CPU 没满、QPS 没涨,P99 却翻倍——是运维看板在偷偷掐住客服 Agent

PERF DEEP DIVE。 这是一篇工程深挖,不是方法论概述——讲一个企业级客服 Agent 的服务里,一个同步调用怎么在单线程 event loop 上周期性地掐住所有并发请求,以及我怎么把它从「第一嫌疑人 ES」一路排查到真凶「运维看板自己」。上层方法论——AI 系统怎么测、该追哪个指标——在《Agentic AI 落地方法论》系列里。这一篇和上一篇《一次 KB 静默失同步的 9 天》同属工程复盘子系列。English version: Your Dashboard Is Throttling the Agent It Watches.
开场:一条每隔几分钟准时来一次的 P99 尖峰
那天我在看客服 Agent 的延迟曲线,看到一个很别扭的形状。
P99 不是高,是有节奏。绝大多数时候它老老实实趴在目标线(看板里写死的 p95_target_s=5.0)下面,2 到 3 秒一个回合,干净。然后每隔几分钟,「啪」一个尖峰,窜到两位数秒级,再落回去。再过几分钟,又一个。
P99 latency (s)
12 ┤ ╮ ╮ ╮
9 ┤ │ │ │
6 ┤── ─ ── │ ── ── ── ── ─│ ── ── ── ── ─│ ── ─ ← p95_target 5s
3 ┤────────╯──────────────╯──────────────╯───────
└────────────────────────────────────────────
▲ 每隔几分钟,一个准时的尖峰
随机的慢我不慌——网络抖动、某条 query 命中了大文档、模型偶尔慢一拍,都正常。但周期性的慢,意味着背后有个按固定节拍触发的东西,每次触发都把延迟拽起来一次。这种规律性本身就是线索:它不是「负载上来了」,是「有什么东西在定时发作」。
我先把能想到的「正常该看的指标」全调出来对了一遍:
- CPU:平的,没有跟着尖峰走。
- QPS:平的,尖峰那一刻进来的请求数没有暴涨。
- 错误率:零。没有 500,没有 timeout 报错。
- Agent 代码:那几天一行没动,没有新发布。
负载没变、代码没变、机器没喘,延迟却周期性翻倍——这组合排除了所有「忙不过来」的解释。 不是 Agent 干的活变多了或变重了,是有什么东西在它干活的时候,周期性地把它按住几秒钟。
那么,是谁按住的?我和当时屋里所有人的第一反应是同一个——检索。
为什么第一嫌疑人永远是 ES,以及为什么这次它是冤枉的
