微信 AI 替用户下单那天,1000 万商户的小程序集体过期了

这是《微信 AI 来了:1000 万商户的 agent 重构三问》系列的第三篇,也是最硬的一篇。 前两篇问「怎么被找到」(流量黑盒)和「怎么留住客户」(关系保卫);这一篇只回答一个问题——你的小程序到底该怎么重构。 背景一句话:微信小微 Agent 已经在内测,左上角常驻,能在对话、文章、视频号、小程序里发起,跨约 1000 万商户搜索、比价、下单、支付。能力仍在合规 review,对接契约没定死——所以这一篇教你按「模式」设计,不赌某个具体 API。
开篇:那个把页面原封不动搬进对话的团队,三周后推倒重来
做零售 agent 这些年,服务过 50 多个产品域、Fortune 500 体量的客户,我见过最贵的一个错,是一个团队听说微信要开放 AI 接入,连夜把现有小程序的页面流,一个按钮一个按钮地照搬进了对话框。
商品列表页 → 做成一张「商品列表卡片」。规格选择页 → 做成一张「规格卡片」。地址页 → 一张「地址卡片」。他们以为这就叫「接入 Agent」。
跑起来当天就崩了。用户说「来杯少糖的拿铁」,AI 不知道该调哪张卡——因为这些卡片是按页面组织的,不是按用户想干的事组织的。AI 面对的是一堆「页面的复刻」,而不是「我能帮你完成的任务」。三周后整个 skill 推倒重来。
这就是重构的第一性问题,也是这一篇要拆的东西。微信这次开放的本质,不是给你的小程序加一个聊天框——是把小程序从「被用户手动点击的页面集合」,逼着升级成「可被 AI 理解、调用、操作的服务能力集合」。 这两个东西的架构,几乎没有一行是共用的。
先看一眼卡兹克(拿到内测号的那位)实测时发生了什么:他让小微订电影票,「它列出 5 个小程序,选了第一个猫眼,自己操作到选影院那一步,把剩下的交给我」。
读懂这句话:AI 替用户选了第一个,剩下 4 个商户当场从这次交易里消失了。 而被选中的那个,还得保证 AI 操作你的小程序时不会中途卡死、不会下错单、不会把价格算错。重构做得好不好,直接决定你是「那第一个」还是「消失的四个」。
下面是完整的分层重构图,后面每一节拆一层。

一、别把页面搬进对话——从「用户目标」反推 SKILL
先把结论摆桌面上:重构的起点不是你的页面,是用户的一句话。
旧小程序的组织单位是「页面」,新 agent 的组织单位是「用户能完成的一个任务」。微信开发模式里管这个任务包叫 SKILL——一个可被 AI 调用的业务能力包。一个 SKILL 对应一个「完成定义」清晰的任务:完成一次点单、成功取一次号、新增一条待办并展示列表。
怎么拆 SKILL?倒着拆。先列用户会怎么开口:
- 「来杯少糖的拿铁」→ 点单 SKILL
- 「我家附近有什么好吃的」→ 模糊推荐 → 仍然落到点单 / 找店 SKILL
- 「我那个订单到哪了」→ 订单查询 SKILL
- 「帮我约周六的洗牙」→ 预约 SKILL
每一句话背后,是一个有明确终点的任务,不是一个页面。拆 SKILL 的铁律就一条:如果你说不出这个 SKILL「完成」的那一刻是什么样,它就不该是一个 SKILL。 「商品列表 SKILL」不成立,因为列表本身不是用户的终点;「完成支付下单」成立,因为它有明确的成功态。
SKILL 也不是越多越好。卡兹克扒出来的官方 skill 文档里,触发条件是按场景收口的——本地生活下单、打车、电影票、查询、充值各一类,而不是按页面碎成几十个。太碎,AI 选不出来;太粗,一个 SKILL 包打天下,参数和状态全糊在一起。按「用户能独立完成的一件事」切,是目前最稳的粒度。
