Your KB Changed. The Search Index Didn't — Anatomy of a 9-Day Silent Desync | KB-Ops Deep Dive

KB-OPS DEEP DIVE. An engineering deep dive, not a methodology overview — how the source files and the live search index of an enterprise customer-service Agent silently fell out of sync for 9 days, how I traced it, and how to seal it. The higher-level methodology — which metric to track, which gates to clear before launch, how to test an AI system — lives in the Agentic AI in Practice series. 中文版:源文件改了,线上没变——一次 KB 静默失同步的 9 天.
Opening: the same line, new locally, stale in prod
I was working through a batch of test feedback with one very concrete lead: a customer asks "when does my refund arrive," and the live Agent replies with a line that makes you wince — "honestly, not yet as mature as big platforms like Taobao or JD."
I recognized that line. It had been fixed long ago — 9 days earlier, a phrase-cleanup commit had swapped it for a neutral "please be patient, it returns via the original channel." The change was right there in git log; I'd read the diff myself.
So I did the most basic thing possible: ran the service locally, curled the same query.
# Local — the freshly edited KB source
$ curl -s http://127.0.0.1:8000/api/ask -d '{"q":"when does my refund arrive"}' | jq -r '.answer'
Your refund returns via the original channel, 3-15 business days; bank card and Alipay differ slightly…
# Prod — the same query
$ curl -s https://<prod>/api/ask -d '{"q":"when does my refund arrive"}' | jq -r '.answer'
…honestly not yet as mature as big platforms like Taobao or JD, please be patient.
New locally. Stale in prod. The source changed; prod didn't.
Staring at those two outputs, my first instinct was wrong — "maybe this box didn't pull the latest code." But the code was identical; that commit was on both sides. The problem wasn't the source. The problem lived between the source and prod, in one step I'd always assumed was automatic and was in fact manual.
This post is the postmortem of that investigation. It isn't an isolated bug — it's a hole that any "humans edit a source file, machines read a derived index" architecture will dig. Of 33 test-feedback rows, 16 were different faces of this same root cause.

Why "source + derived index" systems are the easiest to desync silently
Any system that writes data into a source of truth and then derives an index/cache to read from carries a desync surface — and its most insidious property is that when it desyncs, nothing throws an error.
This Agent's retrieval is the classic two-stage shape: the knowledge base (KB) is a pile of markdown source files, human-maintained, git-versioned; live recall doesn't read those files, it reads an index loaded into Elasticsearch. The source is the truth, the index is a derived copy that exists for BM25 retrieval performance.
You almost certainly have one of these too, just under a different name: source data + an embedding vector store, a database table + a materialized view, object storage + a CDN cache, a config center + each service's local copy. The moment "where you write" and "where you read" are two stores, there's a sync link in between that someone or something has to walk. This post is about what happens when that link breaks — silently.
Three properties make this shape a desync breeding ground:
First, writing the truth ≠ writing the index. Edit markdown, commit, push, deploy — the smoothness of that path tricks you into believing "edited means live." But the index is a different store; it won't change just because the source did.
Second, reload looks successful. The system has a /api/kb/reload endpoint whose name and return value both whisper "I've reloaded the knowledge base." It returns 200 and an entry count. Everyone who'd used it assumed it propagated changes to prod.
Third, a desync throws no exception. Whether the index is stale isn't an error state to the system — it recalls as usual, returns an answer as usual, only that answer comes from a 9-day-old chunk. No 500, no alert, dashboards all green. A wrong answer and a right answer look identical — both are 200.
Together, these three mean a desync can live a long time, until someone — usually QA or a stubborn user — pins it down with a concrete query. The thing that pinned it this time was a batch of test feedback.
First wave: how 33 red rows clustered into 16 with one cause
QA delivered a sheet that day, 33 cases, each a query + current response + expected points. 33 rows red, looking like 33 independent bugs.
Fix them one by one and you'll be fixing forever — and fixing wrong, because most aren't their own bug. The first thing to do isn't to fix, it's to cluster: group the 33 by root cause and see whether they share an upstream.
I walked the timeline:
- Day 0, a phrase cleanup swapped "not as good as Taobao" for neutral wording.
- Day 5, QA ran tests, logged 33 cases — the "refund arrival" one still hit the old phrase.
- Day 7, a KB business review deleted 61 "don't-ingest" entries.
- Day 9, I started digging.
