用 Fable 5 搭一个第二大脑

原作者 @EXM7777,长期分享 AI 工作流与 agent ops 实操(运营付费社区 weeklyaiops)。这是一篇面向 practitioner 的「用 Fable 5 + Obsidian 搭第二大脑」实操长文。中文翻译、重排与 7 张配图本地化:Yaqin Hei(非原创,已保留原文出处)。
译者的话:为什么翻这篇
国内很多团队做「知识库 / 知识中心」,做着做着就塌成一件事:把文档一股脑塞进向量库,让 agent 去 RAG 检索。短期能跑,但有个越用越明显的毛病——库越大,检索越噪,翻回来的片段越不相关,最后谁也不信它。
这篇给的是另一条路:不是「检索一堆文档」,而是让 agent 把原始资料编译成一个互相 [[链接]] 的 wiki——raw/ 存不动的原始档,agent 在上面提炼出 entities / concepts 页并连成图谱,每加一页都让周围的页更有用。检索型知识库越长越噪,链接型 wiki 越长越强。 这正好是把「知识库」从只检索升级到治理的一套可操作方法:一页一课、更新不重复、错的删掉、原始档只读不改、每条结论都带 diff 和来源。
对我最大的启发,是它改了我「给 agent 喂知识」的默认动作:以前是把文档往 context 里堆,现在是在磁盘上养一个越用越聪明的图谱,让贵的 context window 只装结论、不装图书馆。如果你手里正好有个「越做越像文件仓库」的知识中心,这篇的四块结构(raw/entities/concepts/INDEX)、怀疑者验证、成本防火墙,下周就能照着改。
我要一步步教你,怎么把 Fable 5 变成一台「把你的业务摸得门儿清」的机器——它交出来的东西,和别人从同一个模型里得到的完全不是一个样。
这个工具,就是搭在 Obsidian 里的一个第二大脑。已经有一小撮人在跑它了……同样的模型,每一次输出却是天壤之别。

市面上最聪明的模型,却整天交出平庸的活儿,原因只有一个:它对你一无所知。