这里有个反直觉的点值得说:重构不是把小程序重写一遍,是在现有业务后端之上,加一层「写给 AI 看」的能力声明。 你的商品、库存、订单、支付服务一行都不用动,要新建的是上面那层 SKILL + 接口声明 + 卡片组件。想清楚这个,团队的恐慌会少一半。
二、自动模式探路、开发模式拿结果——别一上来就重写
结论先行:90% 的小程序应该先用自动模式把「能不能被 AI 发现」验证掉,再决定哪条高价值链路值得上开发模式。
微信给了两种接入模式,很多团队第一反应是「那肯定上最强的开发模式」——这是第二贵的错。两种模式的取舍长这样:

自动模式:你授权平台在提审时读你的小程序源码,平台分析页面结构和交互路径,让 AI 直接操作你现有的页面。价值是接入快、几乎零开发,适合先回答一个生死问题——「我的服务能不能被 AI 发现、搜索、浏览」。内容型、查询型、轻服务的小程序,自动模式可能就够了。
开发模式:你把业务能力封装成标准化 SKILL,显式声明接口、参数、输出、组件、业务规则,让 AI 更确定地调用。它要开发、调试、评测、过审,但换来强约束——适合点单、支付、预约、取号、售后这种多步骤、强一致性的交易闭环。
落地节奏我建议切成四个阶段,别跳:
- 盘点与优先级——把小程序里的高频服务列出来,按「用户价值 × 风险 × 改造成本」排序。
- 自动模式试接入——开放低风险页面,盯一个指标:AI 能不能正确发现并操作你的核心路径。
- 开发模式样板间——挑一个闭环场景(点单 / 取号 / 待办)做 SKILL,把接口、卡片、半屏页、支付全跑通。一个就好。
- 评测、灰度、扩展——积累评测集和监控,再逐步铺更多场景。
为什么强调「先探路」?因为契约还没定死。微信现在是内测,API、提审标准、入口命名、开放节奏都可能改。这个阶段把工程预算 all-in 到开发模式重写,是在赌一个还会变的接口。 自动模式探路的成本低到可以当「期权」买——花小钱先卡住「被发现」这个位置,等契约稳了再决定哪里值得重投。
三、AI 生成的参数,一个字都不能信
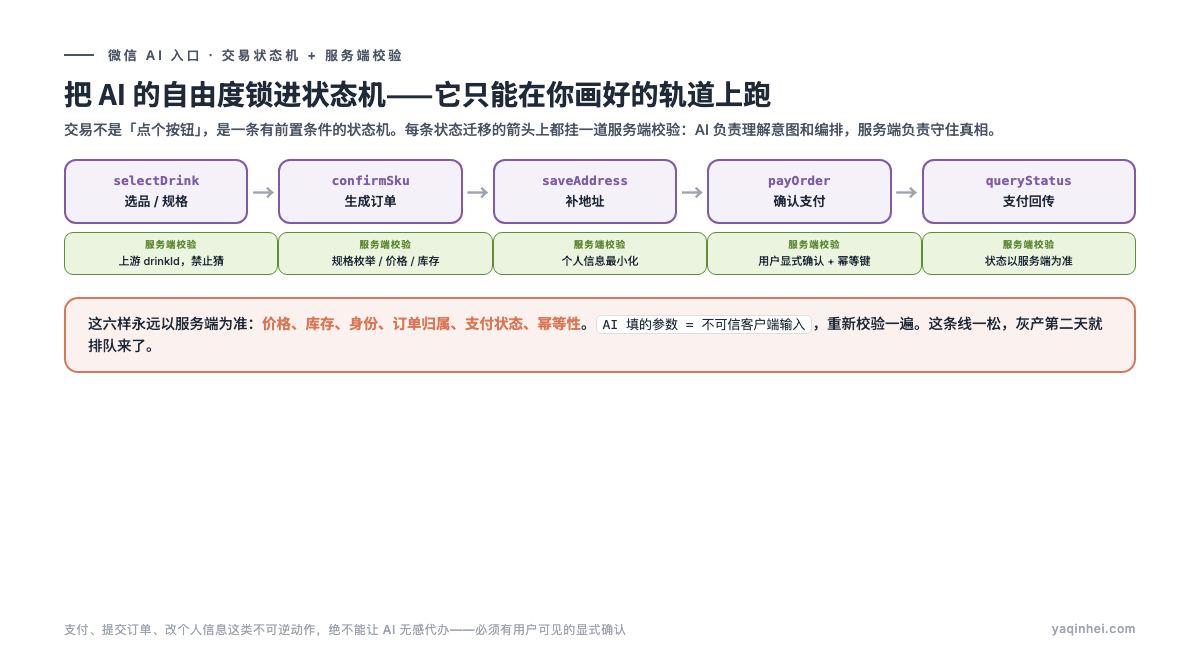
这是整篇最重要的一节,也是新手最容易省的一节:AI 填给你的任何参数——商品 ID、价格、规格、数量——服务端都必须当成「来自不可信客户端的输入」重新校验一遍。
为什么?因为交易不是「点个按钮」,是一个状态机:选品 → 选规格 → 生成订单 → 补地址 → 确认支付 → 支付状态回传。每一步都有前置条件,每一步 AI 都可能填错或者干脆编造一个值。
最危险的几种翻车,和对应的兜底策略,我整理成一张表——这张表你可以直接贴到团队的设计评审里:
| 风险场景 | 它怎么发生 | 兜底策略 |
|---|---|---|
| AI 编造商品 / 订单 ID | 自然语言里没有 ID,AI 为了把接口调通,凭空「猜」一个 | 只允许使用上游接口返回的 ID;上下文缺失就反问,绝不放行 |
| 价格被改 | AI 或组件把价格当参数传上来,传了个错的 / 旧的 | 价格一律由服务端按商品、规格、活动重新算,传上来的价格只用于展示比对 |
| 重复支付 | 同一个订单 AI 连续触发两次 payOrder | 订单幂等键 + payOrder 串行 + 服务端状态机,已支付的订单拒绝二次发起 |
| 越权读取 | AI 拿着 A 用户的 session 去查 B 用户的订单 | 后端用 openid / unionid / 你的账号体系校验资源归属,不信客户端传的身份 |