That Day-5 row was the sharpest: the source changed on Day 0, yet Day 5's test still hit the old one. My first instinct was "the phrase wasn't fully cleaned" — so I went to git first:
# Is the change even there? Yes. Day 0.
$ git log --oneline -S "Taobao" -- knowledge-base/
<commit> Day 0 · neutralize refund wording: drop the "not as good as Taobao" line
# And does local read the new one? Yes.
$ curl -s http://127.0.0.1:8000/api/kb/stats | jq '.layer1.refund.entries[] | select(.id|test("arrival"))'
{ "id": "l1_refund_arrival_time", "text": "returns via original channel, 3-15 business days…" }
Source changed, local parser read the new entry — so "the phrase wasn't cleaned" was ruled out. The whole upstream was correct; the problem could only be downstream, between source and prod. That gave us the opening comparison and locked the scope to "the live index was never rebuilt."
Investigating this class of problem, the time-saver isn't guessing what broke — it's walking the data flow and confirming, segment by segment, what's still correct: source correct, local parser correct, local recall correct, and the one remaining unconfirmed segment is the answer.

Once "stale index" was locked, which of the 33 it explained became clear. I split them four ways:
- Group A · direct desync victims (16): intent mostly classified right, KB has the right answer, but the live index is stale — either it hits an old chunk ("not as good as Taobao") or it falls back because a file's usable entries were emptied. These 16 share one cause.
- Group B · frontend streaming (9): a format issue, ndjson SSE deltas not merged on display. Unrelated to KB, separate issue.
- Group C · acceptable, recheck (3): re-verify after reindex.
- Group D · already correct (4): kept as happy-path regression fixtures.
Of the 33, the only thing needing my hands now was Group A's 16 — and those aren't 16 problems, they're one problem with 16 projections. That clustering step compressed the work from "fix 33 bugs" to "fix 1 root cause plus a few strays."
But when I went to fix that "1 root cause," it split into two.
Root cause one: the reload endpoint is a no-op against Elasticsearch
With "the index wasn't rebuilt" located, the next question was: why wasn't it? The flow clearly has a reload.
I read the implementation behind reload. The retrieval layer is pluggable — an in-memory backend, an Elasticsearch backend. The reload endpoint calls the current backend's ingest(). The Elasticsearch backend's ingest() looks like this:
# app/retrieval/elasticsearch.py
async def ingest(self, documents: list[Document]) -> int:
"""No-op for ES — use scripts/index_to_es.py for bulk indexing."""
return 0
It does nothing and returns 0.
This isn't a bug — it's a deliberate design decision that simply never made it into the process. Bulk indexing goes through a separate script, scripts/index_to_es.py --recreate, which drops the old index and rebuilds from source. ingest() is a no-op because the author didn't want an HTTP request to trigger a full rebuild (a few seconds where the index is unqueryable). Perfectly reasonable.
The problem is that the reload endpoint's name and return value tell a white lie. It returns 200 and a normal-looking entry count (from the in-memory layer's stats), so everyone calling it assumes the index updated. The command that actually updates the index lives in a script, and the rule "after editing the KB you must run this script by hand" was in no doc, no QA flow, no KB checklist.
So both the Day-0 and Day-7 KB edits committed, deployed, and reloaded successfully — and not one entry reached the live index.
A no-op that returns 200 is far more dangerous than a bug that throws. Exceptions get looked at; 200s don't get checked.
Root cause two: the parser reads half the file
If that were the only root cause, the fix is clean: run one reindex. But when I rebuilt the index locally and recounted usable entries per category, one file came back at zero — coupon-points, where high-frequency questions like "how do I use my points" had not a single usable answer.
That surfaced the second, more hidden root cause.
Each KB markdown file has two sections: ## xxx policy rules up top, a numbered rule list; and ## AI answer templates below, the Q&A entries retrieval uses. The parser only recognizes the latter:
# app/retrieval/parser.py _parse_layer1
m = re.search(r"## AI 回答模板\s*\n(.+?)(?=\n## |\Z)", text, re.S)
if not m:
return [] # no "AI answer templates" section = zero entries for this file
entries = _split_entries(m.group(1))
The ## policy rules section above actually held 20-plus good answers — "refund arrival 2," "refund arrival 3," "pending refund 2" — but because they weren't under ## AI answer templates, the parser couldn't see them at all.