客服 Agent 最重的那段 I/O 是知识库检索,所以延迟一抖,所有人的手指都会先指向 ES——这是对的直觉,但这次指错了。
道理很朴素:一次对话里,调外部订单接口是毫秒级、跑意图分类是本地的,唯一又慢又重的环节就是去 Elasticsearch 里做 BM25 + 向量混合召回。经验上,延迟出问题十有八九在这。所以我去翻检索层的代码,准备抓一个「同步阻塞的 ES 调用」现行。
结果检索层是干净的。ES 查询是 async 的:
# app/retrieval/elasticsearch.py
_bm25_t0 = time.perf_counter()
response = await self._es.search(index=INDEX_NAME, body=body)
bm25_hits = response["hits"]["hits"]
logger.info("retrieval[ES BM25]: count=%d latency=%.1fms", len(bm25_hits), _lat_ms(_bm25_t0))
# 混合检索:embedding 也是 async 的
if self._embedding:
vector = await self._embedding.embed(query)
用的是 AsyncElasticsearch 客户端,await 出去;embedding 走 AsyncOpenAI,也是 await 出去。两个最可疑的网络调用,都没有在 event loop 上同步堵着。
更要命的是那行 logger.info 里的 BM25 latency——它一直在打,尖峰那一刻打出来的检索延迟,跟平时没两样,几十毫秒。如果是 ES 慢,这个数字会跟着尖峰一起飙。它没有。
# 尖峰时刻的检索日志——干净
retrieval[ES BM25]: count=5 latency=42.7ms
retrieval[ES BM25]: count=5 latency=39.1ms ← 这一秒整体 P99 是 11s
retrieval[ES BM25]: count=5 latency=44.3ms
检索本身 40 毫秒,而这一秒的端到端 P99 是 11 秒。那 10 多秒不在检索里——它在请求进来、还没轮到检索之前的某个地方。 ES 被洗清了。
这一步省了我后面一堆时间,不是因为我聪明,是因为排查这类问题最有效的动作不是猜哪坏了,而是沿数据流一段段确认哪还是对的:检索对、embedding 对、检索延迟日志对——那慢的地方就只能在这几段「对」的上游或它们之间的空档里。
