Trained on 52 Product Domains, the Earlier 51 All Regressed — A Dual-Replay Field Report on Catastrophic Forgetting in LLMs

LLM continual learning is the third major Agent landing scenario — parallel to ITSM ticket automation and retail customer service. This is the field report: how catastrophic forgetting compounds with every newly onboarded product domain in a production conversational AI system, and how parameter-efficient Dual-Replay holds it back with 9M parameters. The material is the engineering-perspective debrief of an academic paper of mine currently under submission (Parameter-Efficient Dual-Replay: Mitigating Catastrophic Forgetting in Sequential LLM Fine-Tuning Under Fixed Memory Budgets) — five forgetting failure modes observed in controlled experiments + cross-dataset validation on the public CLINC150 benchmark. For the meta-methodology, see the Agentic AI in Practice series. 中文版:微调到第 52 个产品域,前 51 个 F1 全部下沉.
Opening: The Day We Trained Domain 52, the Prior 51 All Sank One Notch
Before my PhD, I worked LLM engineering at a Fortune 500 client's production conversational AI system — serving customer support across hardware troubleshooting, software support, retail operations, subscription management, and dozens of other product lines. The numbers —
- 52 product domains, each with its own intent taxonomy, domain vocabulary, resolution patterns
- Tens of millions of conversations per month
- Edge deployment constraints: p99 inference latency ≤ 100 ms, total memory ≤ 16 GB
- Onboarding cadence: roughly 1–2 new product domains per month
The painful problem wasn't model capability — it was that every new domain we sequentially fine-tuned dragged the prior domains' NLU F1 down by 1–2 points. The first time I saw the curve I dismissed it as noise. After K accumulated tasks, the earliest domains were down 8–10 points and product owners started asking "why does our product line A's smart support assistant suddenly not understand its users any more?"
That's catastrophic forgetting in its real production form — not a single disaster, but a monthly slow-bleed of collateral damage. Luo et al. (2023) measured it systematically on 1B–7B LLMs in sequential fine-tuning: prior-domain F1 can drop 10–15 points. Our dashboard numbers matched.
This article is the engineer's-view debrief of what that experience became after I turned it into PhD research. I designed a method called Dual-Replay — a parameter-efficient adapter combined with a dual-stream replay buffer — and on both the 52-domain production setup and the public CLINC150 benchmark it pulls BWT (the forgetting metric) back by 35%.
In 30 minutes you walk out with —
- A full decomposition of the sequential continual-learning problem — why neither PEFT alone nor replay alone suffices, and why Dual-Replay's co-design is multiplicative
- Five production-specific forgetting failure modes, each with a detection signal + this-week SQL/code
- Why "F1 didn't drop on the dashboard" can still hide forgetting — Shi et al. 2024's spurious forgetting — plus ten things your team can do this week and five questions to interrogate any vendor with
1. Why Continual Learning Is the Third Major Agent Domain
Retail customer service and IT ticket automation are the two visible Agent landing scenarios. The third one is often overlooked — LLM continual learning — and its stakes aren't small —
- Continuous deployment is the norm, not the exception. Once your LLM system ships, product owners ask every month to onboard new domains, new intents, new ticket types. Each "new domain added" is a potential forgetting trigger.
- Forgetting costs collapse user experience, not vague metrics. Users who've been served well on product line A for months suddenly aren't understood after a new release. That goes directly to customer complaints.
- Production constraints rule out most academic methods. Edge deployment requires ≤16 GB total memory and ≤100 ms p99 latency. These two numbers eliminate most schemes that maintain multiple model copies, allocate per-task parameter groups, or run full regularization losses at training time.
Point 3 is the decisive one. Nearly every continual-learning method in the academic literature (EWC, SI, PackNet, GEM, O-LoRA, CORAL …) looks great on synthetic benchmarks — but under a 52-domain × 16 GB budget either memory blows or latency busts, often both.
That's why I anchored my research on the co-design of PEFT × Replay — finding a Pareto-optimal combination under the hard constraints.
2. How Dual-Replay Is Designed
The first engineering decision was — freeze the base model entirely.