Normally that's not fatal, because each file's ## AI answer templates has a few entries. But when the Day-7 review deleted 61 "don't-ingest" entries, it deleted by entry — nobody realized some files' ## AI answer templates section would be emptied. Here's the usable-entry inventory after the delete:
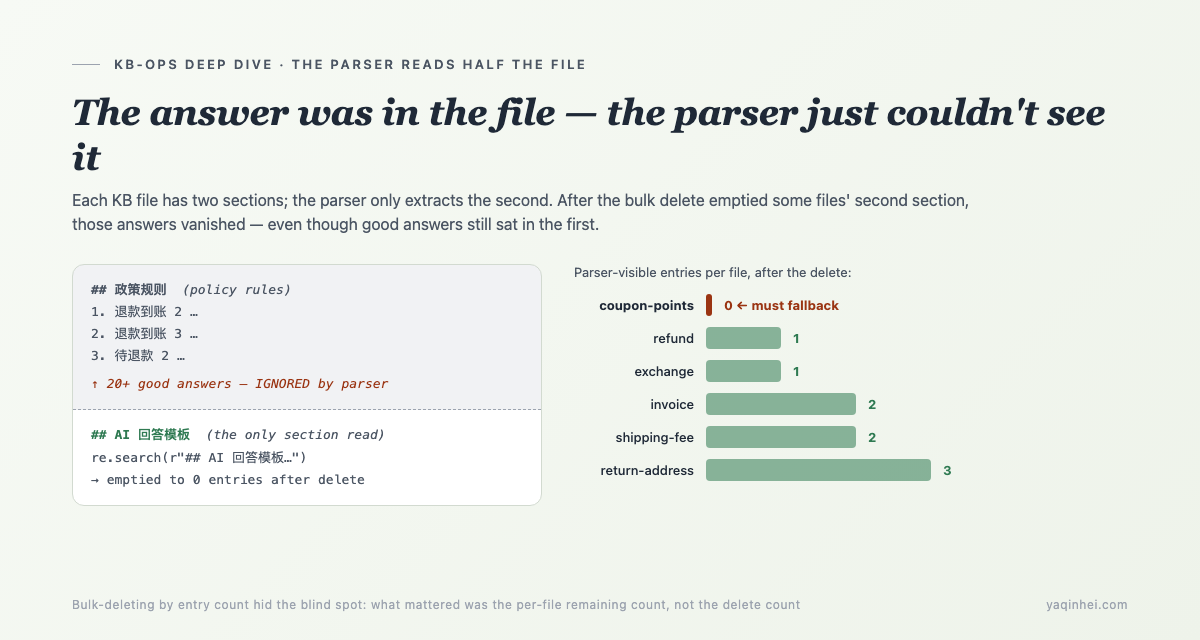
| KB file | parser-visible entries | consequence |
|---|---|---|
| coupon-points | 0 | "how do I use points" must fall back |
| refund | 1 | "refund arrival" series → hits the stale index's wince line |
| exchange | 1 | "can I exchange shoes that don't fit" mismatched |
| invoice | 2 | "I need an invoice" mismatched to a coupon template |
| shipping-fee | 2 | "who pays return shipping" mismatched to no-reason return |
| return-address | 3 | "what's the return address" answered only partially |
That coupon-points zero is especially nasty: its ## policy rules section plainly held good answers on points usage and coupon lookup, but the parser couldn't reach them, so "how do I use points" dropped straight into fallback. The answer was in the file; the system said it didn't know.
Two faults stacked: why "silent for 9 days" instead of "errored on the spot"
Apart, neither root cause is fatal; stacked, they manufactured a 9-day silent window.
Lay the timeline flat and it's clear:

- Day 0, phrase edited → because of root cause one (reload is a no-op), it never reached the index, but nobody knew, because nothing errored.
- Day 7, 61 entries deleted → because of root cause two (parser reads half the file) some files were emptied, but that didn't reach the index either, again because of root cause one.
- From Day 0 to Day 9, prod kept serving the pre-Day-0 stale index — old phrasing, old chunks, untouched, to real users.
With only root cause one, someone eventually runs a reindex and the old phrase is gone. With only root cause two, the emptied files at least recall something from the old index. Stack the two: the source is changing, the index is frozen, and the freezing itself is invisible. You think you shipped; you didn't — and no signal tells you the difference.
That's the shape worth remembering about this class of bug: it isn't "a thing broke," it's "an update that should have happened didn't, and its not-happening leaves no trace."
The fix: lift the entries + rebuild the index + measure
The fix has two layers, both simple, but the order matters.
Layer one: lift the still-applicable entries from the ## policy rules section into ## AI answer templates, so the parser can see them. Prioritize coupon-points (from zero), refund (lift the "refund arrival" series), invoice, shipping-fee. Watch one trap: the old phrase edited on Day 0 was deleted on Day 7 — don't resurrect it while lifting entries; keep neutral wording, never let "not as good as Taobao" back.