它不了解你的业务、你的受众、你过去做过的决策……于是它只能猜,而猜出来的东西,一股「通用感」。
把它接上你自己的知识库,同一个模型就变成了另一台机器:代码顺着你的架构走,内容读起来就是你的口吻,文字站在你自己攒的研究之上——而且第一天你就能看出区别。
这对你跑的任何工作流都成立:coding、marketing、内容、销售、研究。
不带第二大脑跑 agent,就是在浪费时间——而且差距只会越拉越大,因为大脑每多一个文件,之后每一次运行都更聪明一点,永远如此。
这台机器我每天都在跑……它藏在我发出去的每一篇文章、每一份指南、每一个产品背后。
这就是完整的系统:第二大脑到底是什么、agent 自己就能导航的文件夹结构、怎么用 goals 把它填满、怎么用 loops 让它一直活着、怎么在它之上跑一台真正的研究机器、怎么读它而不烧钱、怎么把它接进你搭的每一样东西。
同样的模型,不同的段位
先把这个论断背后的数字摆出来。
在会计场景里,一个不带客户历史的模型,准确率大概落在 70% 左右。
把客户的交易历史喂给它,它从 85% 起步,一路爬过 90%。
模型本身没变,变的是知识。
写作也一样。
一个中等档位的模型,配上一份搭得好的「voice profile(语气画像)」,产出的东西比完全没有画像的 Fable 5 更有辨识度。
文件,比模型档位承载了更多的结果。
而模型本身,比以往任何一代都更奖励这件事:Anthropic 自己的测试里,让 Fable 玩一整局卡牌构筑游戏、配上基于文件的记忆,它的提升是上一代旗舰的三倍。
一局游戏、厂商自测、目前还没人复现过……但这个数字指向的动作,成本不过是一个装着 markdown 的文件夹,所以你怎么算都值得做。
动手之前,我得先跟你说清楚一件事:模型不会魔法般地在你的笔记里找到一切。它做的是——在对话之外的知识上行动,并标注每一条信息的出处。这份记忆是你的,躺在你自己的磁盘上,是你能打开、能读的纯文本。给它几周时间,agent 会开始引用一些你自己都忘了做过的决策。