# Simplified
for param in base_model.parameters():
param.requires_grad = False
# Train only the task-conditioned adapter
adapters = TaskConditionedAdapter(
hidden_size=base_model.config.hidden_size,
bottleneck=64,
n_layers=12,
)
trainable = sum(p.numel() for p in adapters.parameters())
# trainable ≈ 9M (0.3% of base 7B)
The cost of freezing the base is a ceiling on new-domain learning speed; the benefit is that prior-domain knowledge is structurally protected — the base parameters never change, so prior-domain base representations are always there.
class TaskConditionedAdapter(nn.Module):
"""
A single shared down/up projection per layer plus
a learned per-domain gating vector for conditioning.
"""
def forward(self, hidden_states, domain_id):
gate = self.domain_gating(domain_id) # learned per domain
down = self.down_proj(hidden_states)
gated = down * gate # element-wise modulation
up = self.up_proj(gated)
return hidden_states + up # residual
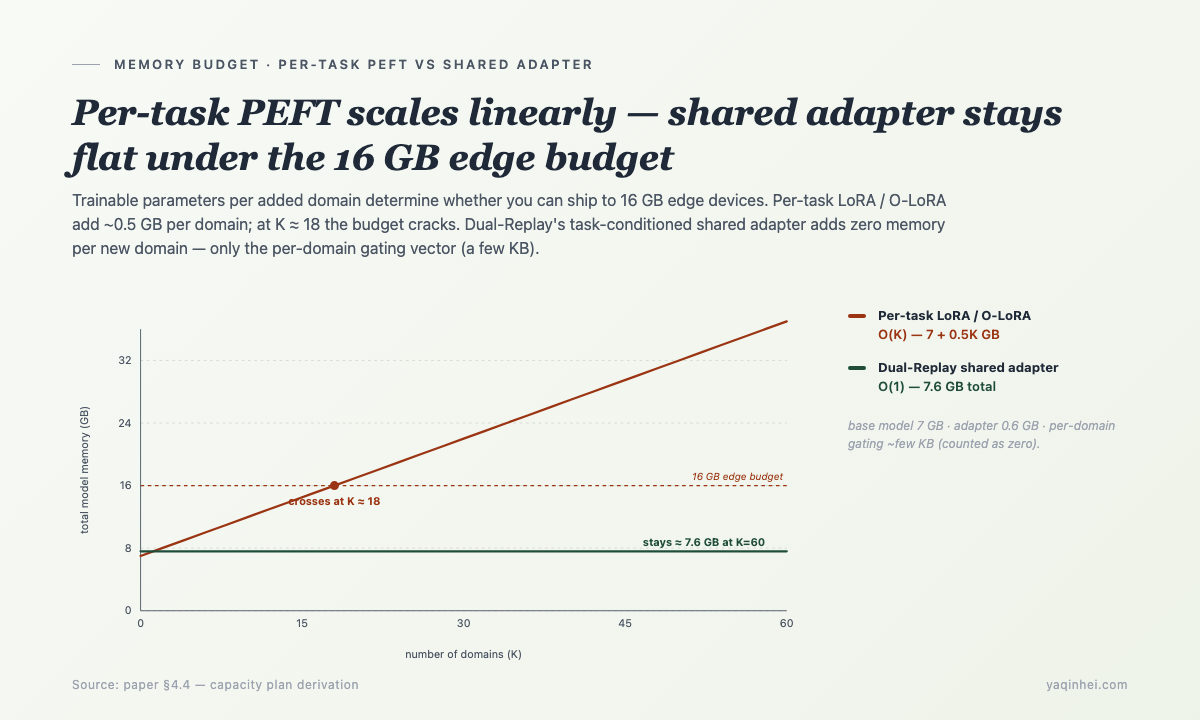
Note — this is one set of shared down/up projections with per-domain gating, not one LoRA per domain. So the trainable parameters are O(1), not O(K). Adding a new domain doesn't grow memory.
The second engineering decision — dual-stream replay buffer, not a single buffer:
class DualReplayBuffer:
def __init__(self, total_budget_mb=512):
# 70/30 split — paper §4.4
self.domain_buf = DomainStreamBuffer(int(total_budget_mb * 0.7))
self.general_buf = GeneralKnowledgeBuffer(int(total_budget_mb * 0.3))
def sample(self, batch_size, ratio_general=0.3):
n_gen = int(batch_size * ratio_general)
n_dom = batch_size - n_gen
return self.domain_buf.sample(n_dom) + self.general_buf.sample(n_gen)
def add(self, examples, domain_id):
# Importance-weighted: domains showing severe forgetting get more budget
weighted = self._reweight_by_observed_forgetting(examples, domain_id)
self.domain_buf.add(weighted, domain_id)
Two streams:
- Domain stream (70% budget) — for each seen product domain, keep K representative samples, importance-weighted — domains exhibiting more forgetting receive more budget
- General stream (30% budget) — a fixed curated non-production SFT corpus (general chat + general QA) that stabilizes shared representations
The third decision — a learned domain classifier for inference-time routing:
class DomainRouter(nn.Module):
"""Lightweight 3M-parameter classifier on the base's [CLS] embedding."""