Verify locally that the parser actually picked them up:
$ curl -s http://127.0.0.1:8000/api/kb/stats | jq '.by_subcategory'
{
"layer1/coupon_points": 7, # 0 → 7
"layer1/refund": 8, # 1 → 8
"layer1/return": 4, # 1 → 4
"layer1/invoice": 5 # 2 → 5
}
Layer two: rebuild the index — this is the step that actually pushes changes live:
$ uv run python scripts/index_to_es.py --recreate
This command has a side effect: a few seconds where cs_knowledge_base is unqueryable during the rebuild. On prod ES, confirm with people first and pick a low-traffic window. That side effect is exactly why ingest() was a no-op to begin with — the trade-off was just never written down or carried by the process.
Then turn the 33 into a yaml fixture, hit /api/ask for each, diff the expected points. Group A's 16 measured out as:
- 4 fully fixed (hit new templates, including "refund arrival time" with no wince line)
- 4 partially fixed (content right, but cross-layer hits, imprecise wording)
- 2 intent-mismatched but answer acceptable
- 6 still broken — and those 6 are no longer about desync
Shippable user-perceivable improvement: 10/16. That number is itself an honest signal: reindex fixed the part the "desync" cause could explain; the rest is a separate batch of pre-existing problems the desync had been covering up.
Plug one hole, the next appears: the real causes of the remaining 6
Once the big desync hole was sealed, the water dropped and exposed a few rocks that had been there all along, just submerged. This is the recurring plot when investigating this kind of system: you fix the most upstream cause and the downstream reveals its own, finer causes.
The remaining 6 had distinct causes, none still KB×index desync:

First, intent-rule ordering. "Where's my return in the review process" should be return_status, but in the rule table return_request came first and a broad return pattern stole it. "Who pays return shipping" likewise got grabbed by return_request before reaching shipping_fee. The fix: add colloquial patterns to return_status (cover "where in the review / which step," without requiring the literal word "review") and move shipping_fee ahead of return_request:
# app/intent/rules.py
"return_status": [r"退.*审.*到哪", r"退.*审.*哪一?步", r"退.*审.*几天"],
# reorder: shipping_fee must precede return_request,
# else r"退货" steals the compound "return shipping"
After that, "who pays return shipping" got both the intent right and a full hit on the newly written "who bears return shipping" template.
Second, a no-KB intent caught by cross-layer BM25. "What do I do if payment fails" and "how do I cancel an order" have no layer-1 KB at all; retrieval had BM25 grab a nearest neighbor from another layer — "payment failed" hit "refund proof lookup," "cancel order" hit "self-service invoicing." Wrong answer, but since there was an answer, still a 200. The fix: give these intents a whitelist that short-circuits to fallback before retrieval, keeping them out of the BM25 roulette:
# app/dialog/router.py
INTENTS_WITHOUT_KB = frozenset({"payment", "order_cancel"})
if intent in INTENTS_WITHOUT_KB:
return _fallback_events() # skip retrieval, go straight to a safe fallback
After that, neither mishits; both cleanly fall back.
Third, layer-3 emotion not caught. "I want to escalate to a manager" should rise to layer 3, but classification didn't route it there. Adding escalate.*manager / escalate.*supervisor / escalate to patterns to escalation got the intent right — but this one exposed a deeper, independent environment problem: all layer-3 intents were returning 500 at the time, rooted in the LLM generation path's gateway connection, unrelated to my KB fix, tracked separately.
Note this third detail — it's the step in this investigation I'm most pleased with, not because it got fixed, precisely because it didn't. After adding the rule I found /api/ask still 500'd, but I didn't go change my rule on the spot — I first confirmed "are all layer-3 intents 500'ing." Once confirmed — complaint_quality, complaint_service all 500 — it meant the problem wasn't my change, it was the shared LLM gateway. Had I rushed to "make this one pass," I'd likely have hacked the rule and buried an environment problem disguised as a code problem even deeper.
Put both waves of fixes on one ledger and the residual cases' evolution tells the story — wave one (reindex) solved "desync," wave two (intent routing) solved what it had masked:
| Case | After wave 1 (reindex) | After wave 2 (intent routing) |
|---|---|---|
| Return-review status | intent wrong (stolen by return_request) | intent right (return_status), answer pending a dedicated template |
| Return shipping | intent wrong (stolen by return_request) | fully fixed (intent + answer both right) |
| Payment failure | mishit "refund proof lookup" | clean fallback |
| Cancel order | mishit "self-service invoicing" | clean fallback |
| Escalate to manager | unknown, not caught | intent right (escalation), layer-3 gateway 500 tracked separately |
Cumulative on Group A's 16: 4 fully fixed + 3 partial + 5 intent-right but limited by KB/environment + 4 to follow up = 14 user-perceivable improvements, of which 10 shippable now. Not one number is "all green" — and that's exactly the honest takeaway: plug one root cause and you surface the next layer of them, not the finish line.