第一个问题是:这份记忆该住在哪。答案不花一分钱,而且你可能已经装好了。
一分钟看懂 Obsidian
Obsidian 是一个免费 app,它就架在你电脑上一个装着 markdown 文件的文件夹之上。
没有数据库、不锁定云端……你的笔记就是你拥有的纯文本文件,而这个 app 只是一扇看进去的漂亮窗户。
你只需要用到它的两个功能:
[[wikilinks]]: 在任意笔记名两边打上双方括号,这两篇笔记就连上了。- graph view(图谱视图): Obsidian 把每篇笔记画成一个点、每条链接画成一条线,你的知识就成了一张网。
而它天生适配 agent:因为 vault 就是个文件夹,Fable 通过 Claude Code(模型在你机器上运行的那个终端 app)直接在上面工作。不用插件、不用连接器、不用特殊配置——agent 读写 markdown 文件,Obsidian 给你看哪里变了。你用 app,agent 用文件夹,两边看的是同一个大脑。
别一听就绷紧准备打大仗:这篇里所有东西的入门版大约一小时搞定,读取规则一旦设好,跑起来只花几分钱。
一堆文件和一个大脑的区别,在于结构——而结构,正是几乎所有人做错的地方。
结构:四块,别无其他
这套思路来自 karpathy 的 llm-wiki 理念:把你的知识库当成一个 codebase 来对待。 Obsidian 是编辑器,模型是程序员,wiki 是代码。
把大家公开在跑的方案、repo、爆火模板、翻车帖都扒了一遍之后,有四块反复出现:
raw/: 你捕获的一切原封不动地进这里——文章、转录、通话记录、竞品页面……只读的历史,agent 永不改写它。entities/: 一个具体的东西一页——一个客户、一个竞品、一个工具、一个人。concepts/: 一个想法一页——一个策略、一个模式、一条教训。INDEX.md: 前门——每一页都列出来配一句话描述,这样 agent 不用逐个打开就知道有什么。
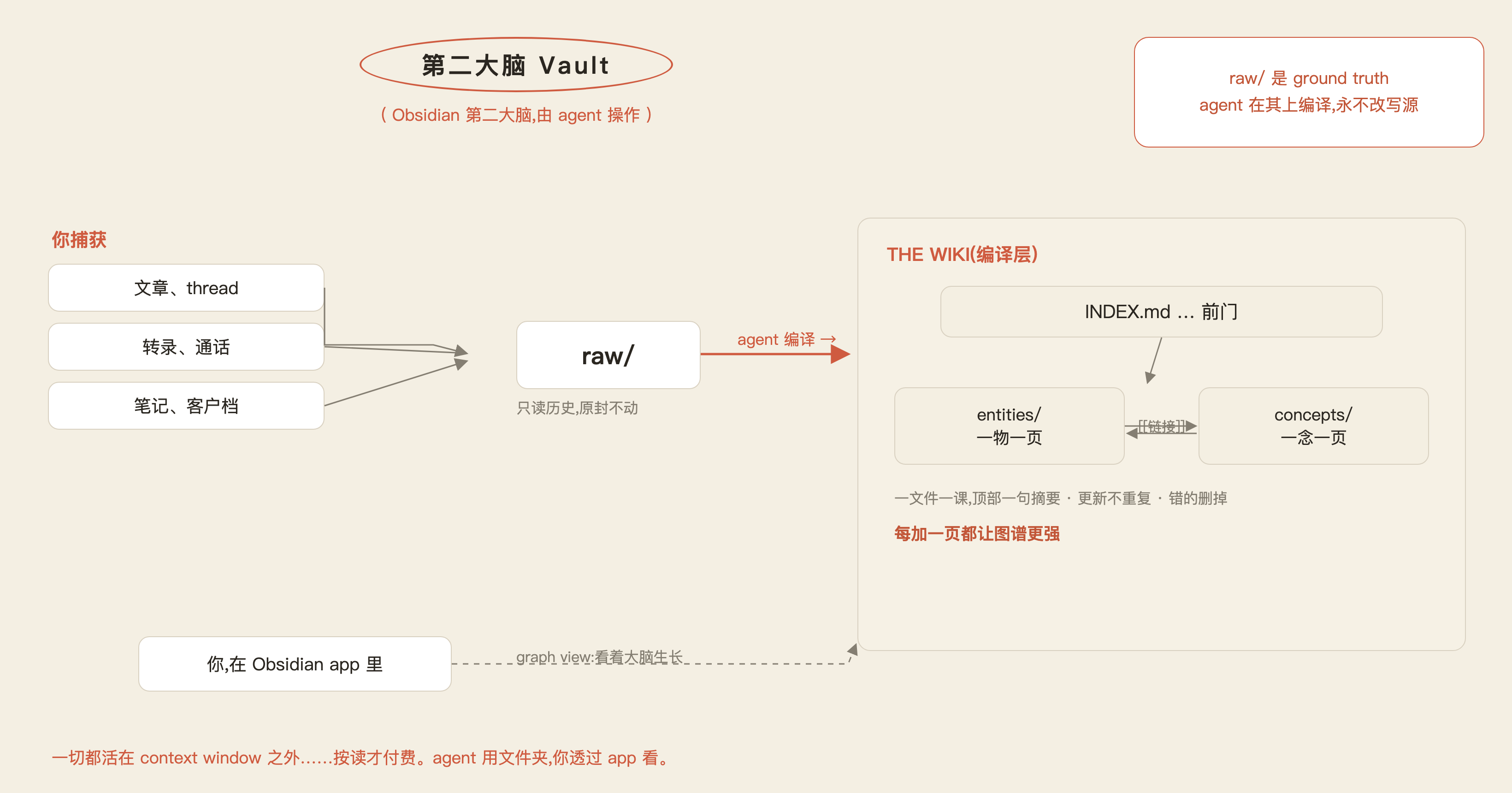