| 接口「假成功」 | 接口失败了,但 AI 把它叙述成「已经帮你下好单啦」 | 接口必须返回结构化的 isError + 错误码 + 可恢复动作,禁止 AI 自行脑补成功 |
记住一句话就够了:AI 负责理解意图和编排,服务端负责守住真相。 价格、库存、身份、订单归属、支付状态、幂等性——这六样,永远以服务端为准。这条线一旦松,灰产第二天就排队来了。
四、mcp.json 是你写给 AI 的「合同」
开发模式里,AI 不是凭感觉调你的接口,它读两个文件来决定怎么调:
- SKILL.md——业务 SOP。告诉 AI 这个场景的流程、接口依赖、禁止事项、歧义怎么处理、意图怎么分流。
- mcp.json——能力声明。定义每个 API 的名称、描述、输入输出 Schema、绑定哪个组件、关联哪个页面。
这两个文件就是你和 AI 之间的合同。合同写得含糊,AI 就自由发挥;合同写得严丝合缝,AI 就老老实实在框里走。看一段真实的 confirmSku 声明(结构来自微信官方示例项目 WeStoreCafe,细节按你的业务改):
{
"apis": [{
"name": "confirmSku",
"description": "确认规格并生成订单;必须在 selectDrink 成功后调用。",
"inputSchema": {
"type": "object",
"properties": {
"drinkId": {
"type": "number",
"description": "来自 selectDrink 的返回值,禁止编造"
},
"specs": {
"type": "object",
"description": "规格值必须使用枚举 value,不接受自然语言"
}
},
"required": ["drinkId", "specs"]
},
"_meta": {
"ui": { "componentPath": "components/order-confirm-card/index" }
}
}]
}
看那两句 description——「来自 selectDrink 的返回值,禁止编造」「规格值必须使用枚举 value」。这不是注释,这是约束。写 mcp.json 的经验法则只有一条:把「AI 不该猜的东西」全部写进 description 和 Schema;把「必须先做的步骤」写进 SKILL.md 的跨接口铁律。 description 里你少写一句,AI 就多猜一次,线上就多一种翻车姿势。
第二节那个「90% 先探路」的判断在这里有了具体形态——开发模式真正贵的不是写接口,是把这些约束想全、写全、测全。
五、原子接口 + 原子组件:让 AI 在你允许的轨道里跑
合同签完,落到代码上是两个东西:
- 原子接口——真正执行查询、下单、保存、支付、刷新状态的函数。可信逻辑都在这里。
- 原子组件——展示接口结果的卡片,可以继续触发后续的上行消息或接口调用。组件只负责「展示 + 触发」,不承载任何可信逻辑。
接口注册大概长这样:
// skills/drink-skill/index.js(示意,不代表最终 API 细节)
const skill = wx.modelContext.createSkill('skills/drink-skill')
skill.registerAPI('searchDrinks', searchDrinks)
skill.registerAPI('selectDrink', selectDrink)