但空档里能有什么?请求进来、解析、分类、检索……每一段都是 Agent 自己的代码,都不慢。问题是,在一个单线程的 async 服务里,拖慢你的东西,不一定是你这条请求链路上的任何一段。
单线程 event loop:一个同步调用,全员排队
asyncio 是单线程协作式调度——整个进程同一时刻只有一段 Python 代码在 event loop 上跑。这意味着:任何一个不让出控制权的同步调用,会冻住这一刻 loop 上所有的并发请求,哪怕那些请求跟它八竿子打不着。
这是理解这次事故的全部钥匙,值得花三句话说清。
平时为什么能并发?因为每个请求干到 I/O(查 ES、调接口、等模型)就 await 一下,把控制权交还给 loop,loop 趁机去推进别的请求。大家轮流让步,看起来就像同时在跑。这套机制的前提是:每个人到了 I/O 都老老实实让步。
一旦有一段代码不让步——典型就是一个同步的网络调用,它在等 HTTP 返回的那几秒里,既不 await、也不交还控制权,就那么攥着 loop——那么这几秒内,loop 上所有其他请求全部冻结,排在它后面干等。
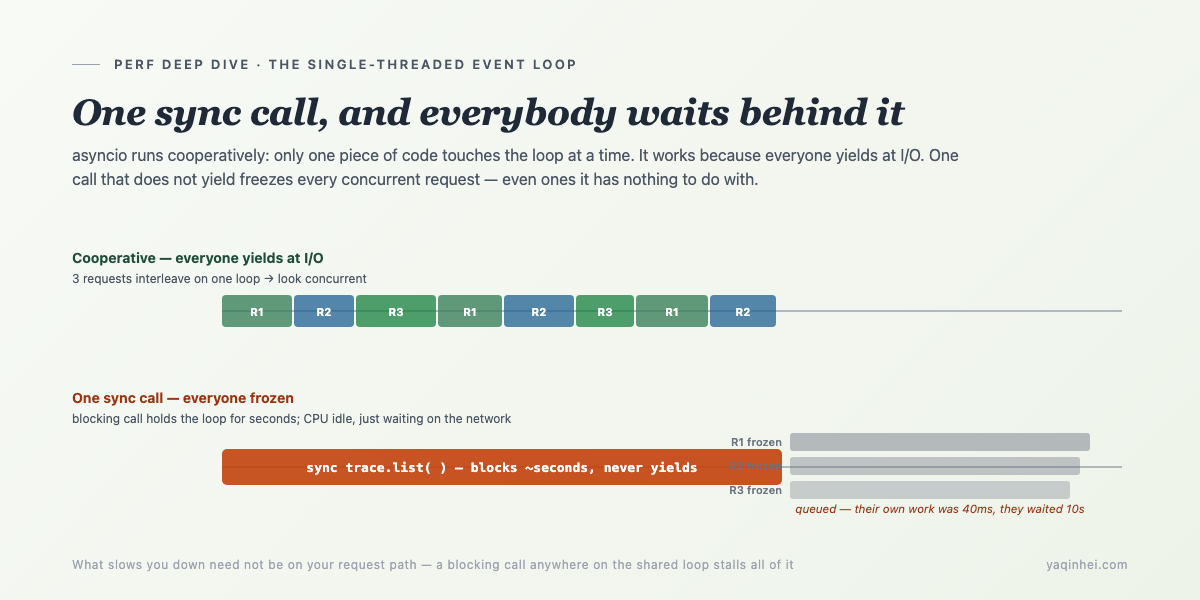
放到这次:尖峰那一秒,被卡住的真实客服请求,它们自己的检索只要 40 毫秒。它们慢,不是因为自己慢,是因为有别人攥着 loop 不放,它们在门外排队排了 10 秒。
所以接下来要找的,不是「哪条请求链路慢」,而是「谁,在按那个固定节拍,往这个共享的 loop 上扔了一个同步阻塞调用」。而它有节奏这件事告诉我:它多半不是用户请求触发的(用户来得随机),而是某个定时任务。
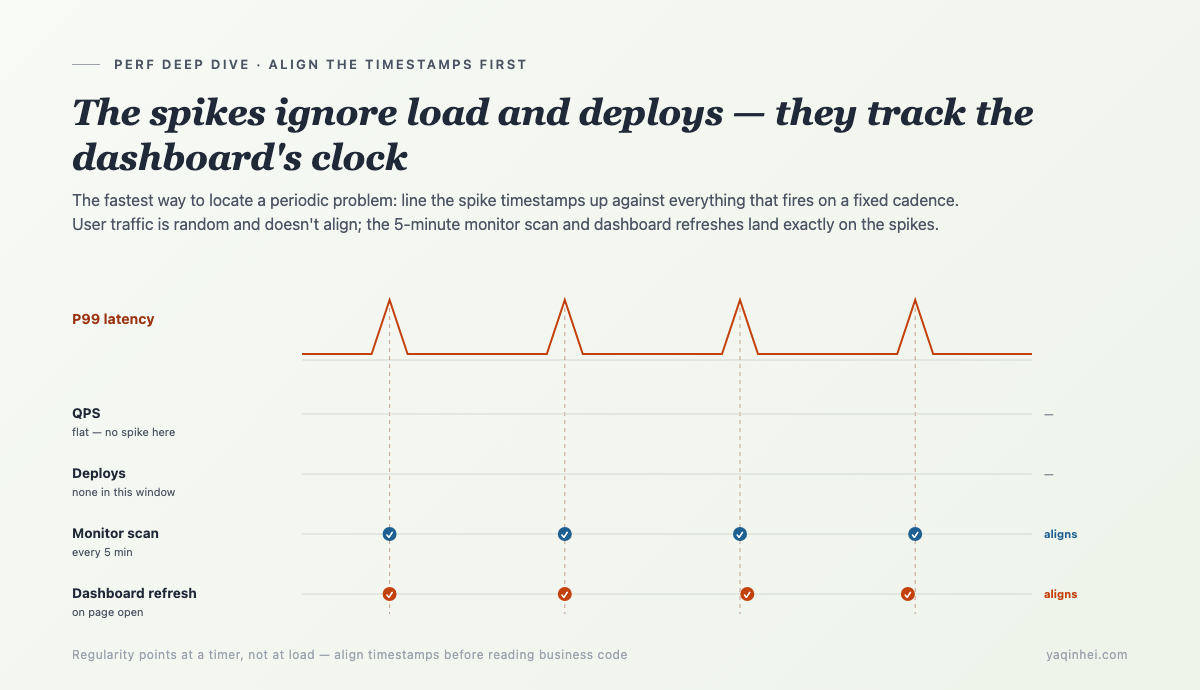
抓现行:把尖峰时间戳对齐到「非用户触发」的事件
定位周期性问题,最直接的一招是对时间戳:把尖峰发生的时刻,跟系统里所有「按固定间隔发生」的事件并排放,看谁的节拍能对上。
服务里按固定间隔跑的东西不多。我把它们列出来,逐个对节拍。最快对上的是后台监控扫描:
# app/monitor/scheduler.py
async def run_monitor_loop(scanner: Scanner, interval_seconds: int = 300) -> None:
"""Background loop: scan every `interval_seconds` (default 5 min)."""
while True:
try:
count = await scanner.scan()
...