raw/ 丢原始档,agent 负责编译出 entities / concepts 并连成图谱;这一切都活在 context window 之外。
agent 的活儿是编译:它读 raw/ 里的新材料,更新 entity 和 concept 页,一边更新一边给它们连线。
写入规则简单到四行就能写完:
- 一个文件一课,顶部配一句话摘要
- 更新已有页面,别再造一个重复的
- 事后发现错了的笔记,删掉
- 原始来源和编译后的页面,永远分开放
为什么 raw/ 保持不动:当同一个 agent 反复读、反复改写同一批笔记,细节会糊掉、错误会滚雪球。raw/ 是你的 ground truth(基准事实),wiki 在它之上越变越聪明。
而页面只是一半的价值……页面之间的链接,才是真正的护城河藏身处。
知识图谱:为什么它越长越强
agent 在两页之间写下的每一个 [[链接]],都是图里的一条边。
这一点,把「一个 vault」和「一堆笔记」彻底分开:基于检索的知识库,越长越噪——文件越多,每次搜索里的垃圾就越多。而一个带链接的 wiki,越长越强——每加一页都接进这张网,让周围的页更有用。
当 agent 要回答某件事时,它不会扫描一切……它沿着链接走:从客户页,到活动概念页,再到竞品页,像你顺着自己的记忆走一样。
karpathy 自己的 vault 大约有 100 篇文章、40 万字,全由模型编译、全部相连。这样跑上两周,打开 graph view,你会看到自己的业务变成一张活地图——光这一张图,就足以改变你看待「自己到底知道些什么」的方式。
那怎么才能不花一个月复制粘贴、就把它填满?
用 goals 把它填满
第一步是回填(backfill),而 Fable 的 goal 系统就是为这活儿而生的。
Claude Code 里的 /goal 让你写下一条终点线,模型自己一直干,同时有第二个更小的模型在旁边当裁判读进度,越过终点线时确认达成。
诀窍在于:裁判只看得见对话里的东西,所以 goal 必须要求它能读到的证据:
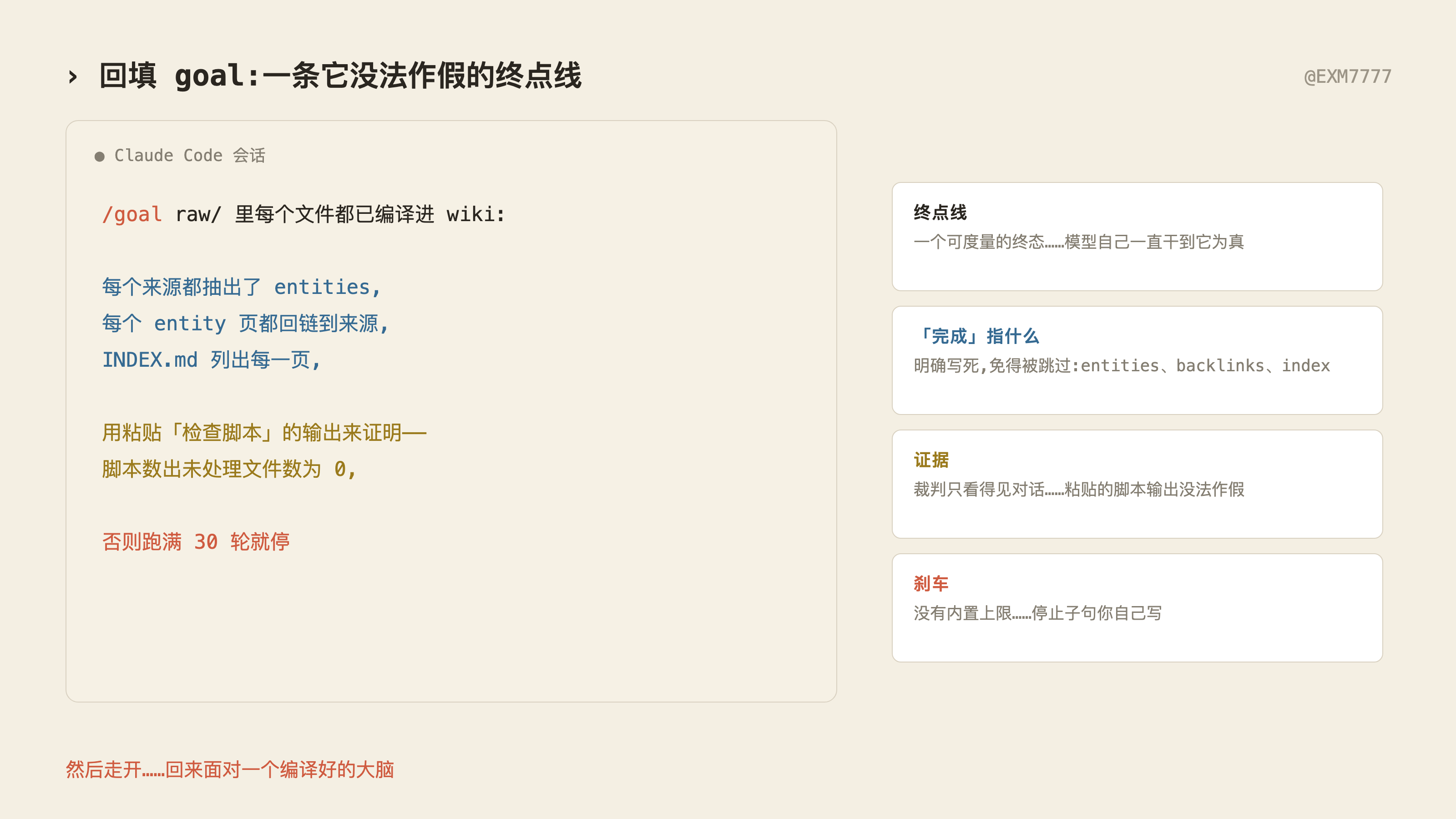
/goal 的关键:终点线要能被裁判「读到证据」——比如贴出检查脚本的输出、未处理文件数为 0,再加一条「跑满 30 轮就停」的刹车。
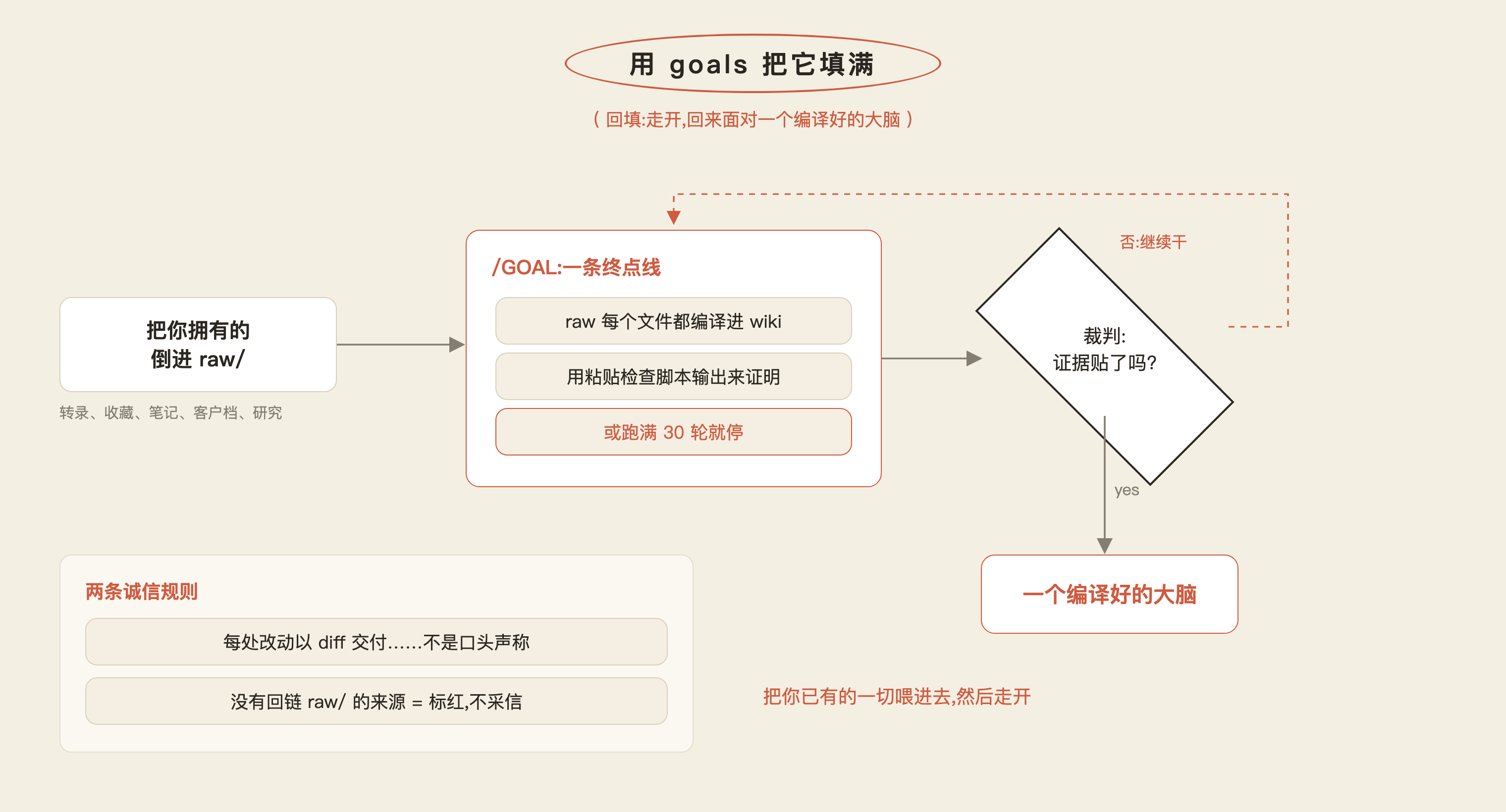
跑之前,先把你已经拥有的东西喂进 raw/:旧的聊天记录、收藏的帖子、笔记 app 的导出、客户文件夹、过去的研究。
然后走开,回来时你面对的就是一个编译好的大脑。
raw/ 来源链接的页面一律标红不采信。
两条规则让回填保持诚实:
- 每处改动都以 diff(前后逐行对照) 交付,绝不以「口头声称」交付……agent 说它更新了某页,diff 得证明。
- 一个页面若没有回指
raw/的来源链接,一律标红、不采信。
回填给你的是一个编译好的大脑……让它一直活着是另一件事,也是所有人都会跳过的那件事。
用 loops 让它活着
一个只有在你记得投喂时才生长的第二大脑,三周就死了。所以维护得跑在计划表上,而不是你的记性上:
- 每次会话之后: 一个 hook(会话结束时自动触发的小脚本)去挖刚刚发生了什么——做了哪些决策、抓到哪些错、确认了哪些模式——写进 vault 成为带日期的笔记。你已经干过的活,不用你归档就变成了记忆。
- 每天夜里: 一趟 compile pass,用便宜档模型读当天的新原始材料、更新 wiki 页面……日常活,日常档。
- 每周: 一趟 lint pass,专抓矛盾、重复页、死链……这是让图谱保持干净的那趟循环,它存在的理由是:没人维护的 wiki 会腐烂。
- 每周: 一趟 synthesis pass,用大模型横读整个 vault,写出这周变了什么、什么在漂移、什么值得注意。
最后这趟,是唯一一趟贵模型配得上它座位的循环。其余全部跑便宜档——因为更新笔记是日常活,而把日常活派给 Fable,正是人们白白烧钱的方式。
维护让 vault 保持干净……但让它值钱的材料从哪来?
