4 小时→30 分钟:独立开发者用 Claude Code 自动化公众号排版的踩坑实录
我运营一个技术公众号。每次写文章的流程是这样的:花一小时刷 HackerNews 找选题,花两小时写初稿,花 45 分钟用 HTML 画配图然后截图,最后花 15 分钟跟微信编辑器的排版搏斗。
一篇 2000 字的文章,4 个小时没了。
作为一个开发者,我对重复劳动有一种本能的过敏反应。于是我决定:把整个流程自动化掉。
这篇文章记录了我从第一行 Python 脚本到做出一个完整产品的全过程——技术选型怎么做的、架构怎么设计的、微信 API 有多少坑、Claude Code 在开发过程中帮了什么忙。如果你也在做独立开发或者运营自媒体,希望能给你一些参考。
一、起点:Obsidian + Python 脚本
最早的版本非常粗糙。
我的内容都在 Obsidian vault 里管理,文章写成 Markdown,frontmatter 里记录选题评分、发布状态这些元数据。配图不用 Figma 也不用 Canva——我发现用 HTML + CSS 画信息图,再用 Playwright 截图成 PNG,效果比任何在线工具都好,而且完全可编程。
发布环节用一个 Python 脚本搞定:
# publish-wechat.py 的核心逻辑
def main():
token = get_access_token()
thumb_media_id = upload_thumb(token, cover_path) # 上传封面
image_urls = {}
for key, path in image_map.items():
image_urls[key] = upload_image_for_content(token, path) # 上传配图
html = build_html(image_urls) # 拼装 HTML
create_draft(token, thumb_media_id, html) # 创建草稿
这套脚本能用,但有几个明显的问题:
- 选题全靠手动:我得自己刷 HackerNews、Reddit、Twitter,判断哪个话题值得写
- 写作没有辅助:从大纲到成稿全是纯人肉
- 每篇文章的脚本都是硬编码:换一篇文章就得改路径、改图片映射、改 HTML 模板
- 只有我能用:没有 UI,别人没法上手
但这个阶段最大的收获是:我验证了整个流程是可以自动化的。微信公众号的 API 虽然坑多,但基本够用——能上传图片、能创建草稿、能通过 API 控制大部分发布流程。
二、从脚本到产品:14 阶段 Pipeline
当我决定把这套东西做成一个正经产品时,第一个问题是:怎么建模这个创作流程?
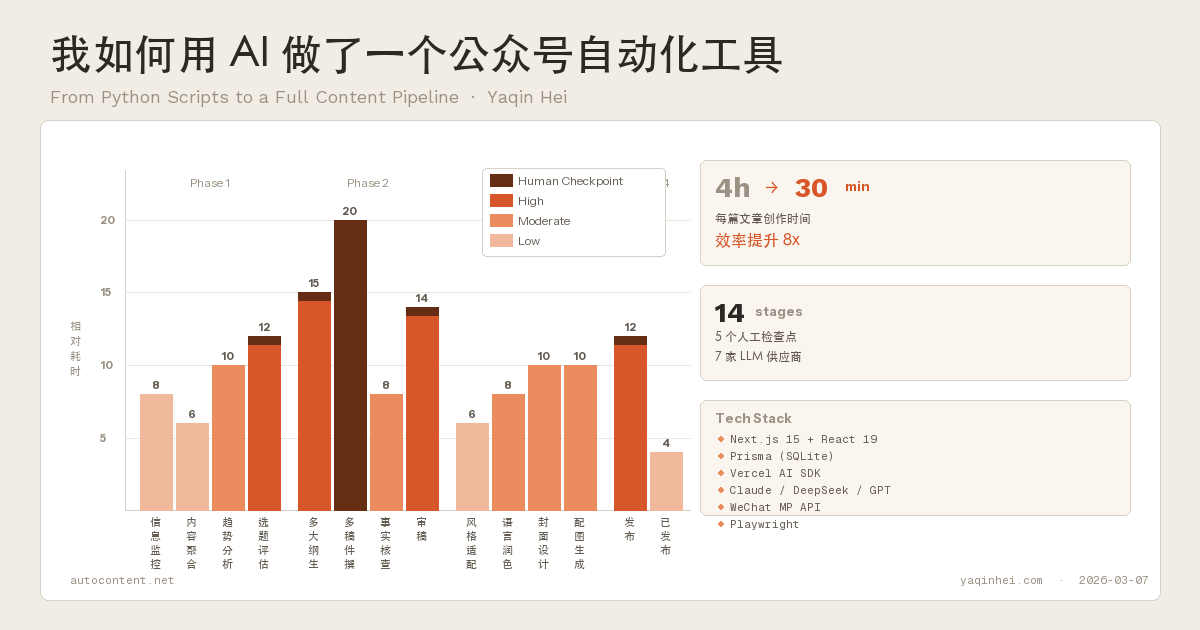
一篇文章从想法到发布,其实是一条流水线。我把它拆成了 14 个阶段:
信息监控 → 内容聚合 → 趋势分析 → 选题评估 → 多大纲生成
→ 多稿件撰写 → 事实核查 → 审稿 → 风格适配 → 语言润色
→ 封面设计 → 配图生成 → 发布 → 已发布
每个阶段都有明确的输入输出和类型定义:
// lib/pipeline/stages.ts
export const PIPELINE_STAGES: StageDefinition[] = [
{
id: "topic_evaluation",
label: "Topic Evaluation",
labelZh: "选题评估",
type: "hybrid", // auto | manual | hybrid
humanCheckpoint: true, // 需要人工确认才能进入下一阶段
requiredFields: ["title"],
producesFields: ["heatScore", "matchScore", "competitionScore"],
},
{
id: "multi_outline",
labelZh: "多大纲生成",
type: "hybrid",
humanCheckpoint: true,
parallelCount: 3, // 同时生成 3 个大纲供选择
},
// ... 14 个阶段
];
这个设计有几个关键决策:
为什么是状态机? 因为内容创作不是一个线性过程。你可能写到一半发现选题不对想回头,可能审稿后觉得要大改。状态机让每篇文章都有明确的"在哪个阶段",前进、后退都有据可查。
为什么要 5 个人工检查点? AI 辅助不等于 AI 替代。选题要人确认(不然 AI 会给你推荐一堆"10 个你不知道的 Python 技巧"),大纲要人选(同时生成 3 个,挑最好的),初稿要人审(注入个人观点和真实经历),审稿要人过(最终质量把关),发布要人点(确认排版没问题)。
为什么要 multi-outline 和 multi-draft? 这是我从实践中学到的:让 AI 生成一个大纲然后硬改,不如让它同时生成 3 个,你从中选一个最接近你想法的。成本几乎不变(几分钱的 API 调用),但决策质量高很多。