await asyncio.sleep(interval_seconds) # 默认 300s = 5 分钟
interval_seconds=300——每 5 分钟一轮。尖峰的节拍,跟它对上了。
注意这个后台 loop 是怎么跑的:它是个 async def,用 asyncio.sleep 睡,跟 FastAPI 主服务跑在同一个 event loop 上。它不是另一个进程、不是另一个线程——它和真实客服请求共享同一个单线程 loop。这一点先记住,它是后面所有事故的物理基础。
但 scanner.scan() 本身是 await 的,看起来也让步了。所以光是「monitor 每 5 分钟跑一次」还不够定罪——得看它跑的时候,里面到底调了什么。除了这个 5 分钟的后台扫描,还有一个触发源我一开始漏了:运维看板页面。每次有人打开那个看板,前端会去拉一批 KPI、最近会话、延迟分布——而这些数据,全都来自同一个地方。
顺着 monitor 扫描和看板取数这两条线往里走,它们汇到了同一个模块:把 Langfuse 的 trace 聚合成看板 KPI 的那个 rollup。真凶在那。
真凶:看板用同步 SDK 拉 trace,就拉在 Agent 的 loop 上
那个用来观测 Agent 健康度的运维看板,它取数的方式,是在 Agent 自己的 event loop 上,发起一个同步的、分页的、要跑几秒的 HTTP 调用。看板每刷新一次、monitor 每扫一次,就把 Agent 掐停几秒。观测层在拖慢它观测的对象。
看板的所有数字——今日会话数、AI 解决率、P95 延迟、最近会话列表——都是从 Langfuse 里捞 trace 聚合出来的。聚合逻辑简化下来就一句:拉最近 24 小时的 trace,按 tag 分组,算指标。拉 trace 用的是 Langfuse v4 Python SDK 的 api.trace.list。
问题就在这个 api.trace.list:它是同步的。 它发一个 HTTP 请求到 Langfuse,等响应回来,期间不让步。而看板一屏要的数据量不小,trace 列表分页拉、每页上限 100 条,要拉好几页——几秒钟的同步 HTTP 往返,结结实实压在 event loop 上。
把物理链路摆出来就是:
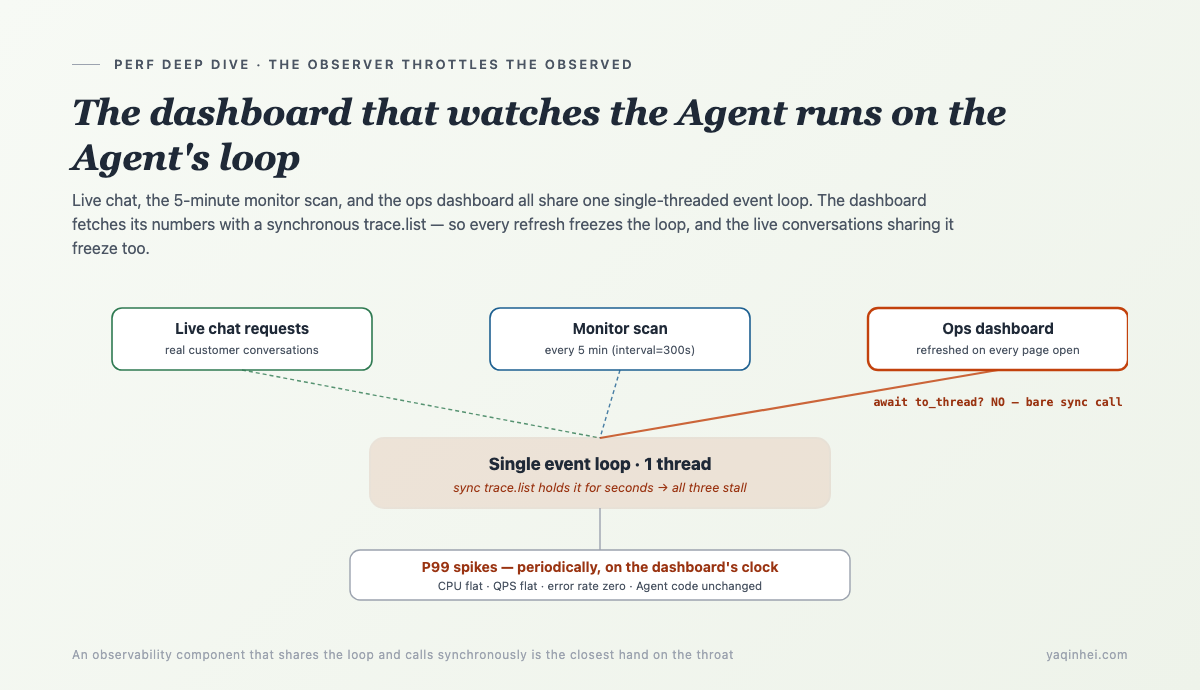
trace.list,几秒内不让步,另外两者一起卡住。看板越想看清 Agent,就越把 Agent 按得越死。
这就解释了之前所有对不上的现象,严丝合缝:
- 为什么 CPU 平?因为同步 HTTP 调用的那几秒,进程不是在算,是在等网络——CPU 闲着,loop 却动不了。这正是阻塞最阴的地方:它不消耗 CPU,所以 CPU 监控完全看不见。
- 为什么 QPS、错误率都平?因为被卡住的请求最终都成功了,只是每个都多等了几秒。没报错,没掉请求,只是慢。
- 为什么周期性?看板有人定时刷、monitor 固定 5 分钟扫——节拍来自它们,不来自用户。
- 为什么 Agent 代码没改也会慢?因为掐它的代码根本不在 Agent 的请求链路上,在隔壁那个看板模块里。
一个用来「看 Agent 健不健康」的工具,成了 Agent 不健康的原因。 这种反讽不是巧合——可观测性组件天然要频繁地、定时地拉数据,一旦它和被观测的服务共享 loop、又用了同步调用,它就是离被观测对象最近的那把掐脖子的手。
