L2 退款 workflow,到底长什么样。
回复关键词「失同步自查」,我把这份《源 + 派生索引失同步自查表》发给你:10 道闸 + 本地/线上对照脚本模板 + KB 健康检查断言清单,一页能贴在 KB 维护流程旁边。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.