技术选型
| 技术 | 选择 | 理由 |
|---|---|---|
| 框架 | Next.js 15 + React 19 | App Router + Server Actions,全栈一把梭 |
| 数据库 | SQLite + Prisma | 独立开发够用,零运维,数据就是一个文件 |
| AI 接入 | Vercel AI SDK | 统一的 streaming 接口,provider 可插拔 |
| 样式 | Tailwind v4 | 不解释 |
| 部署 | Vercel | git push 就上线 |
LLM 这块我做了一个 provider registry,支持 7 家模型供应商:
// lib/ai/registry.ts — 按优先级自动选择可用模型
const providerDefaults: [string, string][] = [
["deepseek_api_key", "deepseek:deepseek-chat"], // 便宜大碗
["siliconflow_api_key", "siliconflow:Qwen/Qwen2.5-72B-Instruct"],
["google_api_key", "google:gemini-2.5-flash"],
["openai_api_key", "openai:gpt-4o-mini"],
["anthropic_api_key", "anthropic:claude-sonnet-4-20250514"],
// ...
];
为什么不锁死一个模型?因为成本和可用性。写大纲用 DeepSeek(便宜),润色用 Claude(质量高),用户也可以按阶段配置不同模型。Vercel AI SDK 的 createProviderRegistry 让这件事变得非常简单——所有模型共享同一个 streaming 接口,切换模型只是改一个字符串。
三、微信公众号 API 踩坑实录
如果这篇文章只能保留一节,我选这节。因为这些坑你在官方文档里根本找不到。
坑 1:所有样式必须内联
微信公众号的 HTML 渲染引擎堪比 IE6。它会:
- 完全忽略
<style>标签 - 完全忽略
class属性 - 不支持
<pre>标签(代码块直接渲染成一坨)
所以你的每一个 HTML 元素都必须写内联样式:
<!-- 在微信里不可以 -->
<p class="intro">你好</p>
<!-- 必须这样 -->
<p style="margin:0 0 1em 0;padding:0 0.5em;font-size:16px;line-height:1.8;color:#333;">你好</p>
我在服务端做了一个 markdownToWechatHtml() 转换器,把 Markdown 渲染成微信能正确显示的 HTML。每种元素都有对应的内联样式模板。
坑 2:标签之间的空白会变成幽灵元素
这个坑最隐蔽。如果你的 HTML 里 <li> 和 <li> 之间有换行:
<ul>
<li>第一项</li>
<li>第二项</li>
</ul>
微信会把那个换行解析成一个空的列表项,导致列表中间出现莫名其妙的空行。解决方案很暴力:
html = html.replace(/>\s+</g, "><"); // 干掉所有标签间空白
坑 3:中文编码的 JSON 陷阱
Python 的 requests.post(json=...) 会把中文自动转成 \uXXXX 编码。问题是,微信 API 按编码后的字符串长度来校验标题——一个中文字变成 6 个字符,标题很容易就超限了。
# 错误:中文被转义,微信觉得标题太长
requests.post(url, json=payload)
# 正确:手动 dump,保留中文原文
body = json.dumps(payload, ensure_ascii=False).encode("utf-8")
requests.post(url, data=body, headers={"Content-Type": "application/json; charset=utf-8"})
坑 4:封面上传失败会静默吞掉
微信的 add_material 接口上传封面图,如果失败了不会抛异常,只是返回一个没有 media_id 字段的响应。如果你不显式检查,后面的 create_draft 调用也不会报错——它只是静默地什么都不做,你的草稿箱里永远不会出现那篇文章。
// 必须显式校验
const thumbMediaId = await uploadThumb(token, coverPath);
if (!thumbMediaId) {
throw new Error("封面上传失败,终止发布");
}
这个 bug 我排查了两个小时。教训是:微信 API 的错误处理永远不要信任,每一步都要显式校验返回值。