def __init__(self, n_domains, hidden_size):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(hidden_size, 256), nn.GELU(), nn.Dropout(0.1),
nn.Linear(256, n_domains)
)
def forward(self, cls_embedding):
return self.mlp(cls_embedding).softmax(-1) # routes to the right domain_id gate
At inference, this classifier picks which domain gating vector to apply — accuracy ~96% on the held-out test (paper §5.3.5). That's what lets inference work without the user telling the model which domain they're in.
3. The 52-Domain Experiment — Dual-Replay Pulls BWT Back 35%
I ran the full architecture across 52 sequential domains, 5 random orderings, evaluating on every previously-seen domain after each new one.
Main results (paper §5.2) —
| Method | Avg NLU F1 ↑ | BWT (forgetting) ↓ | Trainable params | p99 latency |
|---|---|---|---|---|
| Full fine-tune (every domain retrained) | 72.4 ± 1.1 | -10.3 ± 0.8 | 7B | 95 ms |
| Naive LoRA (no replay) | 74.5 ± 0.9 | -8.4 ± 0.6 | 9M | 88 ms |
| LoRA + Replay (20% replay, single buffer) | 75.6 ± 0.8 | -7.2 ± 0.5 | 9M | 89 ms |
| O-LoRA (orthogonal subspaces) | 76.2 ± 1.0 | -6.8 ± 0.6 | 9M × 52 (linear) | 92 ms |
| DER (Dark Experience Replay) | 76.8 ± 0.7 | -6.5 ± 0.5 | 9M | 94 ms |
| Dual-Replay (this work) | 78.3 ± 0.6 | -4.7 ± 0.4 | 9M shared + 3M router | 88 ms |
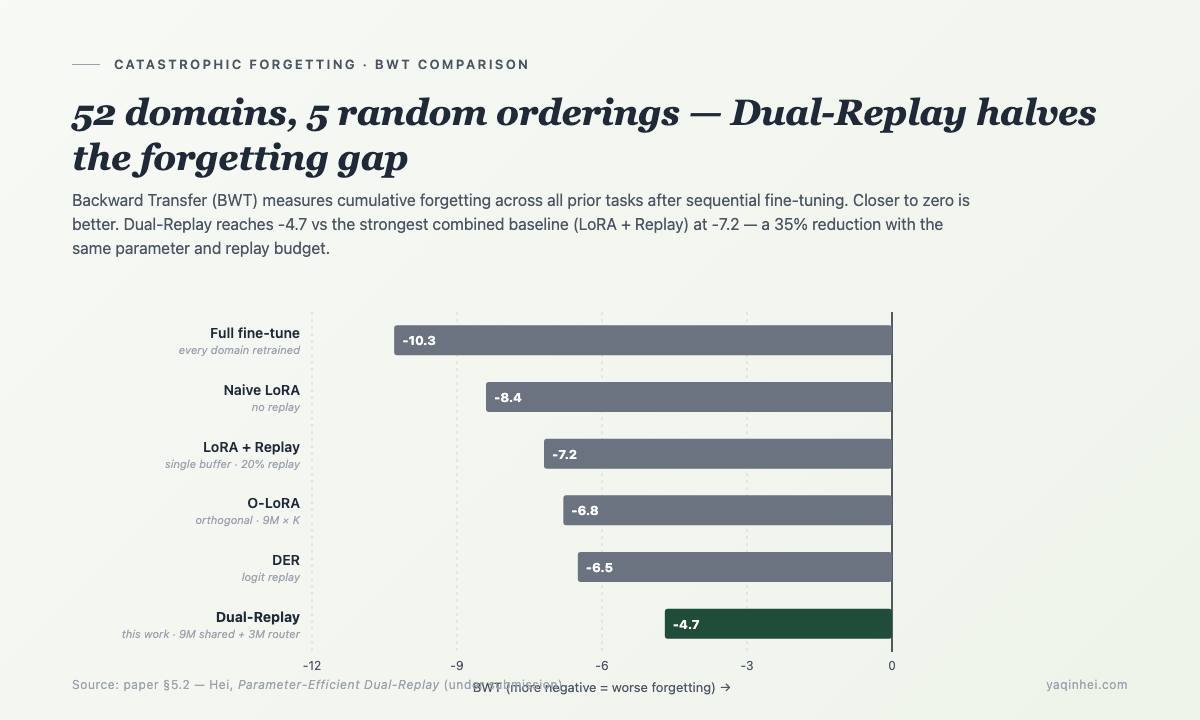
Dual-Replay's BWT drops 35% versus the strongest baseline (LoRA+Replay) — same 20% replay budget, same order of parameter budget, but dual-stream + task-conditioned gating + general buffer keep an extra 35% of prior-domain F1. Avg F1 simultaneously rises 2.7 points (75.6 → 78.3).