修复一:把同步调用甩出 loop——asyncio.to_thread
定位之后,第一层修复干脆利落:既然 trace.list 是个改不动的同步 SDK 调用,那就别让它在 event loop 上跑——把它甩进线程池。
# app/tracing/langfuse_rollup.py
resp = await asyncio.to_thread(self._langfuse.api.trace.list, **list_kwargs)
data = list(resp.data)
asyncio.to_thread 把那个同步调用扔到一个独立线程里执行,主 loop 拿到一个可以 await 的 awaitable——于是 loop 在等 trace 拉取的那几秒里重新获得了让步的能力,可以照常推进真实客服请求。同步调用还是那么慢,但它的慢被隔离在线程里,不再传染给整个 loop。
这一行就是整个事故的核心修复。它配得上被记成一条规则:在 async 服务里,任何你改不动的同步阻塞调用(第三方 SDK、requests、重 CPU 计算、大 JSON 解析),都必须用 asyncio.to_thread(或 run_in_executor)隔离,绝不能裸调。 裸调一个同步函数,等于在所有并发请求面前临时拉了一道闸。
同一个项目里,另一处也用了同样的手法兜 Langfuse 的同步 SDK——把同步的 trace 拉取统一包进线程:
# 另一处同样模式:同步 SDK 一律 to_thread
vals = await asyncio.to_thread(_work)
判断「该不该 to_thread」的标准很简单:这个函数名前面有没有 await?没有 await、又会跑一段时间(网络/磁盘/重计算),它就在偷你的 loop。
修复二:给看板取数加 TTL 缓存——掐掉「刷新风暴」
光把同步调用甩进线程还不够——还得防住第二个隐患:好几个人同时盯着看板狂刷新,每次刷新都开一个线程去拉 Langfuse,把线程池和 Langfuse 后端一起打满。
to_thread 解决了「不阻塞 loop」,但没解决「拉得太频繁」。运维看板天然会被反复刷——盯盘的人手一抖就 F5,几个人同时看,请求叠上来,每个都触发一次真实的 Langfuse 拉取。这就是「刷新风暴」:观测层把自己的后端打趴下。
修法是给取数套一层短 TTL 缓存:
# app/tracing/langfuse_rollup.py
from cachetools import TTLCache
class LangfuseRollup:
def __init__(self, langfuse, cache_ttl_seconds: int = 300):
self._cache: TTLCache = TTLCache(maxsize=16, ttl=cache_ttl_seconds)
async def _fetch_traces_in_window(self, *, hours, limit=100, to_hours=0):
key = ("traces", hours, limit, to_hours)
cached = self._cache.get(key)
if cached is not None:
return cached # 5 分钟内的重复刷新,直接吃缓存,不打 Langfuse
...