喂养它的研究工作流
这一步,vault 从「存储」变成「优势」,也正是垃圾通常混进来的地方。
默认的 AI 研究,是把一个 prompt 丢给聊天机器人,答案随着滚屏死掉。更糟的是,它建在过时的知识上——在 AI 领域,半年前的建议往往是主动地错;而真正的 practitioner 层(大家此刻在跑什么、什么翻车、什么管用)活在社交媒体上,不在官方文档里。
所以这台研究机器这么工作:
- 一个问题进来,拆成 3-5 个子问题
- 并行的 agent 扇出去,各自搜一个不同的面:社交媒体挖 practitioner 层、web 找文档和定价、爬虫把值得读的全文拉下来
- 每一条发现都变成一张回执(receipt):论断、来源链接、日期
- 然后是让它成立的那道闸:一个怀疑者(skeptic)agent 攻击每一条论断、试图把它杀掉——单一来源的炒作被贴标签、矛盾被翻出来,只有幸存者通过
- 通过验证的发现落进 vault 成为页面,每页带日期、带链接,还带一个过期日,让过时的知识自己喊出来
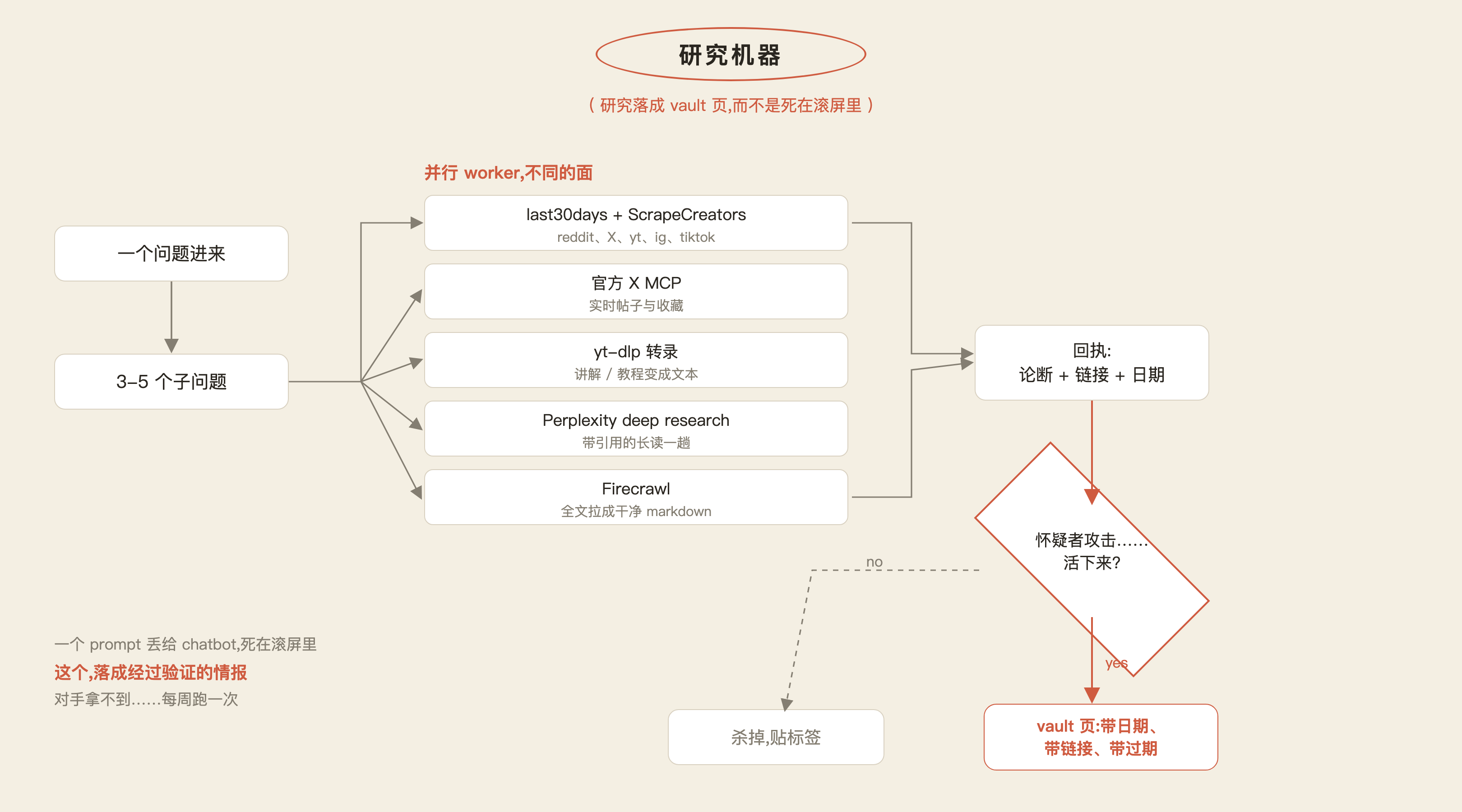
我实际在用的那套栈:
- last30days(由 ScrapeCreators 驱动): 一个 skill,扫 reddit、X、youtube、instagram、tiktok 最近 30 天里任意话题的 practitioner 讨论
- 官方 X MCP: 直接从源头拉实时的帖子、thread 和收藏
- yt-dlp 的 youtube 转录: 任何一段讲解或教程,都变成 agent 能挖的文本
- instagram 和 tiktok 内容(走 ScrapeCreators): 因为短视频是新工作流最先冒头的地方
- Perplexity deep research: 横跨全网、带引用的长读一趟
- Firecrawl: 把每一个值得留的页面,拉成干净的 markdown 全文
怀疑者,是「研究」和「攒谣言」的分界。 每周在你的细分领域跑一次,vault 就填满了你的竞争对手拿不到的、经过验证、带日期、带来源的情报。
