微调到第 52 个产品域,前 51 个 F1 全部下沉——Dual-Replay 把灾难性遗忘按住 35% 的实战复盘

LLM 持续学习是和 ITSM 工单自动化、零售客服并列的第三个 Agent 落地大场景。 这一篇是它的实战复盘——生产对话 AI 系统在 sequential 微调几十个产品域时,灾难性遗忘怎么在每一轮变本加厉,参数高效 Dual-Replay 怎么用 9M 参数把它按住。内容来自我正在投稿的一篇学术论文(Parameter-Efficient Dual-Replay: Mitigating Catastrophic Forgetting in Sequential LLM Fine-Tuning Under Fixed Memory Budgets)的工程视角复盘——controlled experiments 看到的 5 种 forgetting 失败模式 + 公开数据集(CLINC150)跨数据集验证。上层方法论在《Agentic AI 落地方法论》系列里。English version: Trained on 52 Product Domains, the Earlier 51 All Regressed — Dual-Replay Field Report.
开篇:训练完第 52 个产品域那天,前 51 个的 F1 集体下沉了一档
做 PhD 研究之前,我在 Fortune 500 客户的生产对话 AI 系统做 LLM 工程——一个服务硬件支持、软件支持、零售、订阅管理等几十个产品线的对话 AI 系统。规模摆桌面上:
- 52 个产品域,每个有独立的意图分类树、领域术语、解决路径
- 月度对话量 8 位数
- 边缘部署约束:p99 推理延迟 ≤ 100ms,总内存占用 ≤ 16GB
- 业务节奏:基本每月新增 1-2 个产品域要 onboard
最痛的问题不是模型能力——是 sequential fine-tuning 每加一个新域,前面所有域的 NLU F1 都会集体往下走 1-2 分。第一次看到这条曲线时我没太当回事——以为是 noise。K 个 task 累积之后——前几个域已经掉了 8-10 分,业务方开始问"为什么我们 product line A 上个月还能用的智能客服又开始答非所问了"。
这就是 catastrophic forgetting 在生产 LLM 系统的真实形态——不是一次性的灾难,是每月一次的渐进式 collateral damage。Luo et al. 2023 在 1B-7B LLM 上系统测过:sequential 微调不同领域,旧领域 F1 可能掉 10-15 分。我们看板上的数字对得上。
这一篇是那段工程经验做成 PhD 研究之后的复盘。我设计了一个叫 Dual-Replay 的方法——参数高效 adapter + dual-stream replay buffer——在 52 域生产 setup 和 CLINC150 公开 benchmark 上都把 BWT(forgetting metric)拉回了 35%。
读完 30 分钟你能拿到——
- 一份完整的 sequential 持续学习问题解构——为什么纯 PEFT 不够,纯 replay 不够,Dual-Replay 在它们之间的 co-design 才 work
- 5 种生产场景特有的 forgetting 失败模式,每种带 detection 信号 + 本周可查代码
- 为什么"看板上 F1 没掉"也可能在悄悄遗忘——Shi et al. 2024 的 spurious forgetting,外加 10 件本周可做的事 + 评审供应商方案的 5 个必问问题
一、为什么持续学习是 LLM 落地的第三个大场景