resp = await asyncio.to_thread(self._langfuse.api.trace.list, **list_kwargs)
self._cache[key] = list(resp.data)
return self._cache[key]
TTLCache(maxsize=16, ttl=300)——同一个查询窗口的结果缓存 5 分钟。5 分钟内不管多少人刷多少次看板,只有第一次真去拉 Langfuse,剩下全部命中缓存。看板数据「最多旧 5 分钟」对运维盯盘完全够用——KPI 又不是逐秒交易,晚 5 分钟看到没有任何代价,但换来的是后端不被刷爆。
这条同样能抽象成规则:任何「定时/被频繁触发 + 数据可容忍短暂陈旧」的取数,都该有一层 TTL 缓存挡在真实后端前面。 看板、健康检查、聚合报表,全是这个模式。判断标准就一句:这个数据晚几分钟看到,会死人吗?不会,那就缓存。
两层修复合起来——to_thread 让单次取数不再阻塞 loop,TTL cache 让取数不再被反复触发——周期性尖峰就消失了。P99 拉平回目标线下。

为什么常规监控全绿,这事却能持续发作
这次事故里,所有「该报警的指标」都没报警——因为阻塞不消耗 CPU、不产生错误、不掉请求,它只让一切变慢,而「变慢」恰恰是大多数监控最不敏感的维度。
复盘一下盲区在哪:
- CPU/内存监控看不见它:同步网络调用在等 I/O,CPU 是闲的。靠 CPU 报警,永远抓不到一个 I/O 阻塞。
- 错误率监控看不见它:被卡的请求最后都成功了,只是慢。错误率纹丝不动。
- 健康检查看不见它:探活接口自己很轻,恰好没赶上阻塞那一刻就返回 200。服务「健康」。
- 平均延迟会稀释它:尖峰是周期性的、占比小,揉进平均值里几乎看不出。只有 P99/P95 这种尾部分位数,才会把「大多数时候很快、偶尔卡死几秒」这个形状暴露出来。
这跟我在双轨测试那篇里讲的是同一个道理的另一面:服务「健不健康」和它「快不快」是两轨,前者全绿挡不住后者周期性翻倍。这次能被发现,纯粹是因为有人盯着 P99 曲线、并且较真地问了一句「这尖峰怎么这么规律」——而不是因为任何一个自动报警响了。
真正该补的,不是某个具体阈值,是一个直接盯着「event loop 有没有被卡住」的探针。 下面就是这个探针,以及围着它的一圈自查。
本周能给自己 async 服务装的 10 个 event-loop 闸
把这次的教训拆成可以直接抄的动作——任何 asyncio / FastAPI 服务都适用:
-
装一个 event-loop lag 探针。 周期性
call_later一个回调,测它实际被调用的时刻和预定时刻的偏差(drift)。loop 没被卡,drift 接近 0;一旦有同步调用攥住 loop,drift 会窜成几秒。这是唯一直接量化「loop 被卡了多久」的指标:import asyncio, time async def loop_lag_monitor(threshold_s: float = 0.25): loop = asyncio.get_running_loop() while True: t0 = loop.time() await asyncio.sleep(1.0) # 期望 1s 后醒 drift = loop.time() - t0 - 1.0 # 实际多睡了多久 = loop 被卡多久 if drift > threshold_s: logger.warning("event-loop lag: %.2fs", drift) # 把 drift 打成 metric,配 P99 一起看 -
开发期打开 asyncio debug mode。
PYTHONASYNCIODEBUG=1或asyncio.run(main(), debug=True),再把loop.slow_callback_duration调低(如 0.1s)。任何在 loop 上跑超过阈值的回调,会直接打 warning 点名——同步阻塞当场现形,不用等线上。 -