可这一切都白搭——如果读这个 vault 花的钱比它带来的还多。
读它而不烧钱
一个 vault 只有在「读它很便宜」的前提下才能长期成立,而这恰恰是几乎所有方案漏水的地方。
心智模型:context window 是一间很贵的房间,进去的一切都要用 token(AI 账单的计量单位)付费。
- 你的
CLAUDE.md(agent 每次会话开头都读的指令文件)每一次都自动加载……这是「永远在付」的税——保持在 200 行以内,让它指向 vault,而不是装下 vault。 - 其余全是「按读付费」:agent 查
INDEX.md、顺着链接走、用关键词 grep,只打开线索指向的那几页……「全文件夹扫一遍」是那个永远不该发生的动作。 - 遇到大问题,派个 worker 去:一个 subagent 在它自己独立的 context 里读五十页,只把一段结论带回你的会话……那间贵房间里装的是决策,不是图书馆。
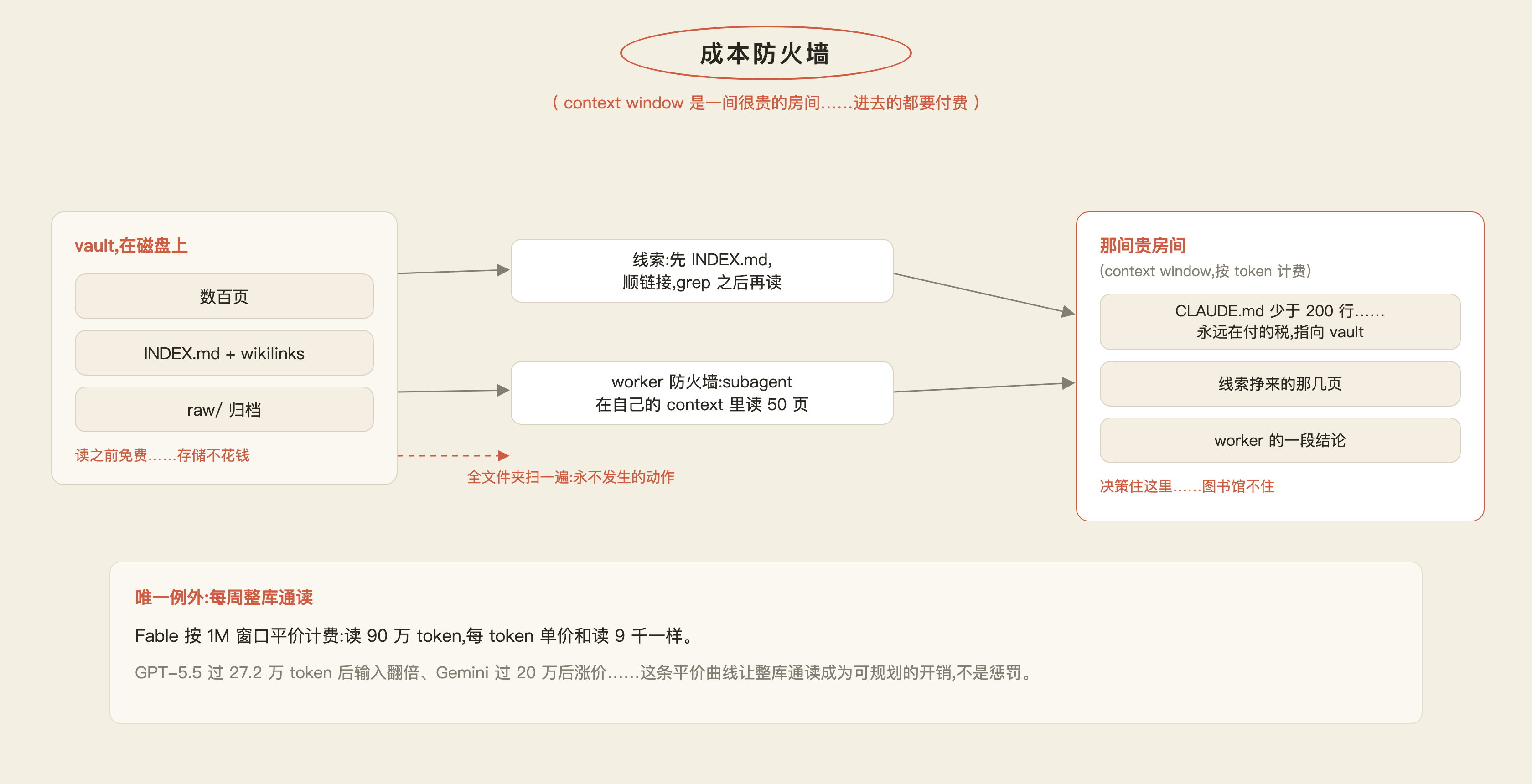
CLAUDE.md 是永远在付的税(压到 200 行内),其余按读付费;唯一例外是 Fable 的 1M 窗口按平价计费,让每周整库通读成为可规划的开销。
一个例外:每周一次的整库通读。 Fable 的 1M 窗口按「平价」计费——读 90 万 token,每 token 的单价和读 9 千 token 一样;而 GPT-5.5 过 27.2 万 token 后输入翻倍、Gemini 过 20 万后涨价……这条平价曲线,让整库通读成为一笔可规划的开销,而不是一次惩罚。
把它接进你做的每一个项目
一个只会存东西的 vault,是集邮爱好……这一个,喂养你跑的每一个项目。
用三行,把任意项目指向它——写进那个项目的 CLAUDE.md:
## knowledge
- 开始前,读 ~/vault/entities/ 和 ~/vault/concepts/ 里相关的页面
- 任何关于我们业务、客户或受众的论断,都落到一个 vault 页面上
输出立刻就变了:
- marketing: 活动 brief 扎根于你真实的受众页和竞品历史,而不是通用人设