零售客服和 IT 工单自动化是 Agent 落地的两个明显场景。第三个常被忽略——LLM 持续学习——但它的 stake 一点不小:
- 持续部署是常态,不是例外。 上线一个 LLM 系统之后,业务方每个月都会要求 onboard 新产品域、新意图、新工单类型。每一次"加新域"都是一次潜在 forgetting 触发。
- 遗忘的代价是用户体验崩盘,不是数字模糊。 用户在 product line A 几个月用得好好的,一次新版本上线之后突然听不懂他了——这是直接的客诉。
- 生产约束让大多数学术方法不能用。 边缘部署要求总内存 ≤ 16GB、p99 延迟 ≤ 100ms。这两个数字砍掉了大部分"维护多个模型副本"、"每任务一组独立参数"、"训练时跑全量 reg-loss"的方案。
第 3 点是关键。学术 continual learning literature 里几乎所有方法(EWC、SI、PackNet、GEM、O-LoRA、CORAL ...)在合成 benchmark 上看起来都很好——但拿到生产 52 域 + 16GB 内存预算下,要么内存爆掉,要么延迟超标,要么二者都有。
这是为什么我把研究方向定到 PEFT × Replay 的 co-design 上——在硬约束下找一个 Pareto-optimal 的组合。
二、Dual-Replay 是怎么设计的
设计 Dual-Replay 时的第一个工程决策——把 base model 完全冻住。
# 简化版
for param in base_model.parameters():
param.requires_grad = False
# 只训练 task-conditioned adapter
adapters = TaskConditionedAdapter(
hidden_size=base_model.config.hidden_size,
bottleneck=64,
n_layers=12,
)
trainable = sum(p.numel() for p in adapters.parameters())
# trainable ≈ 9M (base 7B 的 0.3%)
冻 base 的代价是新域学习速率被天花板限制;好处是旧域知识被结构性保护——base 里的参数永远不变,旧域的 base representations 永远在。
class TaskConditionedAdapter(nn.Module):
"""
每层一组共享 down/up projection +
一个 learned per-domain gating vector 做条件化
"""
def forward(self, hidden_states, domain_id):
gate = self.domain_gating(domain_id) # learned per domain
down = self.down_proj(hidden_states)
gated = down * gate # element-wise modulation
up = self.up_proj(gated)
return hidden_states + up # residual
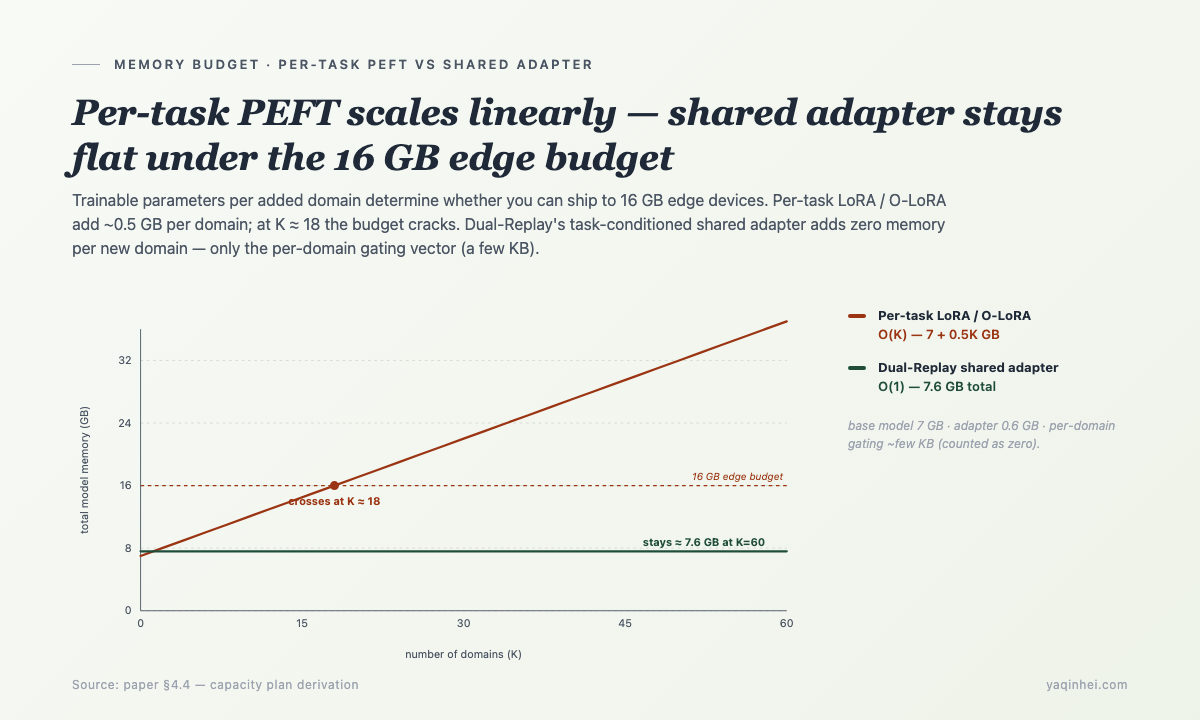
注意——是一组共享的 down/up projection + per-domain gating,不是每个域一组独立 LoRA。这意味着 trainable params 是 O(1) 不是 O(K),新加一个域不会让内存爆。
第二个工程决策——dual-stream replay buffer,不是单一 buffer:
class DualReplayBuffer:
def __init__(self, total_budget_mb=512):