Why the dashboard was all green while this rotted for 9 days
No standard monitoring catches this kind of desync — because every link in it, viewed alone, is "normal."
The reload endpoint returns 200, not an error. Index recall returns an answer, not an error. Latency normal, error rate zero, health checks all green. The thing that would reflect the problem is "is this answer right" — and right-or-wrong is a semantic judgment, not any system metric. This is exactly what the launch-gate post hammers on: approved (nothing errored at the system level) ≠ correct (the answer is actually right).
Only one thing could have caught this desync: end-to-end content regression — a fixed set of "query → expected points" cases, hit against prod periodically, answers diffed. Which is exactly what QA's 33 cases did, and exactly why this class of case must be turned into fixtures and put in CI, not left to occasional manual checks. I singled this out in the dual-track testing post: an AI system's "is it correct" track and its "is the service healthy" track are two different things, and the latter being all-green won't stop the former from being all-wrong.
In one line: this wasn't monitoring under-reporting, it was that no monitor was watching "is the answer right" at all. The desync merely exploited that blind spot.
10 gates you can add to your own KB pipeline this week
Distilled into directly copyable moves — applicable to any "source file + derived index" system:
- Give the "edit source → rebuild index" link a step that can't be skipped. Either the reload endpoint truly triggers a reindex, or CI forces a rebuild on KB changes — don't leave it as "some script, remember to run it by hand."
- CI gate: run
index_to_es.py --dry-runon KB changes, assert the parser yields more than zero entries. This alone blocks "some file has 0 AI templates" before merge. - Set a "visible entries ≥ 1" assertion per KB category, in the health check or CI — turn "the answer is in the file but the parser can't read it" into a state that alarms.
- Any no-op that returns 200 should either be removed or made to tell the truth. If reload doesn't reindex, don't return an entry count that implies it did; return "index unchanged, run X."
- Fixture end-to-end content regression and put it in CI. A set of "query → expected points" hit against prod periodically, answers diffed. This is the only net that catches semantic desync.
- Make local-vs-prod comparison a one-liner. During the investigation I curled both sides by hand — script it, so any "did my change actually ship" doubt is one command away.
- If the source file is sectioned, the parser must either cover all sections or explicitly declare which it reads — and alarm when that section is empty, instead of silently returning an empty list.
- When bulk-deleting entries, review by "how many visible entries remain per file," not by "how many were deleted." The deletion blind spot is in the remaining count, not the delete count.
- Write the side effects of destructive ops like reindex into a runbook (unqueryable during rebuild, pick low traffic, needs confirmation) — don't let a reasonable technical trade-off become a process gap just because it wasn't written down.
- After fixing one root cause, assume it masked others. Re-cluster the residual cases; don't assume "the big plug fixed everything" — lowering the water surfaces new rocks.
Going deeper
What I stepped in is an old problem with names. If you want to place it in a bigger context:
- The dual-write problem: writing one piece of data to two stores (source + index) with no transaction guaranteeing consistency — a recurring class of distributed-systems pitfall.
- Cache invalidation: Phil Karlton's "there are only two hard things in computer science: cache invalidation and naming things" isn't a joke. A derived index is essentially a cache; a desync is a cache that didn't invalidate.
- CQRS / read-model rebuild: in architectures that split the write model (source) from the read model (index), rebuilding the read model is a first-class citizen — it must have an explicit, observable, replayable rebuild flow, not a manual script.
- Elasticsearch zero-downtime reindex via aliases: point an alias at a new index, rebuild in the background, then flip — eliminating the "unqueryable during rebuild" side effect, and with it the very reason the step was made manual.
None of these are deep theory — they're the standard toolkit for the "derived data" pattern. This bug survived 9 days not because it was novel, but because that toolkit wasn't installed.
The next post returns to the methodology spine, turning the abstract "deterministic workflow" into a readable code skeleton: what a real, money-moving L2 refund workflow actually looks like.
Send me the keyword "SYNC KIT" and I'll send the Source-plus-Derived-Index Desync self-check sheet: the 10 gates + a local/prod comparison script template + a KB health-check assertion list, one page to pin beside your KB maintenance flow.
(Channels in the footer — X or email both work.)
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.