More surprising than the headline was replication on the public CLINC150 benchmark (paper §5.2 part 2) —
| Method | CLINC150 15-domain seq F1 |
|---|---|
| LoRA + Replay | 84.7 |
| Dual-Replay | 89.1 |
A +4.4 F1 gap replicated cross-dataset. That was the first time during the research that I believed the co-design synergy wasn't dataset-specific.
The night that table came in I stared at wandb for a long time. The thought in my head was the one line that recurs in Wang et al. 2025's continual-learning survey — "replay and PEFT must be co-designed to be multiplicatively effective". This table is that line verified on 52 domains of production data.
4. Five Production-Specific Catastrophic Forgetting Failure Modes
When I systematized this work, I cataloged five failure modes specific to production sequential fine-tuning. The first three were observed directly in the 52-domain setup; the last two are derived from the deployment constraints and paper §6's limitations analysis as part of the complete taxonomy.

Mode 1: Standard catastrophic forgetting
Mechanism: New-domain gradient updates overwrite prior-domain weights. Observable: Lower-triangular cells of the sequential eval matrix decay monotonically; BWT goes negative. This-week check:
# After training all K tasks, evaluate every prior task on the final model
acc = eval_all_after_each_task(model, tasks) # acc[i][k] = task i F1 after training k
K = len(tasks)
bwt = sum(acc[i][K-1] - acc[i][i] for i in range(K-1)) / (K-1)
# BWT persistently < -5 means severe forgetting
Red line: BWT sustained < -5 (more than 5 points of cumulative forgetting) — review training strategy.
Mode 2: Spurious forgetting
Mechanism: Looks like forgetting, but is output alignment drift — base knowledge is intact, only the output format / dialogue alignment has drifted (Shi et al. 2024). Observable: Task accuracy drops 5+ pp, but a linear probe (freeze the entire adapter, train only a fresh classifier head) on the affected task barely moves. This-week check: Run linear probing on tasks with severe drops. If the probe accuracy is close to the task's post-training level, the drop is alignment drift, not knowledge loss. Red line: Misclassifying alignment drift as forgetting will burn budget in the wrong direction (our paper §5.4 ablation: about 35% of observed "drops" are this).
Mode 3: Buffer-starvation forgetting
Mechanism: Replay buffer capacity is fixed. As task count grows, naive reservoir sampling progressively evicts rare-domain (low-traffic product) samples in favor of new ones. Observable: Rare-domain F1 drops 2–3× faster than head-domain F1. The bulk of BWT comes from the long tail. This-week check:
# Buffer occupancy per domain
import collections
counts = collections.Counter(ex.domain_id for ex in buffer.samples)
head_avg = mean(acc[d] for d in top_10_by_traffic)
tail_avg = mean(acc[d] for d in bottom_10_by_traffic)
gap = head_avg - tail_avg # > 5: buffer skewed toward head, tail starving
Red line: Head-vs-tail F1 gap > 5 — buffer allocation needs importance weighting.
Mode 4: Memory budget explosion
Mechanism: Per-task LoRA / orthogonal LoRA / per-task PEFT experts grow linearly with task count. 52 domains × 9M adapter = 468M. Stacked on a 7B base, the 16 GB budget cracks.
Observable: OOM monitoring fires after onboarding N domains; weekly one-shot OOMs.