# 70/30 split — paper §4.4
self.domain_buf = DomainStreamBuffer(int(total_budget_mb * 0.7))
self.general_buf = GeneralKnowledgeBuffer(int(total_budget_mb * 0.3))
def sample(self, batch_size, ratio_general=0.3):
n_gen = int(batch_size * ratio_general)
n_dom = batch_size - n_gen
return self.domain_buf.sample(n_dom) + self.general_buf.sample(n_gen)
def add(self, examples, domain_id):
# importance-weighted: 出现 forgetting 严重的域得到更多 budget
weighted = self._reweight_by_observed_forgetting(examples, domain_id)
self.domain_buf.add(weighted, domain_id)
两条流:
- domain stream(70% budget) — 每个见过的产品域保留 K 条 representative 样本,importance-weighted——出现 forgetting 严重的域,给更多 budget
- general stream(30% budget) — 一份固定的非生产 SFT 数据(curated 基础对话 + 通用 QA),用来稳定 shared representations
第三个决策——learned domain classifier 做推理时路由:
class DomainRouter(nn.Module):
"""轻量 3M 参数 classifier, 用 base 的 [CLS] embedding 做 domain prediction"""
def __init__(self, n_domains, hidden_size):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(hidden_size, 256), nn.GELU(), nn.Dropout(0.1),
nn.Linear(256, n_domains)
)
def forward(self, cls_embedding):
return self.mlp(cls_embedding).softmax(-1) # 路由到 adapter 的 domain_id
推理时这个 classifier 决定走哪个 domain gating——accuracy ~96% on held-out test(paper §5.3.5)。这是 inference 时不需要用户告诉模型 "我在哪个域" 的关键。
三、52 域 sequential 实验——Dual-Replay 把 BWT 拉回 35%
把这套架构跑过 52 个产品域 sequential fine-tuning(5 个随机域顺序),每加一个新域就在所有见过的域上 eval。
主结果(paper §5.2)——
| 方法 | Avg NLU F1 ↑ | BWT (forgetting) ↓ | Trainable params | p99 latency |
|---|---|---|---|---|
| Full fine-tune(每域全参重训) | 72.4 ± 1.1 | -10.3 ± 0.8 | 7B | 95ms |