坑 5:IP 白名单
公众号 API 需要在后台手动添加服务器 IP 到白名单。如果你用 Vercel 部署,IP 是动态的——每次部署可能换 IP。目前的解决方案是在本地或固定 IP 的服务器上跑发布脚本。
四、用 Claude Code 开发的真实体验
整个项目的开发我重度使用了 Claude Code(Anthropic 的 CLI 编程工具)。说几个真实感受。
上下文理解能力很强。 我跟它说"把 pipeline 的 multi-outline 阶段改成同时生成 3 个大纲,用 Promise.all 并行调用 AI",它能理解 pipeline 的上下文、找到相关文件、改对地方。不需要一行行指挥。
重构效率极高。 有一次我要把所有的 Settings 查询从 findUnique 改成批量的 findMany,涉及十几个文件。Claude Code 用了大概 30 秒就改完了,而且没有遗漏。
微信 API 的坑它也踩。 有趣的是,Claude Code 在帮我写微信发布逻辑时也犯了"不校验返回值"的错误——它生成的第一版代码里,封面上传后没有检查 media_id 是否存在。AI 也会写出 AI 的坑。但好处是,你发现问题后告诉它一次,它后面就不会再犯。
从 0 到 MVP 大概用了两周。 如果纯手写,这个体量的项目(14 阶段 pipeline、多模型支持、微信/博客/Twitter 三平台发布、完整的 CRUD 和编辑器)至少要一两个月。Claude Code 把大量的样板代码生成工作接管了,我可以把精力集中在架构设计和业务逻辑上。
五、从 Side Project 到产品化
做完之后我意识到,这不只是一个自用工具。很多公众号运营者都有同样的痛点——选题难、写作慢、排版烦、多平台分发累。
于是我决定把它产品化,做成了 AutoContent。核心就是把上面说的这套 14 阶段 pipeline 包装成一个友好的 Web 界面:选题推荐、AI 辅助写作、自动配图、一键发布到公众号。
几个产品化过程中的决策:
Landing page 和 App 分开部署。 Landing page(autocontent.net)用 Next.js 静态导出 + Cloudflare Pages,速度快、成本零。App(app.autocontent.net)跑在 Vercel 上,需要服务端能力。
先做 waitlist,不急着开放。 公众号发布涉及 API 密钥、IP 白名单等配置,不是注册就能用的。先收集需求,验证 PMF,再决定怎么简化 onboarding。
SEO 先行。 在 autocontent.net 的 blog 上写了几篇教程文章(比如"如何用 AI 自动化公众号内容创作"),目标是抢占 公众号自动化、AI 内容创作 这些长尾关键词。独立开发者没有营销预算,内容 SEO 是最实在的获客方式。
六、独立开发者的几点反思
做完这个项目,有几个感悟。
第一,先用脚本验证,再做产品。 如果我一上来就搭 Next.js 项目写 CRUD,很可能在微信 API 的坑里浪费大量时间。先用 Python 脚本跑通核心流程,确认可行性,再考虑产品化。这个顺序很重要。
第二,AI 辅助开发改变了"值不值得做"的判断。 以前一个人做这种体量的全栈项目,时间成本太高,ROI 算不过来。但有了 Claude Code,两周就能出 MVP,试错成本大幅降低。很多以前"想法不错但没精力做"的项目,现在变得可行了。
第三,自动化的价值不是替代人,是释放时间。 这套系统不会帮我"想"出好文章——选题的判断力、个人经验的注入、写作风格的把控,这些仍然 100% 依赖人。它做的是接管那些重复性的工作:信息收集、初稿生成、排版适配、平台发布。省下来的 3 个小时,我可以用来做更有深度的思考和创作。严格按 L0-L3 Agent 分级框架 来说,这套 pipeline 还停在 L0/L1 的固定流程自动化,并不是能自主规划的 Agent——但对这个场景,够用就好。
如果你也在运营公众号,被选题和排版折磨得够呛,可以直接试这几个工具:
- AI 写公众号文章 — 选题、写稿、配图、发布 30 秒
- 公众号 AI 排版 — Markdown 贴进去,公众号 HTML 拷出来
- Markdown 转公众号 — 程序员写公众号专用
- 爆款标题生成器 — 7 种模板各出 1-2 个候选
- 免费 AI 写作 — Claude/GPT/Gemini 全模型支持
或者直接进 AutoContent 把以上能力一站打包。
如果你是独立开发者,对 AI 辅助全栈开发的实践感兴趣,欢迎在评论区交流。我会持续分享这个项目的迭代过程和踩坑记录。
参考资料
相关阅读
- 创始人手册:打造 AI 原生初创公司 — AI 原生时代的创业方法论
- 零售企业 Agentic AI 落地手册(三) — Agentic AI 落地实战
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.