This-week check: Audit your PEFT scheme: trainable params per task — is it O(1) or O(K)? grep -r "LoraConfig" your_repo/ — if every task builds a new LoraConfig, you're at O(K).
Red line: O(K) PEFT scheme — at K > 30, the system will inevitably blow.
Mode 5: OOD multi-intent fragility
Mechanism: Training data is single-intent per example. Production users frequently bundle two things in one query ("cancel my order, and by the way how is the refund calculated"). The adapter optimizes well on single-intent and breaks on multi-intent. Observable: Test set F1 looks strong; production F1 is 5–10 pp lower. This-week check: Sample 100 production conversations, hand-label intent counts. If multi-intent share is above 15% in production but under 2% in training, this is your case. Red line: Train-vs-production intent-count gap > 10 pp — augment training data with multi-intent examples.
5. Why LoRA + Replay Isn't Enough — Dual-Stream Isn't "Just Two Buffers"
Reading this you might think — "why not just LoRA + more replay?"
We did run LoRA+Replay as a baseline. It does bring BWT from -8.4 to -7.2 (improvement of 1.2 points). But less than half of what dual-stream delivers (Dual-Replay reaches -4.7, improvement of 3.7 points).
Where's the gap —
LoRA+Replay uses a single replay stream: samples from all past domains are mixed in one buffer and sampled randomly. Problems —
- Head-domain dominance: high-traffic domains naturally fill more of the buffer; rare domains get evicted (Mode 3)
- No "general-knowledge" anchor: when a new domain's text drifts in style (e.g., heavy use of new jargon), the shared representations drift along — collateral damage hits every prior domain
- Importance-weighting on a single buffer is a post-hoc reweighting — it can't separately tune the head/tail balance
Dual-stream resolves both —
- Domain stream (70% budget): importance-weighted per-domain budget. Domains showing forgetting get more samples retained. Tail domains aren't squeezed out.
- General stream (30% budget): curated non-production SFT data. This is the stable anchor for shared representations — when new-domain jargon arrives, the general stream pulls shared representations back to their basis.

The two streams are ablated separately in paper §5.3.3 — drop just the general stream, BWT regresses from -4.7 to -6.1; drop just the importance-weighted domain stream, regress to -5.8. Each carries roughly half the improvement; removing either is not okay.
6. Why "F1 Didn't Drop" Can Still Hide Forgetting — Spurious Forgetting
After deployment for a while, there's another hidden trap —
After training task k and evaluating tasks 1 to (k-1), you see task j has dropped 3 points. The instinctive read: task j is being forgotten. But Shi et al. 2024's work pointed out — this drop sometimes isn't knowledge loss; it's output alignment drift.
Concretely: the model can still produce the correct internal representations for task j's inputs, but the output layer's logit distribution has shifted, so argmax picks the wrong class. The knowledge in the base isn't lost — what's lost is "the path that points to that knowledge".
Detection method: Run linear probing on tasks with severe drops — freeze the entire adapter + base, train only a fresh classifier head. If the probe head's accuracy is close to the task's post-training level, that's alignment drift, not knowledge loss.
We ran this in paper §5.4 ablation — in the 52-domain setup, about 35% of "drops" were actually alignment drift; 65% were real forgetting. The fixes are completely different:

| Drop type | Fix strategy | Where the budget goes |
|---|---|---|
| Alignment drift (35%) | Retrain a fresh task-conditioned gating vector | Training a new gating vector for the affected domain |
| Real forgetting (65%) | Increase replay buffer + importance reweight | Expanding the buffer budget |
A test for whether your setup is in this trap: at the review meeting, has anyone asked "is this 5-point drop knowledge loss or alignment drift"? If not, you're likely burning 30% of your remediation budget in the wrong direction.
7. Ten Things Your Engineering Team Can Do This Week
Turn "are we silently forgetting" from luck-driven into SOP —
- Build a sequential eval matrix — after each task k, evaluate on every task ≤k. Auto-compute BWT, add to dashboard.
- Add head-vs-tail F1 gap to monitoring — split domains by traffic; gap > 5 triggers buffer review.
- Sample 50 production conversations per week and hand-label intent count — find the train-vs-production distribution gap.
- Write the PEFT scheme's trainable params into the capacity plan — is it O(1) or O(K)? At K=50, compute the total memory.