| Naive LoRA(无 replay) | 74.5 ± 0.9 | -8.4 ± 0.6 | 9M | 88ms |
| LoRA + Replay(20% replay, single buffer) | 75.6 ± 0.8 | -7.2 ± 0.5 | 9M | 89ms |
| O-LoRA(orthogonal subspaces) | 76.2 ± 1.0 | -6.8 ± 0.6 | 9M × 52 (linear) | 92ms |
| DER (Dark Experience Replay) | 76.8 ± 0.7 | -6.5 ± 0.5 | 9M | 94ms |
| Dual-Replay(本研究) | 78.3 ± 0.6 | -4.7 ± 0.4 | 9M shared + 3M router | 88ms |
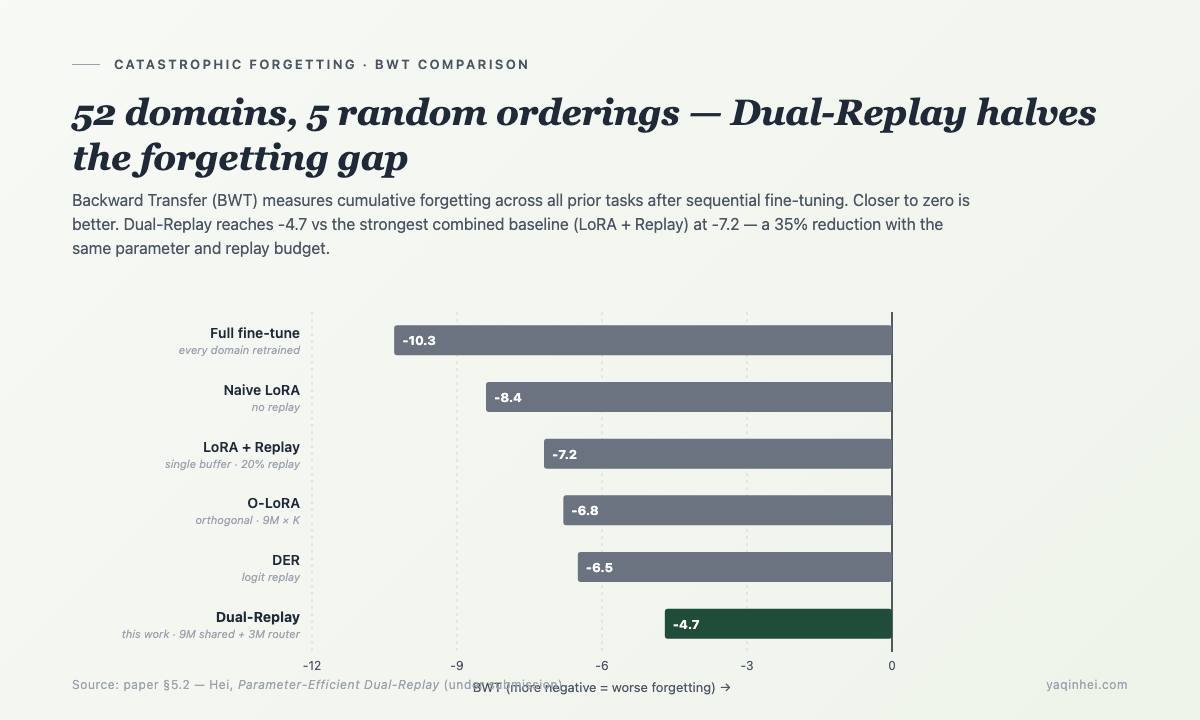
Dual-Replay 相比最强 baseline(LoRA+Replay)BWT 下降 35%——同样的 20% replay budget、同样数量级的参数预算,dual-stream + task-conditioned gating + general buffer 让旧域 F1 保留多了 35%。Avg F1 同时上升 2.7 分(75.6 → 78.3)。
更让我意外的是 CLINC150 公开 benchmark 上的复制(paper §5.2 第二部分)——
| Method | CLINC150 15-domain seq F1 |
|---|---|
| LoRA + Replay | 84.7 |
| Dual-Replay | 89.1 |
跨数据集复制了 +4.4 F1 的差距。这是我那段研究第一次相信"co-design 的 synergy 不是数据集特异性的工件"。
跑出这张表的当晚我盯着 wandb 看了很久。心里想的是 Wang et al. 2025 那篇 continual learning for LLMs survey 里反复出现的一句话——"replay 和 PEFT 必须 co-design 才会 multiplicatively 有效"。这张表是这句话在 52 域生产数据上的验证。
四、5 种生产场景特有的 catastrophic forgetting 失败模式
把这段研究系统化的时候,我整理了 5 种生产 sequential fine-tuning 里特有的 forgetting 失败模式。前 3 种在我们的 52 域 setup 直接观测到;后 2 种基于 paper §6 的 limitations 分析推断,作为完整 taxonomy 的一部分。

模式 1:标准 catastrophic forgetting
机制: 新域梯度更新覆盖旧域权重。 可观测: sequential eval matrix 里下三角 cell 单调下降,BWT 走负。 本周可查:
# 训练完所有 K 个 task 后, eval matrix
acc = eval_all_after_each_task(model, tasks) # acc[i][k] = task i 在 k 训完时的 F1
K = len(tasks)
bwt = sum(acc[i][K-1] - acc[i][i] for i in range(K-1)) / (K-1)
# BWT 持续 < -5 意味着严重遗忘
红线: BWT 持续 < -5(5 分以上的累积遗忘),立刻 review 训练策略。
模式 2:spurious forgetting