skill.registerAPI('confirmSku', confirmSku)
skill.registerAPI('payOrder', payOrder)
module.exports = skill
每个原子接口内部,都要做四件事:参数校验、错误码返回、调用业务服务、结构化输出。差一件,AI 那头就少一道护栏。
关键在「前置条件」。每个接口该在什么时候能调、什么时候严禁调,必须写死。这张接口职责表是上面那个状态机的代码投影——
| 接口 | 职责 | 前置条件 | 展示组件 | 关键风险 |
|---|---|---|---|---|
| getRecommendedDrinks | 模糊意图推荐 | 用户没给具体商品名 | 推荐卡片 | 别把推荐结果用纯文本铺满聊天流 |
| searchDrinks | 按关键词搜索 | 用户给了品名 / 品类 | 搜索结果卡片 | 关键词必须来自用户原话,禁止编造 |
| selectDrink | 展示详情与规格 | 已有上游 drinkId | 详情卡片 | 不能从自然语言猜 drinkId |
| confirmSku | 确认规格生成订单 | 已经 selectDrink | 订单确认卡 | 规格枚举、价格、库存都要校验 |
| payOrder | 发起支付返回结果 | 订单已 confirmed | 支付结果卡 | 支付前必须用户确认;状态以服务端为准 |
注意 payOrder 那行的「支付前必须用户确认」。这是微信划死的红线,也是「只读不动」这个内测原则在交易场景的延伸——支付、提交订单、改个人信息这类不可逆动作,绝不能让 AI 无感代办,必须有用户可见的显式确认。 别想着「自动化率」把这一步省了。供应商要是跟你吹「全自动下单零确认」,那不是先进,那是事故。
推荐的目录结构,给团队一个落地的样子:
miniprogram/
├── app.json # 声明 agent.skills 与独立分包
├── pages/ # 现有小程序页面(不动)
├── packageDetail/ # 半屏页 / 详情页 / 降级页
└── skills/
└── drink-skill/
├── SKILL.md # 业务 SOP、约束、意图分流
├── mcp.json # API、Schema、组件绑定
├── index.js # 注册原子接口
├── apis/ # 接口实现(可信逻辑)
├── components/ # 卡片组件(只展示 + 触发)
├── data/ # mock / 常量 / 枚举
└── utils/ # 鉴权、请求、校验工具
pages/ 那行写着「不动」——再强调一遍,这层是加出来的,不是把老小程序推倒。
六、把关系层缝回来:别让支付闭环顺手带走你的客户
前面五节都在讲「怎么让 AI 把活干对」。这一节讲一件更长远、也更容易被忽略的事——干完这单活,客户还认不认你。
这是第二篇的主题,但它有一个必须在架构里落地的动作,所以放在这儿讲。当 AI 当了门面,用户是在「微信的对话框」里完成下单的,整个体验里你的品牌可能只剩一张卡片。如果你不主动设计,会员、复购、用户数据,会顺着支付闭环流向平台,你慢慢退化成一个「供货商」。
Qwen 那边已经给了先例——品牌 Agent 让瑞幸、肯德基、蜜雪冰城这些首批品牌,把会员体系、个性化优惠、多轮对话留在品牌自己这侧。微信现在「只读不动」,但卡兹克扒到的那个「一句话生成小工具」的口子——复用的就是小程序的逻辑和架构——「明显是为未来分发预留的」。只读是暂时的,关系归属是永久的。 现在不把关系层架出来,等开放写权限那天,你是裸奔的。