给「同步调用必须 to_thread」立一条 review 规则。 任何第三方 SDK 调用、
requests.*、time.sleep、重 CPU 计算、大 JSON 解析,出现在async def里且前面没有await,一律视为阻塞,必须asyncio.to_thread/run_in_executor包起来。 -
审计所有定时任务和后台 loop 的栖身之处。 列出每一个
asyncio.sleep循环、每一个 cron/scheduler,确认它们跑在哪个 loop。和在线请求共享 loop的后台任务,是阻塞事故的高发区——它定时发作,正好制造周期性尾延迟。 -
可观测性组件优先考虑「离线 loop」。 看板取数、指标聚合、trace 拉取这类「为了看服务而频繁拉数据」的逻辑,要么 to_thread、要么干脆挪到独立进程/worker,别让监控自己成为延迟源。
-
给一切「定时 + 可容忍陈旧」的取数加 TTL 缓存。 看板、报表、聚合 KPI,套一层短 TTL(分钟级)挡在真实后端前,掐掉刷新风暴。判断标准:这数据晚几分钟看到会不会出事?不会就缓存。
-
盯 P99/P95,别只盯平均。 周期性阻塞会被平均值稀释,只在尾部分位数上现形。延迟看板默认就该是分位数,平均值只能用来误导自己。
-
遇到周期性慢,先对时间戳,别先翻业务代码。 把尖峰时刻和所有固定间隔事件(cron、scheduler、缓存过期、看板刷新)并排,对节拍。规律性指向定时触发源,对时间戳是最快的定位法。
-
把第三方 SDK 默认当同步看待,除非它名字里带
Async或方法可await。 很多 SDK(含一些可观测性、支付、云厂商 SDK)只提供同步客户端。在 async 服务里用它们,默认就得包线程。 -
CPU 平 + 延迟尖 = 优先怀疑 I/O 阻塞,不是算力不足。 这组合几乎是「同步调用卡 loop」的签名。看到它,别去加机器加 CPU,去找那个攥着 loop 不让步的同步调用。
想再深一层
这次踩的,是 async 编程里一个有名字的老坑。想把它放进更大的脉络:
- Blocking the event loop:asyncio 官方文档专门有一节讲这个——loop 上不能跑阻塞代码,CPU-bound 和同步 I/O 都得用 executor 隔离。这是 async Python 的第一性约束,不是优化建议。
- Cooperative scheduling 的代价:协作式调度的好处是没有抢占、没有锁竞争;代价是它不抢占——一个不让步的任务,调度器拿它没办法。Go 的 goroutine、Erlang 的进程是抢占式的,没这问题;asyncio 不是。理解这个区别,就理解了为什么「一个同步调用能掐死全场」。
- Tail latency 与 P99:Dean & Barroso 的《The Tail at Scale》讲的就是为什么尾延迟比平均延迟重要得多,以及周期性干扰(后台任务、定时作业)如何专门污染尾部。这次的尖峰就是教科书式的「定时后台任务污染 P99」。
- 可观测性的反身性:监控系统消耗它所监控的资源——这是个普遍现象(采样开销、日志 I/O、指标拉取)。健康的做法是让观测路径和服务路径在资源上解耦:独立 loop、独立进程、独立配额。
这些不是高深理论,是写 async 服务的标准配套常识。这次的 bug 能发作,不是因为它新,是因为「同步调用必须隔离」这条铁律,在一个不起眼的看板模块里被漏掉了一次。
下一篇继续工程复盘子系列,挑一个同样「看起来无害、实则埋雷」的小切口接着拆。
回复关键词「阻塞自查」,我把这份《async 服务 event-loop 阻塞自查表》发给你:10 个闸 + 现成的 loop-lag 探针代码 + 「同步调用该不该 to_thread」判断流程图,一页能贴在你的 async 服务 review 清单旁边。
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.