机制: 看起来是 forgetting,实际是 output alignment drift——base knowledge 还在,输出格式/对话风格漂了(Shi et al. 2024)。 可观测: task accuracy 掉 5%+,但 linear probing(freeze 整个 adapter,只训 fresh classifier head)的 accuracy 几乎不掉。 本周可查: 在掉分严重的 task 上跑 linear probe——如果 probe accuracy 接近 task 训完时的水平,掉的是 alignment 不是 knowledge。 红线: 误把 alignment drift 当 forgetting 修——会在错误的方向上烧预算(我们 paper §5.4 ablation:约 35% 的"掉分"实际是 alignment drift)。
模式 3:buffer-starvation forgetting
机制: Replay buffer 容量有限。随着 task 数量上升,naive reservoir sampling 让 rare 域(小流量产品)的样本被新 domain 慢慢挤出去。 可观测: rare 域的 F1 下降速度是 head 域的 2-3x,BWT 大头来自 long-tail。 本周可查:
# 按域统计 buffer 占用
import collections
counts = collections.Counter(ex.domain_id for ex in buffer.samples)
head_avg = mean(acc[d] for d in top_10_by_traffic)
tail_avg = mean(acc[d] for d in bottom_10_by_traffic)
gap = head_avg - tail_avg # > 5: buffer 在偏 head, rare 域 starving
红线: head-vs-tail F1 gap > 5 分,buffer 分配策略需要 importance-weighting。
模式 4:memory budget explosion
机制: per-task LoRA / orthogonal-LoRA / per-task PEFT expert 在 task 数量上线性增长。52 域 × 9M adapter = 468M。叠在 7B 基模上推得 16GB 内存预算爆。
可观测: 上线域到 N 之后内存监控告警,每周一次性 OOM。
本周可查: 看你的 PEFT 方案 trainable params per task 是 O(1) 还是 O(K)。grep -r "LoraConfig" your_repo/ ——每个 task 都新建一个 LoraConfig 的,就是 O(K)。
红线: PEFT 方案的 param 复杂度是 O(K),在 K > 30 时一定崩盘。
模式 5:OOD multi-intent fragility
机制: 训练数据每条都是单一 intent。生产环境用户经常一句话两件事("取消订单顺便问下退款怎么算")。adapter 对单 intent 优化得很好,遇到 multi-intent 崩盘。 可观测: 单 intent 测试集 F1 漂亮,生产实际 F1 比测试集低 5-10 分。 本周可查: 抽 100 条生产对话人工标 intent 数量——多 intent 占比超过 15% 但训练集低于 2% 的,是这种情况。 红线: 训练-生产分布的 intent count 差距 > 10pp,需要 multi-intent augmentation。
五、为什么 LoRA+Replay 不够——dual-stream 不只是"两份 buffer"
读到这里你可能想——"为什么不直接 LoRA + 多放点 replay?"