架构上怎么做?在原子接口这一层,做一次身份缝合:
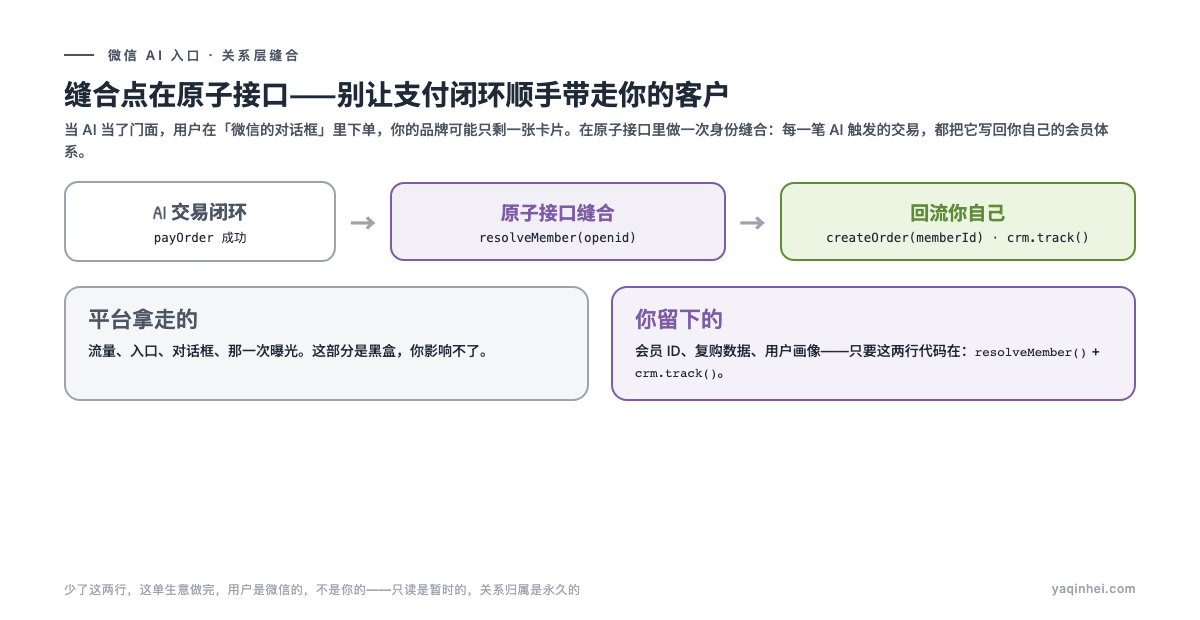
// 原子接口里,下单成功后做一次身份缝合(示意)
async function confirmSku(ctx, { drinkId, specs }) {
const identity = await resolveMember(ctx.openid) // openid → 你自己的会员 ID
const order = await createOrder({
memberId: identity.memberId, // 订单挂在你的会员体系下
drinkId, specs,
price: await pricing.recompute(drinkId, specs), // 价格服务端重算(见第三节)
})
await crm.track(identity.memberId, 'order_via_ai', order.id) // 复购数据回流自己
return toOrderCard(order)
}
resolveMember(ctx.openid) 和 crm.track(...) 这两行,是你在 AI 时代守住客户关系的物理动作。少了它们,你这单生意做完,用户是微信的,不是你的。
七、契约还没定死——按「模式」设计,不要赌某个 API
最后一个架构原则,关乎你这套东西的寿命。
微信 AI 还在合规 review,公开信息里写得清清楚楚:内测期 API、审核、评测标准、入口命名、开放节奏,都可能继续调整。这意味着今天你照着某篇文档里的 wx.modelContext.createSkill 写死的代码,下个版本可能就改了签名。
应对方式不是「等它稳了再做」(那你就把第一波流量让出去了),而是在易变的平台 API 和你稳定的业务逻辑之间,加一层薄薄的适配层:
- 你的业务逻辑(定价、库存、订单、会员)——稳定,不该知道微信的存在。
- 能力声明、接口注册、组件绑定——易变,全部收口到
skills/这一层。 - 中间用你自己定义的接口契约隔开。微信 API 一改,你只动适配层,业务后端一行不动。
这就是「按模式设计,不赌 API」的工程含义。模式是稳定的——意图理解 → 选 SKILL → 填参数 → 服务端校验 → 组件确认 → 状态回传,这套链路不管微信怎么改命名都不会变。具体 API 是易变的——那就把它关进一个你能一键替换的笼子。
顺便说一句,这层抽象不只是防微信变。支付宝、抖音、Qwen 各家都在开放自己的 agent 入口,契约各不相同。能力层抽象做好了,你面对的是「多个超级 App 入口」,而不是「为每个平台重写一遍」。
八、本周就能开工的 10 件事
不用等内测号,不用等契约定死,这 10 件事工程团队本周就能做——
- 把现有小程序的高频服务列成一张表,按「用户价值 × 风险 × 改造成本」打分排序,圈出前 3 条值得上开发模式的链路。
- 给每条候选链路写一句「用户原话」——说不出用户会怎么开口的,先别动它。
- 给每个候选 SKILL 写一行「完成定义」——写不出成功态的,拆错了,回到第 1 步。
- 开自动模式,挑 1 个低风险页面试接入,只看一个指标:AI 能不能正确发现并走通你的核心路径。
- 挑 1 个闭环场景做开发模式样板间(点单 / 取号 / 待办),别贪多。