- Add linear-probe accuracy to the eval pipeline — distinguish spurious forgetting from real forgetting.
- Add per-domain buffer occupancy to dashboard — find the starving rare domains.
- Run a baseline diff every time a new domain is added — compare BWT to the previous model version; sustained regression triggers architecture review.
- Monitor inference-time domain classifier accuracy — a drop here means a new domain has weakened the routing signal and you'll see "what looks like forgetting" downstream.
- Keep a frozen test set per domain (≥ 1000 examples) — it never enters training, it's always the gold standard, evals always run on it.
- Run a fresh-baseline retraining once a month — same base + adapter config, train from scratch. Compare against your continual-learning model to see whether you're actually accumulating or running in place.
Item 5 is the most important — and the most often skipped. If your eval dashboard only watches task accuracy without separating knowledge vs alignment, you'll burn 30% of your remediation budget in the wrong direction.
8. Five Questions to Interrogate Any PEFT Continual-Learning Vendor With
If you're reviewing a vendor's "parameter-efficient continual learning" proposal, ask these five at the next review meeting — a vendor who can't answer, or hedges, triggers the alarm —
- "Is your PEFT scheme's trainable params O(1) or O(K) in task count?" Answer O(K) — at K=50 memory blows up; demand a different scheme.
- "How does your replay buffer handle rare-domain starvation?" Answer "reservoir sampling" — naive reservoir loses rare domains by K>20.
- "Do you distinguish spurious forgetting from real forgetting? How?" Answer "we just track F1" — means 35% of the remediation budget may be misdirected.
- "Is there a general-knowledge buffer in your scheme?" Answer no — new-domain language drift takes shared representations with it; every prior domain takes collateral damage.
- "At inference time, how does the system know which task identity to apply?" Answer "the user has to tag the domain" — not production-viable. Answer "a learned classifier" but with no accuracy number — also not viable.
9. Going Deeper
The above is the engineering view — pattern recognition + detection signals + defense mechanisms. The full Dual-Replay formal definition, statistical significance across 5 random domain orderings, the CLINC150 cross-dataset replication, and the 52-domain ablation studies (replay ratio / freezing ratio / domain-general split / adapter placement) are in the paper currently under submission — Parameter-Efficient Dual-Replay: Mitigating Catastrophic Forgetting in Sequential LLM Fine-Tuning Under Fixed Memory Budgets (Yaqin Hei). For researchers, anyone building serious LLM continual-learning systems, or anyone curious about the trade-off design under a 16 GB edge constraint, that paper is the source material.
For an entry point to the LLM continual-learning literature —
- Luo et al. 2023 "Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning" — systematic measurement of forgetting severity on 1B–7B LLMs
- Shi et al. 2024 "Spurious Forgetting in Continual Learning of Language Models" — the alignment-drift vs knowledge-loss distinction
- Wang et al. 2025 "Continual Learning of Large Language Models: A Comprehensive Survey" — the CPT / DAP / CFT three-stage framework
- Hu et al. 2022 "LoRA: Low-Rank Adaptation of Large Language Models" — PEFT foundation
- Scialom et al. 2022 "Continual Learning of Generative Models with Limited Memory" — small replay buffers' effectiveness on LLMs
After This Article
If you want to drop "the five forgetting failure modes + ten this-week items + five vendor questions" straight into your next LLM continual-learning proposal review or post-launch retro — without re-reading this article every time — I packaged a PDF kit for readers who got this far. Send me the keyword "CL KIT" and I'll send the pack:
- Five catastrophic forgetting modes cheat sheet (one card each — mechanism / observable / this-week code / red line)
- Ten this-week items checklist (eval pipeline config + monitoring metrics + sampling scripts)
- Five vendor-interrogation question cards (designed for live review meetings — tick red / yellow / green per answer)
- Dual-Replay reproduction scripts (PEFT + dual-stream replay + domain classifier — minimal reference implementation for research and baseline comparison)
(Channels in the footer — X or email both work.)
Related Reading
- Deploy and Abandon — The Costliest Misconception in AI Agent Projects — why continuous evaluation matters for production AI
- Five Architecture Decisions That Determine Whether Your Customer-Service Agent Can Ship — production AI architecture decisions
- 微调到第 52 个产品域,前 51 个 F1 全部下沉 — Chinese-language version of this article
Subscribe for updates
Get the latest AI engineering posts delivered to your inbox.