- 内容: 草稿引用你自己过去的研究、贴合你的 voice profile
- coding: agent 给每个项目在 vault 里维护一份活的架构笔记,于是没有一次会话是「盲开局」
- 客户工作: 每一份交付,开头都带着背后完整的关系历史
然后是下半场:vault 本身变成产品。 研究页变成文章和指南、concept 页变成课程、客户页变成案例——你不再对着白纸从零创作,而是打包机器已经验证过的东西。
一句能救你 vault 的警告:同步(sync)是 vault 的死地。 只跑一套同步系统……如果 agent 在写文件的同时 iCloud 正在同步它们,你会得到冲突副本和错乱的文件夹。用 git(程序员用的存档点系统)当 checkpoint 层——它只在你叫它存时才锁定一个版本,这套配置能活下来。
卡片:整套流程
整套搭建,按顺序——照抄:
- 建 vault:
raw/、entities/、concepts/,加一个INDEX.md - 把四条规则写进
CLAUDE.md: 一个文件一课、更新不重复、错的删掉、永不碰raw/ - 把你拥有的一切倒进
raw/: 转录、收藏、笔记、客户文件夹 - 跑
/goal回填: 附上粘贴的证据和一条停止子句 - 排上循环: 会话 hook、便宜档的夜间 compile、每周 lint、一趟贵档 synthesis
- 跑每周研究扫描: 扇出、让怀疑者攻击、幸存者落成带日期的页面
- 给每个项目的
CLAUDE.md加上那三行 knowledge
坐在驾驶座上的模型还会再换……vault 熬过每一次换代,而写进它的反馈,让它无论谁在开,都每周更聪明一点。
最小版本一小时就能搭:一个文件夹、十个关于你业务的文件,加一个「先读它们」的 agent。剩下的,你的输出会告诉你。
原文:@EXM7777《How to build a second brain with Fable 5》。中文翻译与配图本地化:Yaqin Hei。
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.