- 把交易链路画成状态机,每条迁移箭头上标注前置条件和服务端校验项。
- 写第一版 mcp.json,逐个字段问自己「这个 AI 该不该猜」——不该猜的全写进 description 和 Schema。
- 过一遍第三节那张风险表,确认改价、重复支付、越权、编造 ID、假成功五种翻车都有服务端兜底。
- 在下单原子接口里加
openid → 会员 ID的映射 + 复购回流,哪怕现在只读不动,关系层先架出来。 - 把平台 API 调用收口到
skills/适配层,业务后端不出现任何微信专有调用。
第 8 条最不起眼也最致命——它是你和灰产之间唯一的墙。 别省。
九、评审供应商方案的 5 个必问问题
如果你在跟「帮你接入微信 AI」的供应商谈方案,下次评审会直接问这 5 个。答不上来或者闪烁的,警铃响起——
- 「AI 填上来的价格,你们服务端重算吗?」 答「信 AI 传的」——价格能被改,等着被薅。
- 「同一个订单 AI 连点两次支付,怎么拦?」 答不出幂等键 + 串行——重复扣款迟早出。
- 「支付前有用户显式确认吗,还是全自动?」 吹「全自动零确认」的——违反「只读不动」红线,必出事故。
- 「微信下个版本改了 API 签名,你们要动多少代码?」 答「到处都要改」——没做适配层,平台一抖你就瘫。
- 「这单做完,会员和复购数据进我的 CRM 还是停在平台?」 答「在微信侧」——你花钱接入,养肥的是别人。
第 5 个问题,问的是你三年后还有没有自己的客户。
十、想再深一层
上面是工程视角——分层、状态机、合同、关系缝合、适配层。这一篇刻意把完整的 SKILL.md 写法、原子组件的半屏交互细节、云开发身份方案、灰度评测集的构造留在了外面,因为那些得对着微信开放平台的最新文档写,而文档还在动。
想自己往下挖的,三个入口:
- 微信开放平台「AI 能力」系列文档——介绍、接入、运行机制、调试、最佳实践、评测指南、设计指南、FAQ。内测期一切以最新版为准。
- 官方示例项目
wechat-miniprogram/ai-mode-demo——WeStoreCafe 点单场景,含skills/drink-skill、SKILL.md、mcp.json、原子接口与组件,是目前最完整的可跑参考。 - 腾讯云开发 CloudBase 的接入文章——补充 SKILL、原子接口、原子组件、云开发身份方案(帮你省掉 code2session / token / 鉴权的样板代码)。
这套重构方法论的上层——Agent 怎么定级、Critic 怎么设计、上线后怎么不放养——在我的《Agentic AI 落地方法论》系列里。微信这次,只是把那套方法论第一次推到了 14 亿用户的入口上。
这篇之后
如果你想把「分层重构图 + 状态机模板 + 风险兜底表 + 10 件本周可做的事 + 5 问供应商对照卡」直接搬进下一次架构评审——不用每次翻这篇——我整理了一个 PDF 工具包给读到这里的读者。回复关键词「重构蓝图」,我把工具包发给你:
- 微信 AI 小程序分层重构图(可打印,标注每层职责 + 哪层是加出来的)
- 交易状态机模板(选品→支付全链路 + 每步服务端校验清单)
- 风险兜底速查表(改价 / 重复支付 / 越权 / 编造 ID / 假成功,逐条对策)
- 10 件本周可做 checklist + 5 问供应商对照卡(评审会专用,逐条勾红绿黄)
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.