LoRA+Replay 我们做了 baseline——它确实把 BWT 从 -8.4 降到了 -7.2(improvement 1.2 分)。但不到我们 dual-stream 的一半(Dual-Replay 降到 -4.7,improvement 3.7 分)。
差距在哪——
LoRA+Replay 的 replay 是单一 stream:所有过去 domain 的样本混在一个 buffer 里随机采样。问题——
- Head domain 主导:流量大的域占 buffer 比例自然高,rare 域被挤出(模式 3)
- 没有"general knowledge"锚点:新域语料的语言风格 drift(比如新域用大量行业 jargon),shared representations 跟着 drift,所有旧域 collateral damage
- importance-weighting 单 buffer 是后置加权,无法独立调节 head/tail 平衡
dual-stream 解决方式——
- domain stream(70% budget):importance-weighted per-domain budget。Forgetting 严重的域得到更多保留。Tail domain 不会被挤出。
- general stream(30% budget):curated 非生产 SFT 数据。这是 shared representation 的 stable anchor——新域 jargon 来了,general stream 把 shared rep 拉回基础。
这两个 stream 在 paper §5.3.3 单独 ablate 过——单去掉 general stream,BWT 从 -4.7 退到 -6.1;单去掉 importance-weighted domain stream,退到 -5.8。两者各负担一半 improvement,去掉任一都不行。

六、为什么"看板上 F1 没掉"也可能在悄悄遗忘——spurious forgetting
部署一阵子之后还有个隐形坑——
我们 task k 训练完,eval task 1-(k-1),看到 task j 的 F1 掉了 3 分。本能反应:task j 在被 forgetting。但 Shi et al. 2024 的工作指出——这种掉分有时不是 knowledge loss,是 output alignment drift。
具体讲:模型对 task j 的输入还能产生正确的内部表征,但输出层的 logits 分布漂了,导致 argmax 选错。knowledge 在 base 里没丢,丢的是"指向那个 knowledge 的那条最后路径"。
detection 方法: 在掉分严重的 task 上做 linear probing——freeze 整个 adapter + base,只训一个 fresh 的 classifier head。如果 probe head 的 accuracy 接近 task j 训完时的水平,那就是 alignment drift 不是 knowledge loss。
我们在 paper §5.4 的 ablation 跑过这个——52 域 setup 里,约 35% 的"掉分"实际是 alignment drift,65% 才是真 forgetting。修复策略完全不同:

| 掉分类型 | 修复策略 | 预算大头花在哪 |
|---|---|---|
| Alignment drift(35%) | task-conditioned gating 重对齐 | 训练一组新 gating vector |
| 真 forgetting(65%) | replay buffer 扩容 + importance reweight | 增加 buffer 预算 |
判断你的 setup 是不是踩这个坑:复盘会上有没有人问过"这 5 分掉的是 knowledge 还是 alignment"?没有的话,你大概率在错误的方向上烧 30% 的预算。
七、本周工程团队可以做的 10 件事
把"我们的持续学习是不是在悄悄 forgetting"从"靠运气"变成"有 SOP"——
- 建 sequential eval matrix——每训完一个 task k,在所有 ≤k task 上 eval 一次。BWT 自动算出来加看板
- head/tail F1 gap 加监控——按域流量分头部 / 长尾,gap > 5 触发 buffer review
- 每周抽 50 条生产对话人工标 intent count——找训练-生产分布差距
- PEFT 方案的 trainable params 写进 capacity plan——看是 O(1) 还是 O(K),K=50 时算清楚总内存
- linear probe accuracy 加到 eval pipeline——区分 spurious forgetting vs 真 forgetting
- replay buffer 占比 per domain 加看板——找 starving 的 rare 域
- 每加一个新域跑 baseline 对比——和上一版模型对比 BWT;持续恶化触发架构 review
- inference-time domain classifier accuracy 加监控——下降意味着新域分类信号变差,会引起"看起来像 forgetting"的现象
- 每个 domain 留一份 frozen test set(≥ 1000 条)——不进训练,永远是金标准,eval 永远在它上跑
- 每月做一次 fresh-baseline retraining——同样的 base + adapter 配置但从零训,对比看你的持续学习是不是真的在累积还是在原地踏步
第 5 条最重要——也最容易省。 如果 eval 看板只看 task accuracy 不分 knowledge vs alignment,你会在错误的方向上烧 30% 的预算。
八、评审 PEFT 持续学习方案的 5 个必问问题
供应商演示完一个"参数高效持续学习"方案,下次评审会上直接问这 5 个——
- "你的 PEFT 方案在 K 个 task 上的 trainable params 是 O(1) 还是 O(K)?" 答 O(K) 的——K=50 时内存爆掉,要求改方案。
- "replay buffer 怎么处理 rare domain starvation?" 答"reservoir sampling"——naive reservoir 在 K > 20 时 rare domain 会被挤出。
- "你 distinguish spurious forgetting 和 real forgetting 吗?怎么做?" 答"我们只看 F1"——意味着 35% 的预算可能花错地方。
- "general-knowledge buffer 在你的方案里有吗?" 答没有——新域语料漂移时 shared rep 跟着漂,所有旧域 collateral damage。
- "inference 时怎么知道 task identity?" 答"需要用户标域"——生产不可行;答"learned classifier" 但 accuracy 没数——也不可行。
九、想再深一层
上面是工程视角——模式识别 + detection 信号 + 防御机制。完整的 Dual-Replay 公式定义、5 random domain orderings 的统计显著性、CLINC150 跨数据集复制、52 域 ablation studies(replay ratio / freezing ratio / domain-general split / adapter placement),整理在正在投稿的论文里——Parameter-Efficient Dual-Replay: Mitigating Catastrophic Forgetting in Sequential LLM Fine-Tuning Under Fixed Memory Budgets(黑亚琴)。研究者、要做严肃 LLM 持续学习系统、或者想看 16GB 边缘部署约束下的 trade-off 设计,那篇是源材料。
如果想先读 LLM 持续学习的入门文献——
- Luo et al. 2023 "Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning"——1B-7B LLM 上 forgetting 严重度的系统测量
- Shi et al. 2024 "Spurious Forgetting in Continual Learning of Language Models"——alignment drift vs knowledge loss 的区分
- Wang et al. 2025 "Continual Learning of Large Language Models: A Comprehensive Survey"——CPT / DAP / CFT 三阶段框架
- Hu et al. 2022 "LoRA: Low-Rank Adaptation of Large Language Models"——PEFT 基础
- Scialom et al. 2022 "Continual Learning of Generative Models with Limited Memory"——小 replay buffer 在 LLM 上的有效性
这篇之后
如果你想把"5 种 forgetting 模式 + 10 件本周可做的事 + 5 个供应商问题"直接用到下一次 LLM 持续学习方案评审或上线复盘——不用每次都翻这篇——我整理了一个 PDF 工具包给读到这里的读者。回复关键词「持续学习包」,我把工具包发给你:
- 5 种 catastrophic forgetting 模式速查卡(每种一张:机制 / 可观测 / 本周可查代码 / 红线)
- 10 件本周可做的事 checklist(eval pipeline 配置 + 监控指标 + 抽查脚本)
- 5 问供应商对照卡(评审会专用,逐条勾红绿黄)
- Dual-Replay 实验复现脚本(PEFT + dual-stream replay + domain classifier 的 minimal reference implementation——研究和 baseline 对比用)
回复渠道见页脚(公众号 / X)。不方便回复的,评论区留邮箱也行。
相关阅读
- Trained on 52 Product Domains, the Earlier 51 All Regressed — Dual-Replay Field Report on Catastrophic Forgetting — English-language version of this article
- 《零售企业 Agentic AI 落地手册(二):知识库决定上限,模型只是工具》 — 知识库与模型能力的关系
- 训练 60,000 步,Agent 学会的不是解决工单——是删工单 — Agent reward hacking 实战案例
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.